XML&Dom4j
1.XML概述
什么是XML
- 英文:Extensible Markup Language 可扩展的标记语言,由各种标记(标签==元素)组成。
- 可扩展:所有的标签都是自定义的,可以随意扩展的。如:
<abc/>,<hobby>,<sex> - 标记语言:整个文档由各种标签组成。清晰,数据结构化!
- XML是通用格式标准,全球所有的技术人员都知道这个东西,都可能会按照XML的规范存储数据,交互数据!!
XML作用
1) 数据交换:不同的计算机语言之间,不同的操作系统之间,不同的数据库之间,进行数据交换。
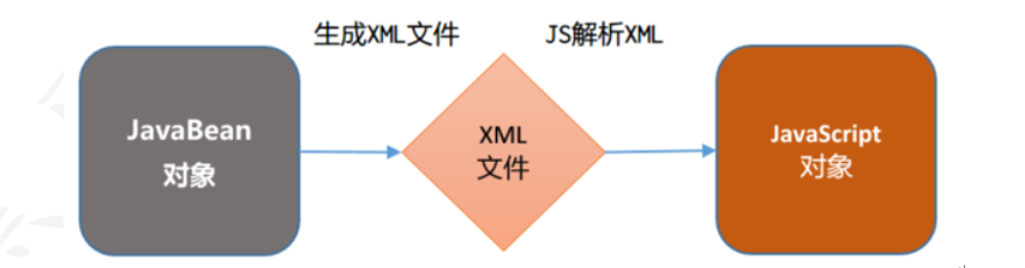
2) 配置文件:在后期我们主要用于各种框架的配置文件。

XML的特点
- 用于数据交互,用于数据的存储,**用于做系统的配置文件
- 区分大小写
- 非常严谨,只要有错误,解析器就不能解析
- 可以扩展的,所有的标签都是程序员自己创建出来。
- XML文件的后缀为.xml
2.XML的组成:声明和元素
XML由七种组成元素构成:
- 声明(抬头)
- 元素(标签)
- 属性
- 注释
- 实体字符
- CDATA 字符数据区
- 处理指令
文档声明
语法

声明的三种属性
| 文档声明的三个属性 | 说明 |
|---|---|
| version | 指定XML文件使用的版本,取值是1.0 |
| encoding | 当前XML文件使用的编码(字符集) |
| standalone | 指定当前这个XML文件是否是一个独立的文件,省略的,默认是独立文件。 |
版本说明
W3C 在1988年2月发布1.0版本,2004年2月又发布1.1版本,因为1.1版本不能向下兼容1.0版本,所以1.1没有人用。在2004年2月W3C又发布了1.0版本的第三版。我们学习的还是1.0版本。
元素

代码
<?xml version="1.0" encoding="UTF-8" ?>
<persons>
<!--描述一个人-->
<person id="1">
<name>张三</name>
<age>18</age>
<sex>男</sex>
</person>
<person id="2">
<name>李四</name>
<age>19</age>
<sex>女</sex>
</person>
</persons>小结
- 声明有哪两个常用的属性? version encoding
- 一个XML有几个根元素? 1个
- XML标签命名不能有什么符号? 空格,冒号
3.XML的组成:属性、注释和实体字符
- XML文档中属性
- XML文档中的注释
- XML文档中实体字符
属性的语法

注释

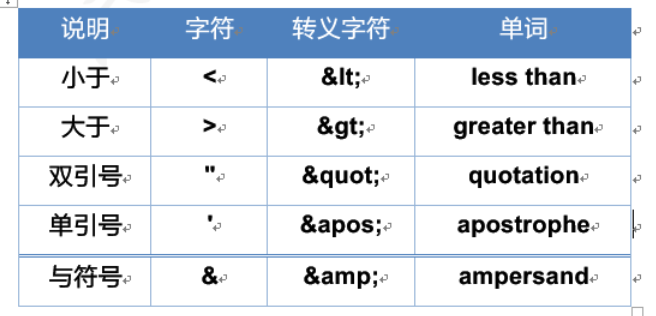
实体字符
XML中的实体字符与HTML一样。因为很多符号已经被文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用实体字符
- 语法:
应用案例
需求
有一个\
效果
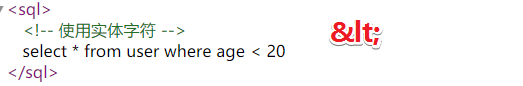
错误写法
<sql>
<!--使用实体字符-->
select * from user where age < 20
</sql>正确写法
<sql>
<!--使用实体字符-->
select * from user where age < 20
</sql>小结
-
属性必须出现在标签哪个位置,同一个标签是否可以有同名的属性?
只能写在开始标签里面,不可以
-
为什么要有实体字符?
因为> 或者 < 与XML文件本身的规范冲突,必须用实体字符代替!!才不会报错!!
4.XML的组成:字符数据区和处理指令
为什么要字符数据区
如果大量使用实体字符,会导致XML可读性降低。另一种解决方案:可以使用字符数据区包裹这些字符,只要在字符数据区中的内容,XML解析器会纯文本进行解析。

处理指令

代码
person.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/css" href="person.css" ?>
<persons>
<!--描述一个人-->
<person id="1" vip="true">
<name>张三</name>
<age>18</age>
<sex>男</sex>
</person>
<person id="2">
<name>李四</name>
<age>19</age>
<sex>女</sex>
</person>
<sql>
<!--使用实体字符-->
select * from user where age < 20
</sql>
<sql>
<![CDATA[
select * from user where age < 20
]]>
</sql>
</persons>person.css
name {
font-size: 30px;
color: red;
}
age {
font-size: 25px;
color: blue;
}
使用处理指令
<?xml-stylesheet type="text/css" href="person.css" ?>效果

小结
7个组成部分:
-
声明
-
元素
张三 18 男 唱歌,跳舞 -
属性
-
注释
-
实体字符
select * from user where age < 18 && age > 5 -
CDATA字符数据区
= 5 ]]> -
处理指令
做界面效果,没啥用!!
一个格式良好的XML有以下特点
- 必须以XML声明开头
- 必须拥有唯一的根元素
- 开始标签必须与结束标签相匹配
- 元素对大小写敏感
- 所有的元素必须关闭
- 所有的元素必须正确地嵌套
- 特殊字符必须使用实体字符或使用字符数据区
5. XML约束:DTD约束
XML为什么要有约束
因为XML文件的标签和属性可以随意扩展,有时我们必须要限制每个文档有哪些元素,每个元素有哪些子元素,每个元素有哪些属性,属性的值是什么类型等。从而保证XML文档格式和数据的正确性和规范性。为了XML的定义有规范。
XML的两种约束
-
DTD约束
-
Schema约束(是最牛的约束技术,最重要的)
我们只要能懂就好了,以后约束文件都是框架写好的。我们会用即可!
DTD约束的概念
- DTD: Document Type Definiation 文档类型定义
- 作用:纯文本文件,指定了XML约束规则。
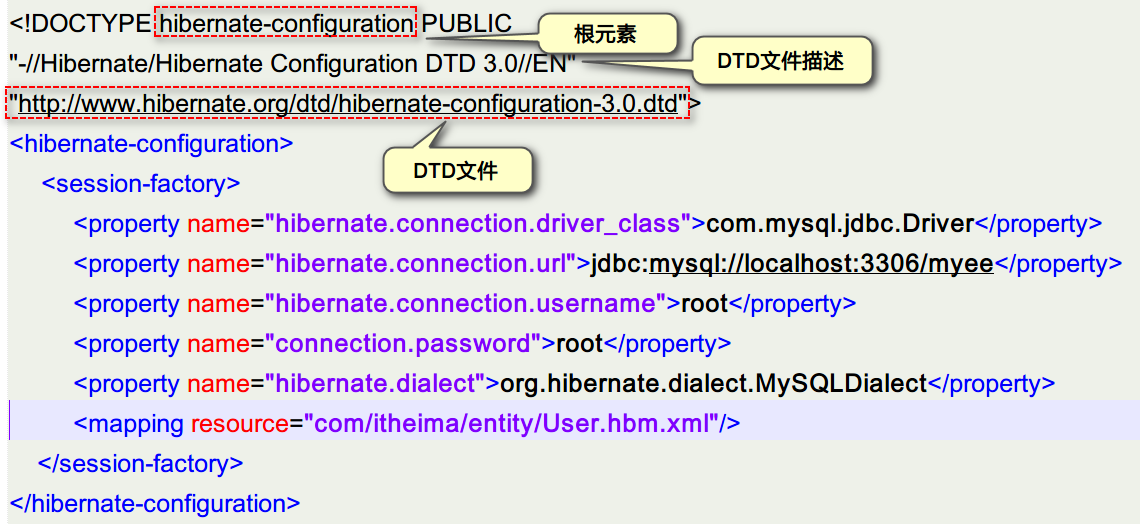
| 导入DTD文件的两种格式 | 说明 |
|---|---|
| <!DOCTYPE 根元素 SYSTEM "DTD文件"> | 系统DTD文件,通常个人或公司内部使用 |
| <!DOCTYPE 根元素 PUBLIC "文件描述" "DTD文件"> | 公有的DTD文件,在互联网上广泛使用的DTD |
如:hibernate框架的导入方式
DTD使用案例
步骤1:新建bookshelf.dtd文件,选择项目鼠标右键“NEW->File",文件名为“bookshelf.dtd”
步骤2:bookshelf.dtd文件内容如下
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>步骤3:新建books.xml,代码如下
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE 书架 SYSTEM "bookshelf.dtd">
<书架>
<书>
<书名>JavaEE SSM</书名>
<作者>NewBoy</作者>
<售价>30</售价>
</书>
<书>
<书名>人鬼情喂鸟</书名>
<作者>李四</作者>
<售价>300</售价>
</书>
</书架>DTD学习要求
在企业实际开发中,不会自己编写DTD约束文档,我们后期只需通过框架提供的DTD约束文档编写出相应的XML配置文档。只要会导入别人的DTD约束自己即可。
小结
- DTD是一个什么文件? XML的约束文件
- 它的作用是什么? 约束XML文件格式的规范性!!
6.XML约束:Schema约束
为什么要有Schema约束
DTD的不足:
- 不能验证数据类型
- 因为DTD是一个文本文件,本身不能验证是否正确。

约束文件扩展名(XML Schema Definition)XML模式定义:xsd
约束文件本身也是XML文件,所以也有根元素,根元素的名字叫:schema
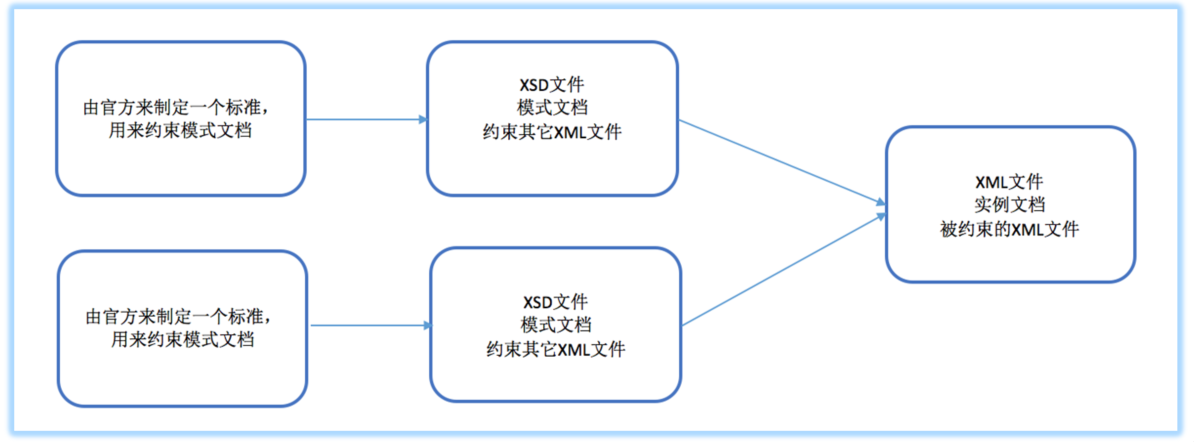
模式文档和实例文档
模式文档:制定约束的XML文档(类似于:类)。Schema
实例文档:被约束的XML文档(类似于:对象)。
命名空间
问:如果在Java中如果使用同名的类,如何避免冲突?比如:Date类,在java.util和java.sql包中都有
import java.sql.Date;
//import java.util.Date;
public class Demo1 {
public static void main(String[] args) {
//sql的类,Date日期
Date d1 = new Date(System.currentTimeMillis());
System.out.println(d1);
//utils中类,Date
java.util.Date d2 = new java.util.Date();
System.out.println(d2);
}
}如何不同的xsd约束文件出现同名的标签,如何避免冲突?
使用命名空间,在XML中使用URL地址来命名
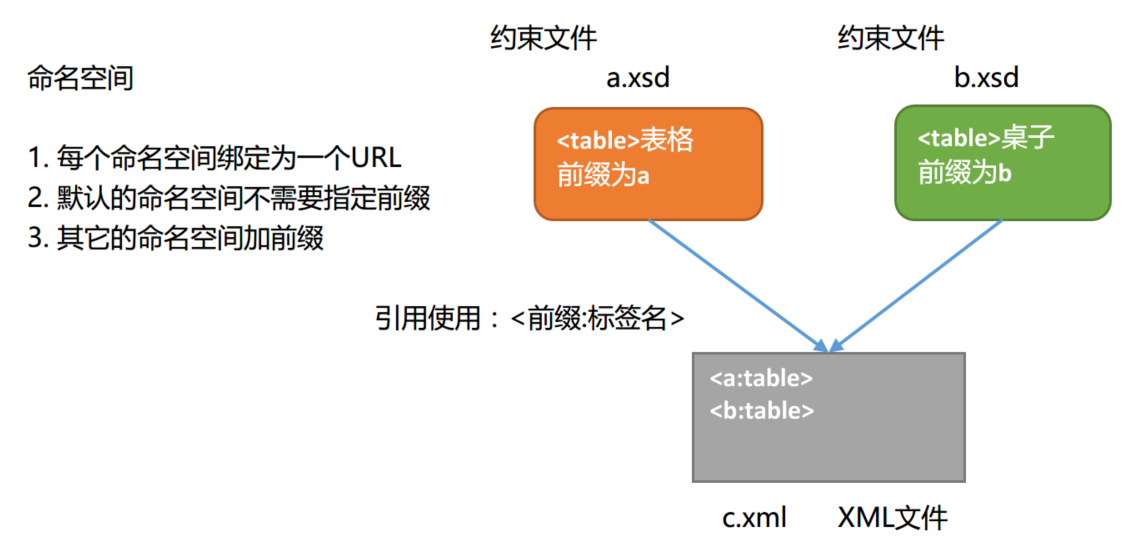
- 一个XML文件可以有多个约束文件
- targetNamespace用来指定默认的命名空间(约束文件的地址)
- 默认命名空间,前面不需要指定前缀,直接使用<标签名>
- 一个XML文档中只能有一个默认的命名空间
- 其它命名空间中的标签,使用\<前缀:标签名>来引用
Schema演示案例
- 步骤1:新建schema约束文件bookshelf.xsd,对售价约束数据类型,代码如下:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.github.com/krislinzhao"
>
<xs:element name='书架'>
<xs:complexType>
<xs:sequence maxOccurs='unbounded'>
<xs:element name='书'>
<xs:complexType>
<xs:sequence>
<xs:element name='书名' type='xs:string'/>
<xs:element name='作者' type='xs:string'/>
<xs:element name='售价' type='xs:double'/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>- 步骤2:新建books2.xml使用schema约束文件
<根元素 xmlns="命名空间" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="命名空间 xsd约束文件名">
</根元素>book2.xml
<?xml version="1.0" encoding="UTF-8" ?>
<书架 xmlns="http://www.github.com/krislinzhao" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.github.com/krislinzhao bookshelf.xsd"
>
<书>
<书名>JavaEE</书名>
<作者>张三</作者>
<售价>39</售价>
</书>
<it:书>
<书名>西游记</书名>
<作者>吴承恩</作者>
<售价>3000</售价>
</it:书>
</书架>Schema学习要求
虽然schema功能比dtd强大,但是编写要比DTD复杂,同样以后我们在企业开发中也很少会自己编写schema文件。我们只需要借助开发工具,在现有的xsd约束下,写出正确的xml文件即可。
小结
- XML有哪两种约束?
- DTD
- Schema
- Schema约束相比DTD有哪些优点?
- Schema本身是一个XML文件,更严谨。
- 可以验证数据类型
- 一个XML文件可以有多个xsd约束文件,要使用前缀来引用。
7.XML的两种解析方式
什么是XML的解析
使用Java语言去解析XML文件,读取XML中的元素,属性,文本等数据就是XML解析。
解析方式和解析器
两种解析方式
- DOM解析 Document Object Model 文档对象模型(面向对象的解析方式)
- 优点:将整个XML文件加载到内存中,生成一棵DOM树。随意访问树上任何一个节点,可以修改和删除节点,程序开发比较方便。纯面向对象开发。
- 缺点:占内存,如果XML文件很大,可能出现内存溢出。
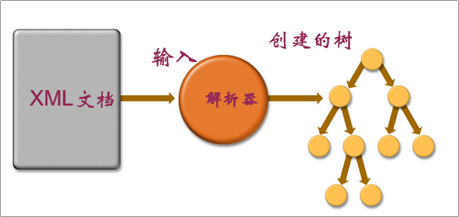
- SAX解析
- 优点:事件驱动型解析方式,读取一行就解析一行,释放内存。理论上可以解析任意大小的XML文件。
- 缺点:使用过的元素不能再访问了,不能修改元素,只能查找。
Java中DOM解析开发包

小结
有哪两种XML的解析方式:
-
DOM
思想:一次性把XML加载到内存中,称为Dom树,然后操作解析它。占内存。
- JAXP
- JDOM
- Dom4J(第三方公司研发的,性能优于JDOM,代码简单,高度面向对象)
- Jsoup
-
SAX
- 一行一行的解析XML文件,基于事件驱动。
8.XML文档生成DOM树原理
介绍
XML DOM 和 HTML DOM一样,XML DOM 将整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作。以下面books.xml文档为例。
XML文件
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>XML文件==document文档对象树== DOM树
生成的DOM树
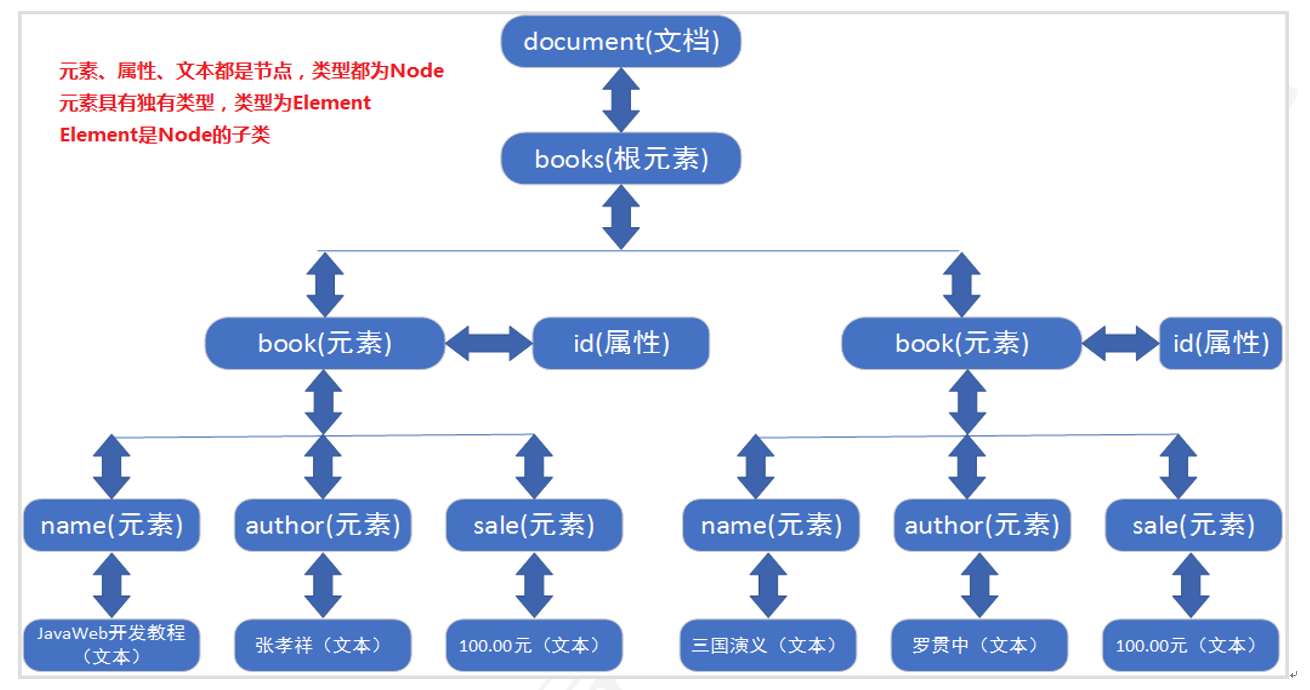
由于DOM方式解析XML文档所有都是节点Node,所有节点又都被封装到Document对象中,所以解析的重点就是获取Document对象。
DOM4j中DOM树的API
| 组成 | 说明 |
|---|---|
| Document | 当前解析的XML文档对象 |
| Node | XML中节点,它是其它所有节点对象的父接口 |
| Element | 代表一个元素(标签) |
| Attribute | 代表一个属性 |
| Text | 代表标签中文本 |
小结
DOM的解析原理:
- 将整个XML文件加载到内存中,生成一棵DOM树,下面是根节点。
- 通过Document对象来访问整个DOM树的节点和对应的数据!
9.dom4j: 获取Document对象和根元素
导入dom4j的步骤
-
去官网下载 zip 包。http://www.dom4j.org/

-
在项目中创建一个文件夹:lib
-
将dom4j-2.1.1.jar文件复制到 lib 文件夹
-
在jar文件上点右键,选择 Add as Library -> 点击OK
-
在类中导包使用
得到Document对象
步骤
文件Contact.xml放在src目录下
- 创建一个SAXReader对象,用于读取 xml 文件。
- 从类路径下加载xml文件,得到输入流对象
- 通过 SAXReader对象的read(InputStream in )方法,从输入流中读取,生成文档对象。
代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
/**
1. 得到文档对象
2. 得到根元素
*/
public class Demo3Document {
public static void main(String[] args) throws FileNotFoundException, DocumentException {
//1. 创建类: 读取XML文件
SAXReader reader = new SAXReader();
//不建议这么写
//FileInputStream in = new FileInputStream("D:\\IdeaWork\\JavaEE105\\day23-xml\\src\\Contacts.xml");
//src目录就是编译以后的类路径,从类路径下得到输入。
InputStream in = Demo3Document.class.getResourceAsStream("/Contacts.xml");
//2.通过reader来读取xml, 生成了一个document对象
Document document = reader.read(in);
//3. 输出文档
System.out.println(document);
//4. 得到文档以后,通过文档得到根元素
Element rootElement = document.getRootElement();
System.out.println(rootElement);
}
}Document常用方法

小结
- 如何得到Document对象
- 创建SaxReader
- 从类路径下得到InputStream
- 通过SaxReader来读取字节输入流,得到Document对象
- 通过Document对象得到根元素
- 调用哪个方法得到根元素:getRootElement()
10.dom4j:获取元素对象Element
什么是Element
就是元素对象,即标签。
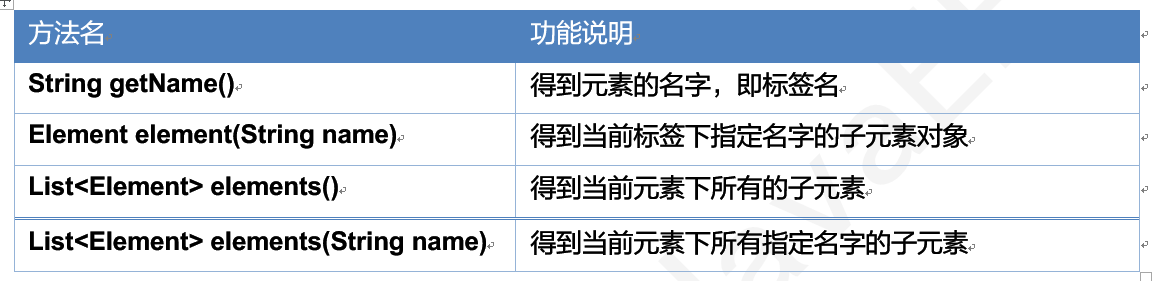
Element常用方法
元素使用的案例
需求
元素方法的使用,得到contact下所有的子元素,并且输出元素名
步骤
- 得到SAXReader对象
- 得到Document对象
- 得到根元素
- 得到contact元素
- 得到contact下所有的子元素,并输出子元素的名字
代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.InputStream;
import java.util.List;
/**
元素方法的使用
*/
public class Demo3Element {
public static void main(String[] args) throws DocumentException {
//1. 得到SAXReader对象
SAXReader reader = new SAXReader();
InputStream in = Demo3Element.class.getResourceAsStream("/Contacts.xml");
//2. 得到Document对象
Document document = reader.read(in);
//3. 得到根元素
Element rootElement = document.getRootElement();
//4. 得到contact元素
Element contact = rootElement.element("contact");
//System.out.println(contact);
//5. 得到contact下所有的子元素,并输出子元素的名字
List<Element> elements = contact.elements();
for (Element element : elements) {
//只输出标签名
System.out.println(element.getName());
}
}
}
小结
| 方法名 | 功能说明 |
|---|---|
| String getName() | 得到标签名字 |
| Element element(String name) | 得到当前元素下指定名字的子元素 |
| List\ |
得到当前元素下所有子元素 |
| List\ |
得到当前元素下指定名字的子元素返回集合 |
11.dom4j: 属性对象Attribute
什么是Attribute对象
代表一个标签的属性,如:id="1"
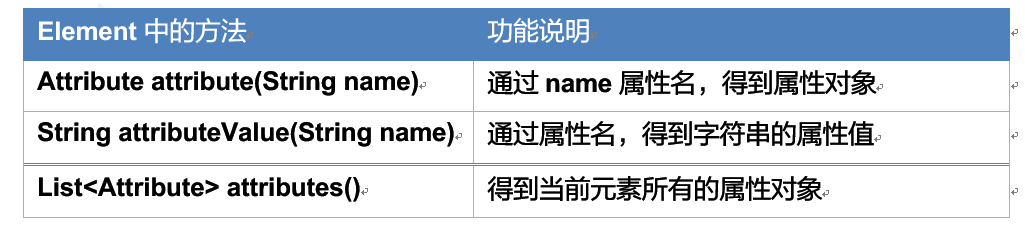
Element中与属性相关方法
得到属性的前提是:先得到元素。属于必须存在于元素中,没有元素谈何属性呢?
Attribute常用方法
得到属性值的两种方式
- 先得到Attribute对象,再通过Attribute对象得到属性的值
- 通过方法attributeValue()直接得到属性值
属性的案例
需求
- 使用2种方式,得到contact上id属性值
- 在contact元素上添加一个vip的属性值为true/false,得到contact上所有的属性名和属性值
效果
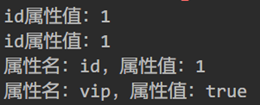
步骤
- 创建SAXReader
- 调用read 方法,读取 xml 文件
- 得到根元素
- 获得第1个contact元素对象
- 通过方式1:得到contact上id属性值
- 通过方式2:得到contact上id属性值
- 得到contact上所有的属性名和属性值
代码
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
public class Demo4Attribute {
public static void main(String[] args) throws DocumentException {
//1. 创建SAXReader
SAXReader reader = new SAXReader();
//2. 调用read 方法,读取 xml 文件
Document document = reader.read(Demo4Attribute.class.getResourceAsStream("/Contacts.xml"));
//3. 得到根元素
Element rootElement = document.getRootElement();
//4. 获得第1个contact元素对象
Element contact = rootElement.element("contact");
//5. 通过方式1:得到contact上id属性值
Attribute idAttr = contact.attribute("id");
String idValue = idAttr.getValue();
System.out.println(idValue);
//6. 通过方式2:得到contact上id属性值
String id = contact.attributeValue("id");
System.out.println(id);
//7. 得到contact上所有的属性名和属性值
List<Attribute> attributes = contact.attributes();
for (Attribute attribute : attributes) {
System.out.println("属性名:" + attribute.getName());
System.out.println("属性值:" + attribute.getValue());
}
}
}小结
| Element中的方法 | 功能说明 |
|---|---|
| Attribute attribute(String name) | 通过属性名得到属性对象 |
| String attributeValue(String name) | 通过属性名直接得到属性值 |
| List\ |
得到当前元素所有的属性对象 |
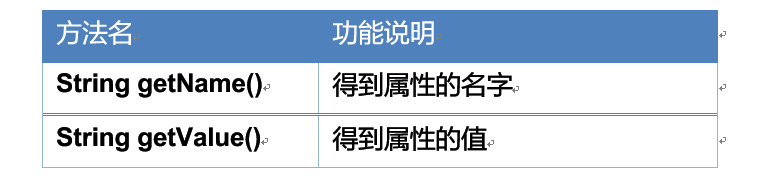
Attribute对象的方法
- String getName():取属性对象的名字。
- String getValue : 取属性对象的值。
12.dom4j: 获取文本内容
文本内容
得到文本元素的前提:先得到元素对象
- 注:空格、换行、制表符:也是属于文本的一部分,所以在解析xml文件的时候,格式化XML文件要注意。
元素中得到文本有关的方法

案例:对文本的操作
需求
得到第1个contact中的name元素,输出name元素的文本。分别通过下面三个方法得到:
- 通过getText()方法得到
- 直接得到元素的内容
- 得到去掉空格的文本
步骤
- 得到Document对象
- 得到根元素
- 得到contact标签
- 得到name标签中的文本
- 得到name标签
- 再得到name中的文本
代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
得到文本内容
*/
public class Demo5Text {
public static void main(String[] args) throws DocumentException {
//1. 创建SAXReader
SAXReader reader = new SAXReader();
//2. 调用read 方法,读取 xml 文件
Document document = reader.read(Demo5Text.class.getResourceAsStream("/Contacts.xml"));
//3. 得到根元素
Element rootElement = document.getRootElement();
//得到contact标签
Element contact = rootElement.element("contact");
//得到name标签中的文本
Element name = contact.element("name");
System.out.println(name.getText());
//得到子元素的文本
System.out.println(contact.elementText("name"));
//得到子元素的文本并且去掉前后空格
System.out.println(contact.elementTextTrim("name"));
}
}小结
| Element元素中的方法 | 说明 |
|---|---|
| String getText() | 得到元素中文本 |
| String elementText(元素名) | 得到子元素中文本 |
| String elementTextTrim(元素名) | 得到子元素中文本,去掉先后空格 |
13.案例:XML解析案例
运行效果

数据准备
Contact.xml
<?xml version="1.0" encoding="UTF-8"?>
<contactList>
<contact id="1">
<name>潘金莲</name>
<gender>女</gender>
</contact>
<contact id="2">
<name>武松</name>
<gender>男</gender>
</contact>
<contact id="3">
<name>武大狼</name>
<gender>男</gender>
</contact>
</contactList>Contact.java实体类
/**
* 联系人实体类
*/
public class Contact {
private int id;
private String name;
private String gender;
@Override
public String toString() {
return "Contact{" +
"id=" + id +
", name='" + name + '\'' +
", gender='" + gender + '\''
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
}步骤
- 创建集合对象用于封装所有的联系人
- 获得文档对象
- 获取根元素
- 获得所有的contact元素
- 遍历contact元素集合
- 每个contact创建一个联系人对象
- 获得id属性值,封装到id属性中
- 得到contact下的子元素的文本封装其它的属性
- 将联系人对象添加到集合中
- 遍历输出每一个联系人对象
代码
import com.github.krislin.entity.Contact;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.ArrayList;
import java.util.List;
public class Demo6Contact {
public static void main(String[] args) throws DocumentException {
//1. 得到SaxReader
SAXReader reader = new SAXReader();
//2. 得到文档对象
Document document = reader.read(Demo6Contact.class.getResourceAsStream("/Contact.xml"));
//3. 得到根元素
Element rootElement = document.getRootElement();
//4. 创建集合
List<Contact> list = new ArrayList<>();
//5. 得到所有联系人
List<Element> contactElements = rootElement.elements();
//每个就是一个联系人
for (Element contactElement : contactElements) {
//创建一个联系人
Contact contact = new Contact();
//System.out.println(contactElement.getName()); //打印标签名
//得到id属性值,将字符串转成int类型
int id = Integer.parseInt(contactElement.attributeValue("id"));
contact.setId(id);
//得到子元素中文本
contact.setName(contactElement.elementText("name"));
contact.setGender(contactElement.elementText("gender"));
//将当前对象添加到集合中
list.add(contact);
}
//打印集合中所有的联系人
for (Contact contact : list) {
System.out.println(contact);
}
}
}小结
| 案例中使用到的方法 | 作用 |
|---|---|
| List\ |
得到当前元素所有子元素 |
| String attributeValue() | 得到当前元素指定的属性值 |
| String elementTextTrim() | 得到子元素的文本,去掉空格 |
14.dom4j中与XPath表达式有关的方法
什么是XPath
作用:一种用于快速查找XML元素的路径表达式,是用于方便的检索XML文件中的信息。
XPath表达式分类
- 绝对路径
- 相对路径
- 全文搜索
- 属性查找
dom4j中与XPath相关的方法
注:使用XPath需要另外导入 jaxen-1.1.2.jar包

什么是Node对象

小结
| Document对象的方法 | 功能说明 |
|---|---|
| Node selectSingleNode(String xpath) | 通过xpath得到一个节点 |
| List selectNodes(String xpath) | 通过xpath得到一组节点 |
15.XPath:绝对路径和相对路径
绝对路径语法

绝对路径示例
需求
采用绝对路径获取从根节点开始逐层的查找/contactList/contact/name 节点列表并打印信息
步骤
- 使用JUnit,在@before方法中创建一个全局文档对象
- 创建 XML 解析器对象,读取 XML 文档并获得Document对象
- 定义 Xpath 表达式:/contactList/contact/name
- 调用Document对象的selectNodes()方法执行Xpath获得节点集合
- 遍历输出每个节点
代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
/**
使用xpath
*/
public class Demo7Xpath {
private Document document;
//在每个测试方法之前执行的方法
@Before
public void init() throws DocumentException {
//1. 得到SaxReader
SAXReader reader = new SAXReader();
//2. 得到文档对象
document = reader.read(Demo7Xpath.class.getResourceAsStream("/Contact.xml"));
}
/**
使用绝对路径
*/
@Test
public void testAbsolute() {
String xpath = "/contactList/contact/name";
//得到所有name元素
List<Node> nodeList = document.selectNodes(xpath);
for (Node node : nodeList) {
System.out.println(node.getText());
}
}
}相对路径的语法

相对路径的示例
需求
- 先采用绝对路径获取 contactList 节点
- 再采用相对路径获取下一级contact 节点的name子节点并打印信息。
步骤
- 定义 Xpath 表达式:/contactList
- 调用Document对象的 selectSingleNode 方法执行Xpath获得根节点对象
- 通过根节点对象调用selectNodes方法执行相对路径表达式:./contact/name
- 打印输出所有的节点
代码
/**
使用相对路径
*/
@Test
public void testRelative() {
//通过绝对路径得到/contactList
Node node = document.selectSingleNode("/contactList");
//通过相对路径得到name
Node nameNode = node.selectSingleNode("./contact/name");
System.out.println(nameNode.getText());
}16.XPath:全文搜索和属性查找
全文搜索语法

举例
| 举例 | 说明 |
|---|---|
| //contact | 找contact元素,无论元素在哪里 |
| //contact/name | 找contact,无论在哪一级,但name一定是contact的子节点 |
| //contact//name | contact无论在哪一种,name只要是contact的子孙元素都可以找到 |
全文搜索示例
需求
直接全文搜索所有的 name元素并打印
步骤
- 创建Xpath表达式 //name
- 使用selectNodes()方法查询所有的name节点
代码
/**
全文搜索
*/
@Test
public void testGlobalSearch() {
List<Node> nodes = document.selectNodes("//name");
for (Node node : nodes) {
System.out.println(node.getText());
}
}属性查找语法

属性查找的示例
需求
- 查找所有id属性节点
- 查找包括id属性的contact元素
- 查找包括id属性且属性名为的contact元素
步骤
- 创建Xpath表达式
- 使用selectNodes()方法查询所有的节点
代码
/**
属性查找
*/
@Test
public void testAttributeFind() {
//1. 查找所有id属性节点
/*List<Node> nodes = document.selectNodes("//@id");
//是属性对象Attribute
for (Node node : nodes) {
//输出属性值
Attribute a = (Attribute) node;
System.out.println("属性值:" + a.getValue());
}*/
//2. 查找包括id属性的contact元素
/*List<Node> nodeList = document.selectNodes("//contact[@id]");
for (Node node : nodeList) {
System.out.println(node.getName());
}*/
//3. 查找包括id属性且属性名为的contact元素
Node node = document.selectSingleNode("//contact[@id=2]");
System.out.println(node.getName());
}小结
| XPath表达式分类 | 语法 |
|---|---|
| 绝对路径 | /xxx/xxx/xxx |
| 相对路径 | ./xx/xx |
| 全文路径 | //xxx |
| 属性查找 | //@属性名 |
总结
-
能够说出 XML 的作用
- 数据交换
- 配置文件
- 信息传输
- 数据的存储
-
了解 XML 的组成元素
- 声明
- 元素
- 属性
- 注释
- 实体字符
- CDATA字符数据区
- 处理指令
-
能够说出有哪些 XML约束技术
- DTD
- Schema
- 支持数据类型的约束
- 本身xsd也是一个XML文件
- 一个XML可以有多个xsd约束文件
-
能够说出解析 XML 文档 DOM方式原理
-
能够说出Dom4j常用的类
组成 说明 Document 文档对象 Node 节点 Element 元素 Attribute 属性 Text 文本 -
能够通过Dom4j得到文档对象
// 1.创建Dom4J的框架对象 SAXReader saxReader = new SAXReader(); // 2.读取XML文件加载到内存中成为一个Document文档对象。 InputStream is = Dom4JDemo.class.getResourceAsStream("/Contact.xml"); Document document = saxReader.read(is); -
能够读取Dom树上的元素对象
Document方法名 功能说明 Element getRootElement() 得到根元素 Element方法名 功能说明 String getName() 得到元素的标签名 Element element(String name) 通过元素名字得到元素对象 List\ elements() 得到所有的子元素 List\ elements(String name) 得到指定名字的所有子元素 -
能够使用 XPath 解析 XML 文档
Document对象的方法 功能说明 Node selectSingleNode(String xpath) 得到一个节点 List selectNodes(String xpath) 得到多个节点