JDK8新特性
1.Lambda表达式
1.1 函数式编程思想概述
在数学中,函数就是有输入量、输出量的一套计算方案,也就是“拿什么东西做什么事情”。相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语法——强调做什么,而不是以什么形式做。
面向对象的思想:
做一件事情,找一个能解决这个事情的对象,调用对象的方法,完成事情.
函数式编程思想:
只要能获取到结果,谁去做的,怎么做的都不重要,重视的是结果,不重视过程
1.2 冗余的Runnable代码
传统写法
当需要启动一个线程去完成任务时,通常会通过java.lang.Runnable接口来定义任务内容,并使用java.lang.Thread类来启动该线程。代码如下:
public class Demo01Runnable {
public static void main(String[] args) {
// 匿名内部类
Runnable task = new Runnable() {
@Override
public void run() { // 覆盖重写抽象方法
System.out.println("多线程任务执行!");
}
};
new Thread(task).start(); // 启动线程
}
}本着“一切皆对象”的思想,这种做法是无可厚非的:首先创建一个Runnable接口的匿名内部类对象来指定任务内容,再将其交给一个线程来启动。
代码分析
对于Runnable的匿名内部类用法,可以分析出几点内容:
Thread类需要Runnable接口作为参数,其中的抽象run方法是用来指定线程任务内容的核心;- 为了指定
run的方法体,不得不需要Runnable接口的实现类; - 为了省去定义一个
RunnableImpl实现类的麻烦,不得不使用匿名内部类; - 必须覆盖重写抽象
run方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错; - 而实际上,似乎只有方法体才是关键所在。
1.3 编程思想转换
做什么,而不是怎么做
我们真的希望创建一个匿名内部类对象吗?不。我们只是为了做这件事情而不得不创建一个对象。我们真正希望做的事情是:将run方法体内的代码传递给Thread类知晓。
传递一段代码——这才是我们真正的目的。而创建对象只是受限于面向对象语法而不得不采取的一种手段方式。那,有没有更加简单的办法?如果我们将关注点从“怎么做”回归到“做什么”的本质上,就会发现只要能够更好地达到目的,过程与形式其实并不重要。
生活举例

当我们需要从北京到上海时,可以选择高铁、汽车、骑行或是徒步。我们的真正目的是到达上海,而如何才能到达上海的形式并不重要,所以我们一直在探索有没有比高铁更好的方式——搭乘飞机。

而现在这种飞机(甚至是飞船)已经诞生:2014年3月Oracle所发布的Java 8(JDK 1.8)中,加入了Lambda表达式的重量级新特性,为我们打开了新世界的大门。
1.4 体验Lambda的更优写法
借助Java 8的全新语法,上述Runnable接口的匿名内部类写法可以通过更简单的Lambda表达式达到等效:
public class Demo02LambdaRunnable {
public static void main(String[] args) {
new Thread(() -> System.out.println("多线程任务执行!")).start(); // 启动线程
}
}这段代码和刚才的执行效果是完全一样的,可以在1.8或更高的编译级别下通过。从代码的语义中可以看出:我们启动了一个线程,而线程任务的内容以一种更加简洁的形式被指定。
不再有“不得不创建接口对象”的束缚,不再有“抽象方法覆盖重写”的负担,就是这么简单!
1.5 回顾匿名内部类
Lambda是怎样击败面向对象的?在上例中,核心代码其实只是如下所示的内容:
() -> System.out.println("多线程任务执行!")为了理解Lambda的语义,我们需要从传统的代码起步。
使用实现类
要启动一个线程,需要创建一个Thread类的对象并调用start方法。而为了指定线程执行的内容,需要调用Thread类的构造方法:
public Thread(Runnable target)
为了获取Runnable接口的实现对象,可以为该接口定义一个实现类RunnableImpl:
public class RunnableImpl implements Runnable {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}然后创建该实现类的对象作为Thread类的构造参数:
public class Demo03ThreadInitParam {
public static void main(String[] args) {
Runnable task = new RunnableImpl();
new Thread(task).start();
}
}使用匿名内部类
这个RunnableImpl类只是为了实现Runnable接口而存在的,而且仅被使用了唯一一次,所以使用匿名内部类的语法即可省去该类的单独定义,即匿名内部类:
public class Demo04ThreadNameless {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}).start();
}
}匿名内部类的好处与弊端
一方面,匿名内部类可以帮我们省去实现类的定义;另一方面,匿名内部类的语法——确实太复杂了!
语义分析
仔细分析该代码中的语义,Runnable接口只有一个run方法的定义:
public abstract void run();
即制定了一种做事情的方案(其实就是一个函数):
- 无参数:不需要任何条件即可执行该方案。
- 无返回值:该方案不产生任何结果。
- 代码块(方法体):该方案的具体执行步骤。
同样的语义体现在Lambda语法中,要更加简单:
() -> System.out.println("多线程任务执行!")- 前面的一对小括号即
run方法的参数(无),代表不需要任何条件; - 中间的一个箭头代表将前面的参数传递给后面的代码;
- 后面的输出语句即业务逻辑代码。
1.6 Lambda标准格式
Lambda省去面向对象的条条框框,格式由3个部分组成:
- 一些参数
- 一个箭头
- 一段代码
Lambda表达式的标准格式为:
(参数类型 参数名称) -> { 代码语句 }格式说明:
- 小括号内的语法与传统方法参数列表一致:无参数则留空;多个参数则用逗号分隔。
->是新引入的语法格式,代表指向动作。- 大括号内的语法与传统方法体要求基本一致。
1.7 练习:使用Lambda标准格式(无参无返回)
题目
给定一个厨子Cook接口,内含唯一的抽象方法makeFood,且无参数、无返回值。如下:
public interface Cook {
void makeFood();
}在下面的代码中,请使用Lambda的标准格式调用invokeCook方法,打印输出“吃饭啦!”字样:
public class Demo05InvokeCook {
public static void main(String[] args) {
// TODO 请在此使用Lambda【标准格式】调用invokeCook方法
}
private static void invokeCook(Cook cook) {
cook.makeFood();
}
}解答
public static void main(String[] args) {
invokeCook(() -> {
System.out.println("吃饭啦!");
});
}备注:小括号代表
Cook接口makeFood抽象方法的参数为空,大括号代表makeFood的方法体。
1.8 Lambda的参数和返回值
需求:
使用数组存储多个Person对象
对数组中的Person对象使用Arrays的sort方法通过年龄进行升序排序下面举例演示java.util.Comparator<T>接口的使用场景代码,其中的抽象方法定义为:
public abstract int compare(T o1, T o2);
当需要对一个对象数组进行排序时,Arrays.sort方法需要一个Comparator接口实例来指定排序的规则。假设有一个Person类,含有String name和int age两个成员变量:
public class Person {
private String name;
private int age;
// 省略构造器、toString方法与Getter Setter
}传统写法
如果使用传统的代码对Person[]数组进行排序,写法如下:
import java.util.Arrays;
import java.util.Comparator;
public class Demo06Comparator {
public static void main(String[] args) {
// 本来年龄乱序的对象数组
Person[] array = {
new Person("古力娜扎", 19),
new Person("迪丽热巴", 18),
new Person("马尔扎哈", 20) };
// 匿名内部类
Comparator<Person> comp = new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
};
Arrays.sort(array, comp); // 第二个参数为排序规则,即Comparator接口实例
for (Person person : array) {
System.out.println(person);
}
}
}这种做法在面向对象的思想中,似乎也是“理所当然”的。其中Comparator接口的实例(使用了匿名内部类)代表了“按照年龄从小到大”的排序规则。
代码分析
下面我们来搞清楚上述代码真正要做什么事情。
- 为了排序,
Arrays.sort方法需要排序规则,即Comparator接口的实例,抽象方法compare是关键; - 为了指定
compare的方法体,不得不需要Comparator接口的实现类; - 为了省去定义一个
ComparatorImpl实现类的麻烦,不得不使用匿名内部类; - 必须覆盖重写抽象
compare方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错; - 实际上,只有参数和方法体才是关键。
Lambda写法
import java.util.Arrays;
public class Demo07ComparatorLambda {
public static void main(String[] args) {
Person[] array = {
new Person("古力娜扎", 19),
new Person("迪丽热巴", 18),
new Person("马尔扎哈", 20) };
Arrays.sort(array, (Person a, Person b) -> {
return a.getAge() - b.getAge();
});
for (Person person : array) {
System.out.println(person);
}
}
}1.9 练习:使用Lambda标准格式(有参有返回)
题目
给定一个计算器Calculator接口,内含抽象方法calc可以将两个int数字相加得到和值:
public interface Calculator {
int calc(int a, int b);
}在下面的代码中,请使用Lambda的标准格式调用invokeCalc方法,完成120和130的相加计算:
public class Demo08InvokeCalc {
public static void main(String[] args) {
// TODO 请在此使用Lambda【标准格式】调用invokeCalc方法来计算120+130的结果ß
}
private static void invokeCalc(int a, int b, Calculator calculator) {
int result = calculator.calc(a, b);
System.out.println("结果是:" + result);
}
}解答
public static void main(String[] args) {
invokeCalc(120, 130, (int a, int b) -> {
return a + b;
});
}备注:小括号代表
Calculator接口calc抽象方法的参数,大括号代表calc的方法体。
1.10 Lambda省略格式
可推导即可省略
Lambda强调的是“做什么”而不是“怎么做”,所以凡是可以根据上下文推导得知的信息,都可以省略。例如上例还可以使用Lambda的省略写法:
public static void main(String[] args) {
invokeCalc(120, 130, (a, b) -> a + b);
}省略规则
在Lambda标准格式的基础上,使用省略写法的规则为:
- 小括号内参数的类型可以省略;
- 如果小括号内有且仅有一个参,则小括号可以省略;
- 如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。
备注:掌握这些省略规则后,请对应地回顾本章开头的多线程案例。
1.11 练习:使用Lambda省略格式
题目
仍然使用前文含有唯一makeFood抽象方法的厨子Cook接口,在下面的代码中,请使用Lambda的省略格式调用invokeCook方法,打印输出“吃饭啦!”字样:
public class Demo09InvokeCook {
public static void main(String[] args) {
// TODO 请在此使用Lambda【省略格式】调用invokeCook方法
}
private static void invokeCook(Cook cook) {
cook.makeFood();
}
}解答
public static void main(String[] args) {
invokeCook(() -> System.out.println("吃饭啦!"));
}1.12 Lambda的使用前提
Lambda的语法非常简洁,完全没有面向对象复杂的束缚。但是使用时有几个问题需要特别注意:
- 使用Lambda必须具有接口,且要求接口中有且仅有一个抽象方法。
无论是JDK内置的Runnable、Comparator接口还是自定义的接口,只有当接口中的抽象方法存在且唯一时,才可以使用Lambda。 - 使用Lambda必须具有上下文推断。
也就是方法的参数或局部变量类型必须为Lambda对应的接口类型,才能使用Lambda作为该接口的实例。
备注:有且仅有一个抽象方法的接口,称为“函数式接口”。
2.函数式
2.1 函数式接口
1.概念
函数式接口在Java中是指:有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可
以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导。
备注:“语法糖”是指使用更加方便,但是原理不变的代码语法。例如在遍历集合时使用的for-each语法,其实
底层的实现原理仍然是迭代器,这便是“语法糖”。从应用层面来讲,Java中的Lambda可以被当做是匿名内部
类的“语法糖”,但是二者在原理上是不同的。
2.格式
只要确保接口中有且仅有一个抽象方法即可:
修饰符 interface 接口名称 {
public abstract 返回值类型 方法名称(可选参数信息);
// 其他非抽象方法内容
}由于接口当中抽象方法的public abstract是可以省略的,所以定义一个函数式接口很简单:
public interface MyFunctionalInterface {
void myMethod();
}3.@FunctionalInterface注解
与 @Override 注解的作用类似,Java 8中专门为函数式接口引入了一个新的注解: @FunctionalInterface 。该注
解可用于一个接口的定义上:
@FunctionalInterface
public interface MyFunctionalInterface {
void myMethod();
}一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注
意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样。
4.自定义函数式接口
对于刚刚定义好的 MyFunctionalInterface 函数式接口,典型使用场景就是作为方法的参数:
public class Demo09FunctionalInterface {
// 使用自定义的函数式接口作为方法参数
private static void doSomething(MyFunctionalInterface inter) {
inter.myMethod(); // 调用自定义的函数式接口方法
}
public static void main(String[] args) {
// 调用使用函数式接口的方法
doSomething(() ‐> System.out.println("Lambda执行啦!"));
}
}2.2 函数式编程
1.Lambda的延迟执行
有些场景的代码执行后,结果不一定会被使用,从而造成性能浪费。而Lambda表达式是延迟执行的,这正好可以
作为解决方案,提升性能。
性能浪费的日志案例
注:日志可以帮助我们快速的定位问题,记录程序运行过程中的情况,以便项目的监控和优化。
一种典型的场景就是对参数进行有条件使用,例如对日志消息进行拼接后,在满足条件的情况下进行打印输出:
public class Demo01Logger {
private static void log(int level, String msg) {
if (level == 1) {
System.out.println(msg);
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(1, msgA + msgB + msgC);
}
}这段代码存在问题:无论级别是否满足要求,作为 log 方法的第二个参数,三个字符串一定会首先被拼接并传入方
法内,然后才会进行级别判断。如果级别不符合要求,那么字符串的拼接操作就白做了,存在性能浪费。
备注:SLF4J是应用非常广泛的日志框架,它在记录日志时为了解决这种性能浪费的问题,并不推荐首先进行
字符串的拼接,而是将字符串的若干部分作为可变参数传入方法中,仅在日志级别满足要求的情况下才会进
行字符串拼接。例如: LOGGER.debug("变量{}的取值为{}。", "os", "macOS") ,其中的大括号 {} 为占位
符。如果满足日志级别要求,则会将“os”和“macOS”两个字符串依次拼接到大括号的位置;否则不会进行字
符串拼接。这也是一种可行解决方案,但Lambda可以做到更好。
体验Lambda的更优写法
使用Lambda必然需要一个函数式接口:
@FunctionalInterface
public interface MessageBuilder {
String buildMessage();
}然后对 log 方法进行改造:
public class Demo02LoggerLambda {
private static void log(int level, MessageBuilder builder) {
if (level == 1) {
System.out.println(builder.buildMessage());
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(1, () ‐> msgA + msgB + msgC );
}
}这样一来,只有当级别满足要求的时候,才会进行三个字符串的拼接;否则三个字符串将不会进行拼接。
证明Lambda的延迟
下面的代码可以通过结果进行验证:
public class Demo03LoggerDelay {
private static void log(int level, MessageBuilder builder) {
if (level == 1) {
System.out.println(builder.buildMessage());
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(2, () ‐> {
System.out.println("Lambda执行!");
return msgA + msgB + msgC;
});
}
}从结果中可以看出,在不符合级别要求的情况下,Lambda将不会执行。从而达到节省性能的效果。
扩展:实际上使用内部类也可以达到同样的效果,只是将代码操作延迟到了另外一个对象当中通过调用方法
来完成。而是否调用其所在方法是在条件判断之后才执行的。
2.使用Lambda作为参数和返回值
如果抛开实现原理不说,Java中的Lambda表达式可以被当作是匿名内部类的替代品。如果方法的参数是一个函数
式接口类型,那么就可以使用Lambda表达式进行替代。使用Lambda表达式作为方法参数,其实就是使用函数式
接口作为方法参数。
例如 java.lang.Runnable 接口就是一个函数式接口,假设有一个 startThread 方法使用该接口作为参数,那么就
可以使用Lambda进行传参。这种情况其实和 Thread 类的构造方法参数为 Runnable 没有本质区别。
public class Demo04Runnable {
private static void startThread(Runnable task) {
new Thread(task).start();
}
public static void main(String[] args) {
startThread(() ‐> System.out.println("线程任务执行!"));
}
}类似地,如果一个方法的返回值类型是一个函数式接口,那么就可以直接返回一个Lambda表达式。当需要通过一
个方法来获取一个java.util.Comparator 接口类型的对象作为排序器时,就可以调该方法获取。
import java.util.Arrays;
import java.util.Comparator;
public class Demo06Comparator {
private static Comparator<String> newComparator() {
return (a, b) ‐> b.length() ‐ a.length();
}
public static void main(String[] args) {
String[] array = { "abc", "ab", "abcd" };
System.out.println(Arrays.toString(array));
Arrays.sort(array, newComparator());
System.out.println(Arrays.toString(array));
}
}其中直接return一个Lambda表达式即可。
2.3 常用函数式接口
JDK提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在 java.util.function 包中被提供。
下面是最简单的几个接口及使用示例。
1.Supplier接口
java.util.function.Supplier<T>接口仅包含一个无参的方法: T get() 。用来获取一个泛型参数指定类型的对
象数据。由于这是一个函数式接口,这也就意味着对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象
数据。
import java.util.function.Supplier;
public class Demo08Supplier {
private static String getString(Supplier<String> function) {
return function.get();
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
System.out.println(getString(() ‐> msgA + msgB));
}
}2.练习:求数组元素最大值
题目
使用 Supplier 接口作为方法参数类型,通过Lambda表达式求出int数组中的最大值。提示:接口的泛型请使用
java.lang.Integer类。
解答
public class Demo02Test {
//定一个方法,方法的参数传递Supplier,泛型使用Integer
public static int getMax(Supplier<Integer> sup){
return sup.get();
}
public static void main(String[] args) {
int arr[] = {2,3,4,52,333,23};
//调用getMax方法,参数传递Lambda
int maxNum = getMax(()‐>{
//计算数组的最大值
int max = arr[0];
for(int i : arr){
if(i>max){
max = i;
}
}
return max;
});
System.out.println(maxNum);
}
}3.Consumer接口
java.util.function.Consumer<T> 接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,
其数据类型由泛型决定。
抽象方法:accept
Consumer 接口中包含抽象方法 void accept(T t) ,意为消费一个指定泛型的数据。基本使用如:
import java.util.function.Consumer;
public class Demo09Consumer {
private static void consumeString(Consumer<String> function) {
function.accept("Hello");
}
public static void main(String[] args) {
consumeString(s ‐> System.out.println(s));
}
}当然,更好的写法是使用方法引用。
默认方法:andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费数据的时候,首先做一个操作,
然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的default方法 andThen 。下面是JDK的源代码:
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) ‐> { accept(t); after.accept(t); };
}备注:
java.util.Objects的requireNonNull静态方法将会在参数为null时主动抛出
NullPointerException异常。这省去了重复编写if语句和抛出空指针异常的麻烦。
要想实现组合,需要两个或多个Lambda表达式即可,而 andThen 的语义正是“一步接一步”操作。例如两个步骤组
合的情况:
import java.util.function.Consumer;
public class Demo10ConsumerAndThen {
private static void consumeString(Consumer<String> one, Consumer<String> two) {
one.andThen(two).accept("Hello");
}
public static void main(String[] args) {
consumeString(
s ‐> System.out.println(s.toUpperCase()),
s ‐> System.out.println(s.toLowerCase()));
}
}运行结果将会首先打印完全大写的HELLO,然后打印完全小写的hello。当然,通过链式写法可以实现更多步骤的
组合。
4.练习:格式化打印信息
题目
下面的字符串数组当中存有多条信息,请按照格式“ 姓名:XX。性别:XX。 ”的格式将信息打印出来。要求将打印姓
名的动作作为第一个 Consumer 接口的Lambda实例,将打印性别的动作作为第二个 Consumer 接口的Lambda实
例,将两个 Consumer 接口按照顺序“拼接”到一起。
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男" };
}解答
import java.util.function.Consumer;
public class DemoConsumer {
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男" };
printInfo(s ‐> System.out.print("姓名:" + s.split(",")[0]),
s ‐> System.out.println("。性别:" + s.split(",")[1] + "。"),
array);
}
private static void printInfo(Consumer<String> one, Consumer<String> two, String[] array) {
for (String info : array) {
one.andThen(two).accept(info); // 姓名:迪丽热巴。性别:女。
}
}
} 5.Predicate接口
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用java.util.function.Predicate<T> 接口。
抽象方法:test
Predicate 接口中包含一个抽象方法: boolean test(T t) 。用于条件判断的场景:
import java.util.function.Predicate;
public class Demo15PredicateTest {
private static void method(Predicate<String> predicate) {
boolean veryLong = predicate.test("HelloWorld");
System.out.println("字符串很长吗:" + veryLong);
}
public static void main(String[] args) {
method(s ‐> s.length() > 5);
}
}条件判断的标准是传入的Lambda表达式逻辑,只要字符串长度大于5则认为很长。
默认方法:and
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。其中将两个 Predicate 条件使用“与”逻辑连接起来实
现“并且”的效果时,可以使用default方法 and 。其JDK源码为:
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) && other.test(t);
}如果要判断一个字符串既要包含大写“H”,又要包含大写“W”,那么:
import java.util.function.Predicate;
public class Demo16PredicateAnd {
private static void method(Predicate<String> one, Predicate<String> two) {
boolean isValid = one.and(two).test("Helloworld");
System.out.println("字符串符合要求吗:" + isValid);
}
public static void main(String[] args) {
method(s ‐> s.contains("H"), s ‐> s.contains("W"));
}
}默认方法:or
与 and 的“与”类似,默认方法 or 实现逻辑关系中的“或”。JDK源码为:
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) || other.test(t);
}如果希望实现逻辑“字符串包含大写H或者包含大写W”,那么代码只需要将“and”修改为“or”名称即可,其他都不
变:
import java.util.function.Predicate;
public class Demo16PredicateAnd {
private static void method(Predicate<String> one, Predicate<String> two) {
boolean isValid = one.or(two).test("Helloworld");
System.out.println("字符串符合要求吗:" + isValid);
}
public static void main(String[] args) {
method(s ‐> s.contains("H"), s ‐> s.contains("W"));
}
}默认方法:negate
“与”、“或”已经了解了,剩下的“非”(取反)也会简单。默认方法 negate 的JDK源代码为:
default Predicate<T> negate() {
return (t) ‐> !test(t);
}从实现中很容易看出,它是执行了test方法之后,对结果boolean值进行“!”取反而已。一定要在 test 方法调用之前
调用 negate 方法,正如 and 和 or 方法一样:
import java.util.function.Predicate;
public class Demo17PredicateNegate {
private static void method(Predicate<String> predicate) {
boolean veryLong = predicate.negate().test("HelloWorld");
System.out.println("字符串很长吗:" + veryLong);
}
public static void main(String[] args) {
method(s ‐> s.length() < 5);
}
}6.集合信息筛选
题目
数组当中有多条“姓名+性别”的信息如下,请通过 Predicate 接口的拼装将符合要求的字符串筛选到集合
ArrayList 中,需要同时满足两个条件:
- 必须为女生;
- 姓名为4个字。
public class DemoPredicate {
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男", "赵丽颖,女" };
}
}解答
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
public class DemoPredicate {
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男", "赵丽颖,女" };
List<String> list = filter(array,
s ‐> "女".equals(s.split(",")[1]),
s ‐> s.split(",")[0].length() == 4);
System.out.println(list);
}
private static List<String> filter(String[] array, Predicate<String> one,
Predicate<String> two) {
List<String> list = new ArrayList<>();
for (String info : array) {
if (one.and(two).test(info)) {
list.add(info);
}
}
return list;
}
}7.Function接口
java.util.function.Function<T,R> 接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,
后者称为后置条件。
抽象方法:apply
Function 接口中最主要的抽象方法为:R apply(T t) ,根据类型T的参数获取类型R的结果。
使用的场景例如:将 String 类型转换为 Integer 类型。
import java.util.function.Function;
public class Demo11FunctionApply {
private static void method(Function<String, Integer> function) {
int num = function.apply("10");
System.out.println(num + 20);
}
public static void main(String[] args) {
method(s ‐> Integer.parseInt(s));
}
}当然,最好是通过方法引用的写法。
默认方法:andThen
Function 接口中有一个默认的 andThen 方法,用来进行组合操作。JDK源代码如:
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) ‐> after.apply(apply(t));
}该方法同样用于“先做什么,再做什么”的场景,和 Consumer 中的 andThen 差不多:
import java.util.function.Function;
public class Demo12FunctionAndThen {
private static void method(Function<String, Integer> one, Function<Integer, Integer> two) {
int num = one.andThen(two).apply("10");
System.out.println(num + 20);
}
public static void main(String[] args) {
method(str‐>Integer.parseInt(str)+10, i ‐> i *= 10);
}
}第一个操作是将字符串解析成为int数字,第二个操作是乘以10。两个操作通过 andThen 按照前后顺序组合到了一
起。
请注意,Function的前置条件泛型和后置条件泛型可以相同。
8.自定义函数模型拼接
题目
请使用 Function 进行函数模型的拼接,按照顺序需要执行的多个函数操作为:
- 将字符串截取数字年龄部分,得到字符串;
- 将上一步的字符串转换成为int类型的数字;
- 将上一步的int数字累加100,得到结果int数字。
解答
import java.util.function.Function;
public class DemoFunction {
public static void main(String[] args) {
String str = "赵丽颖,20";
int age = getAgeNum(str, s ‐> s.split(",")[1],
s ‐>Integer.parseInt(s),
n ‐> n += 100);
System.out.println(age);
}
private static int getAgeNum(String str, Function<String, String> one,
Function<String, Integer> two,
Function<Integer, Integer> three) {
return one.andThen(two).andThen(three).apply(str);
}
}3.方法引用
3.1 引入
在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿什么参数做什么操作。那么考虑一种情况:如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再写重复逻辑?
1.冗余的Lambda场景
来看一个简单的函数式接口以应用Lambda表达式:
@FunctionalInterface
public interface Printable {
void print(String str);
}在 Printable 接口当中唯一的抽象方法 print 接收一个字符串参数,目的就是为了打印显示它。那么通过Lambda来使用它的代码很简单:
public class Demo01PrintSimple {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(s ‐> System.out.println(s));
}
}其中 printString 方法只管调用 Printable 接口的 print 方法,而并不管 print 方法的具体实现逻辑会将字符串打印到什么地方去。而 main 方法通过Lambda表达式指定了函数式接口 Printable 的具体操作方案为:拿到String(类型可推导,所以可省略)数据后,在控制台中输出它。
2.问题分析
这段代码的问题在于,对字符串进行控制台打印输出的操作方案,明明已经有了现成的实现,那就是 System.out对象中的 println(String) 方法。既然Lambda希望做的事情就是调用 println(String) 方法,那何必自己手动调用呢?
3.用方法引用改进代码
能否省去Lambda的语法格式(尽管它已经相当简洁)呢?只要“引用”过去就好了:
public class Demo02PrintRef {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(System.out::println);
}
}请注意其中的双冒号 :: 写法,这被称为“方法引用”,而双冒号是一种新的语法。
3.2 方法引用符
双冒号 :: 为引用运算符,而它所在的表达式被称为方法引用。如果Lambda要表达的函数方案已经存在于某个方法的实现中,那么则可以通过双冒号来引用该方法作为Lambda的替代者。
语义分析
例如上例中, System.out 对象中有一个重载的 println(String) 方法恰好就是我们所需要的。那么对于printString 方法的函数式接口参数,对比下面两种写法,完全等效:
- Lambda表达式写法: s -> System.out.println(s);
- 方法引用写法: System.out::println
第一种语义是指:拿到参数之后经Lambda之手,继而传递给 System.out.println 方法去处理。
第二种等效写法的语义是指:直接让 System.out 中的 println 方法来取代Lambda。两种写法的执行效果完全一样,而第二种方法引用的写法复用了已有方案,更加简洁。
注:Lambda 中 传递的参数 一定是方法引用中 的那个方法可以接收的类型,否则会抛出异常
推导与省略
如果使用Lambda,那么根据“可推导就是可省略”的原则,无需指定参数类型,也无需指定重载形式——它们都将被自动推导。而如果使用方法引用,也是同样可以根据上下文进行推导。
函数式接口是Lambda的基础,而方法引用是Lambda的孪生兄弟。
下面这段代码将会调用 println 方法的不同重载形式,将函数式接口改为int类型的参数:
@FunctionalInterface
public interface PrintableInteger {
void print(int str);
}由于上下文变了之后可以自动推导出唯一对应的匹配重载,所以方法引用没有任何变化:
public class Demo03PrintOverload {
private static void printInteger(PrintableInteger data) {
data.print(1024);
}
public static void main(String[] args) {
printInteger(System.out::println);
}
}这次方法引用将会自动匹配到 println(int) 的重载形式。
3.3 方法引用基本使用
方法引用使用一对冒号 :: 。
下面,我们在 Car 类中定义了 4 个方法作为例子来区分 Java 中 4 种不同方法的引用。
public static class Car {
public static Car create( final Supplier< Car > supplier ) {
return supplier.get();
}
public static void collide( final Car car ) {
System.out.println( "Collided " + car.toString() );
}
public void follow( final Car another ) {
System.out.println( "Following the " + another.toString() );
}
public void repair() {
System.out.println( "Repaired " + this.toString() );
}
}第一种方法引用的类型是构造器引用,语法是Class::new,或者更一般的形式:Class
final Car car = Car.create( Car::new );
final List< Car > cars = Arrays.asList( car );第二种方法引用的类型是静态方法引用,语法是Class::static_method。注意:这个方法接受一个Car类型的参数。
cars.forEach( Car::collide );第三种方法引用的类型是某个类的成员方法的引用,语法是Class::method,注意,这个方法没有定义入参:
cars.forEach( Car::repair );第四种方法引用的类型是某个实例对象的成员方法的引用,语法是instance::method。注意:这个方法接受一个Car类型的参数:
final Car police = Car.create( Car::new );
cars.forEach( police::follow );3.4 通过对象名引用成员方法
这是最常见的一种用法。如果一个类中已经存在了一个成员方法:
public class MethodRefObject {
public void printUpperCase(String str) {
System.out.println(str.toUpperCase());
}
}函数式接口仍然定义为:
@FunctionalInterface
public interface Printable {
void print(String str);
}那么当需要使用这个 printUpperCase 成员方法来替代 Printable 接口的Lambda的时候,已经具有了MethodRefObject 类的对象实例,则可以通过对象名引用成员方法,代码为:
public class Demo04MethodRef {
private static void printString(Printable lambda) {
lambda.print("Hello");
}
public static void main(String[] args) {
MethodRefObject obj = new MethodRefObject();
printString(obj::printUpperCase);
}
}3.5 通过类名称引用静态方法
由于在 java.lang.Math 类中已经存在了静态方法 abs ,所以当我们需要通过Lambda来调用该方法时,有两种写法。首先是函数式接口:
@FunctionalInterface
public interface Calcable {
int calc(int num);
}第一种写法是使用Lambda表达式:
public class Demo05Lambda {
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, n ‐> Math.abs(n));
}
}但是使用方法引用的更好写法是:
public class Demo06MethodRef {
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, Math::abs);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: n -> Math.abs(n)
- 方法引用: Math::abs
3.6 通过super引用成员方法
如果存在继承关系,当Lambda中需要出现super调用时,也可以使用方法引用进行替代。首先是函数式接口:
@FunctionalInterface
public interface Greetable {
void greet();
}然后是父类 Human 的内容:
public class Human {
public void sayHello() {
System.out.println("Hello!");
}
}最后是子类 Man 的内容,其中使用了Lambda的写法:
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
//调用method方法,使用Lambda表达式
method(()‐>{
//创建Human对象,调用sayHello方法
new Human().sayHello();
});
//简化Lambda
method(()‐>new Human().sayHello());
//使用super关键字代替父类对象
method(()‐>super.sayHello());
}
}但是如果使用方法引用来调用父类中的 sayHello 方法会更好,例如另一个子类 Woman :
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
method(super::sayHello);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: () -> super.sayHello()
- 方法引用: super::sayHello
3.7 通过this引用成员方法
this代表当前对象,如果需要引用的方法就是当前类中的成员方法,那么可以使用“this::成员方法”的格式来使用方法引用。首先是简单的函数式接口:
@FunctionalInterface
public interface Richable {
void buy();
}下面是一个丈夫 Husband 类:
public class Husband {
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> System.out.println("买套房子"));
}
}开心方法 beHappy 调用了结婚方法 marry ,后者的参数为函数式接口 Richable ,所以需要一个Lambda表达式。但是如果这个Lambda表达式的内容已经在本类当中存在了,则可以对 Husband 丈夫类进行修改:
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> this.buyHouse());
}
}如果希望取消掉Lambda表达式,用方法引用进行替换,则更好的写法为:
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(this::buyHouse);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: () -> this.buyHouse()
- 方法引用: this::buyHouse
3.8 类的构造器引用
由于构造器的名称与类名完全一样,并不固定。所以构造器引用使用 类名称::new 的格式表示。首先是一个简单的 Person 类:
public class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}然后是用来创建 Person 对象的函数式接口:
public interface PersonBuilder {
Person buildPerson(String name);
}要使用这个函数式接口,可以通过Lambda表达式:
public class Demo09Lambda {
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", name ‐> new Person(name));
}
}但是通过构造器引用,有更好的写法:
public class Demo10ConstructorRef {
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", Person::new);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: name -> new Person(name)
- 方法引用: Person::new
3.9 数组的构造器引用
数组也是 Object 的子类对象,所以同样具有构造器,只是语法稍有不同。如果对应到Lambda的使用场景中时,需要一个函数式接口:
@FunctionalInterface
public interface ArrayBuilder {
int[] buildArray(int length);
}在应用该接口的时候,可以通过Lambda表达式:
public class Demo11ArrayInitRef {
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, length ‐> new int[length]);
}
}但是更好的写法是使用数组的构造器引用:
public class Demo12ArrayInitRef {
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, int[]::new);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: length -> new int[length]
- 方法引用: int[]::new
4.Stream
在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。
4.1 引言
传统集合的多步遍历代码
几乎所有的集合(如Collection接口或Map接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
public class Demo01ForEach {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
for (String name : list) {
System.out.println(name);
}
}
}这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
循环遍历的弊端
Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
- for循环的语法就是“怎么做”
- for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
- 将集合A根据条件一过滤为子集B;
- 然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:
public class Demo02NormalFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
List<String> shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
for (String name : shortList) {
System.out.println(name);
}
}
}这段代码中含有三个循环,每一个作用不同:
- 首先筛选所有姓张的人;
- 然后筛选名字有三个字的人;
- 最后进行对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那,Lambda的衍生物Stream能给我们带来怎样更加优雅的写法呢?
Stream的更优写法
下面来看一下借助Java 8的Stream API,什么才叫优雅:
public class Demo03StreamFilter {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(System.out::println);
}
}直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
4.2 流式思想概述
注意:请暂时忘记对传统IO流的固有印象!
整体来看,流式思想类似于工厂车间的“生产流水线”。
当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。
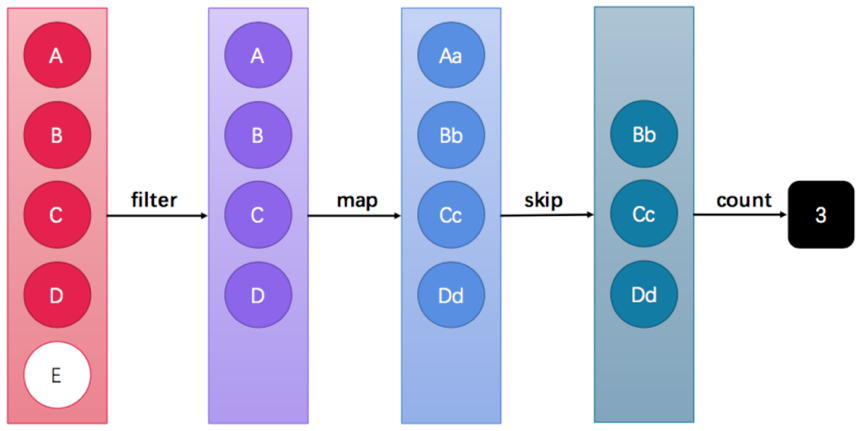
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。
这里的filter、map、skip都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
Stream(流)是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源流的来源, 可以是集合,数组 等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent
style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。 - 内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭
代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
当使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换→执行操作获取想要的结
果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以
像链条一样排列,变成一个管道。
4.3 获取流方式
java.util.stream.Stream<T>是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)
获取一个流非常简单,有以下几种常用的方式:
- 所有的
Collection集合都可以通过stream默认方法获取流; Stream接口的静态方法of可以获取数组对应的流。
方式1 : 根据Collection获取流
首先,java.util.Collection接口中加入了default方法stream用来获取流,所以其所有实现类均可获取流。
import java.util.*;
import java.util.stream.Stream;
public class Demo04GetStream {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// ...
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
// ...
Stream<String> stream2 = set.stream();
Vector<String> vector = new Vector<>();
// ...
Stream<String> stream3 = vector.stream();
}
}方式2 : 根据Map获取流
java.util.Map接口不是Collection的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流需要分key、value或entry等情况:
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Stream;
public class Demo05GetStream {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
// ...
Stream<String> keyStream = map.keySet().stream();
Stream<String> valueStream = map.values().stream();
Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream();
}
}方式3 : 根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以Stream接口中提供了静态方法of,使用很简单:
import java.util.stream.Stream;
public class Demo06GetStream {
public static void main(String[] args) {
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
}
}备注:
of方法的参数其实是一个可变参数,所以支持数组。
4.4 常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
- 终结方法:返回值类型不再是
Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。本小节中,终结方法包括count和forEach方法。 - 非终结方法:返回值类型仍然是
Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
函数拼接与终结方法
在上述介绍的各种方法中,凡是返回值仍然为Stream接口的为函数拼接方法,它们支持链式调用;而返回值不再为Stream接口的为终结方法,不再支持链式调用。如下表所示:
| 方法名 | 方法作用 | 方法种类 | 是否支持链式调用 |
|---|---|---|---|
| count | 统计个数 | 终结 | 否 |
| forEach | 逐一处理 | 终结 | 否 |
| filter | 过滤 | 函数拼接 | 是 |
| limit | 取用前几个 | 函数拼接 | 是 |
| skip | 跳过前几个 | 函数拼接 | 是 |
| map | 映射 | 函数拼接 | 是 |
| concat | 组合 | 函数拼接 | 是 |
备注:本小节之外的更多方法,请自行参考API文档。
forEach : 逐一处理
虽然方法名字叫forEach,但是与for循环中的“for-each”昵称不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的。
void forEach(Consumer<? super T> action);该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。例如:
import java.util.stream.Stream;
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach(s->System.out.println(s));
}
}count:统计个数
正如旧集合Collection当中的size方法一样,流提供count方法来数一数其中的元素个数:
long count();该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
public class Demo09StreamCount {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s -> s.startsWith("张"));
System.out.println(result.count()); // 2
}
}filter:过滤
可以通过filter方法将一个流转换成另一个子集流。方法声明:
Stream<T> filter(Predicate<? super T> predicate);该接口接收一个Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
基本使用
Stream流中的filter方法基本使用的代码如:
public class Demo07StreamFilter {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.filter(s -> s.startsWith("张"));
}
}在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
limit:取用前几个
limit方法可以对流进行截取,只取用前n个。方法签名:
Stream<T> limit(long maxSize);参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
import java.util.stream.Stream;
public class Demo10StreamLimit {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.limit(2);
System.out.println(result.count()); // 2
}
}skip:跳过前几个
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流:
Stream<T> skip(long n);如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
import java.util.stream.Stream;
public class Demo11StreamSkip {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.skip(2);
System.out.println(result.count()); // 1
}
}
map:映射
如果需要将流中的元素映射到另一个流中,可以使用map方法。方法签名:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
基本使用
Stream流中的map方法基本使用的代码如:
import java.util.stream.Stream;
public class Demo08StreamMap {
public static void main(String[] args) {
Stream<String> original = Stream.of("10", "12", "18");
Stream<Integer> result = original.map(s->Integer.parseInt(s));
}
}这段代码中,map方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为Integer类对象)。
concat:组合
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat:
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)备注:这是一个静态方法,与
java.lang.String当中的concat方法是不同的。
该方法的基本使用代码如:
import java.util.stream.Stream;
public class Demo12StreamConcat {
public static void main(String[] args) {
Stream<String> streamA = Stream.of("张无忌");
Stream<String> streamB = Stream.of("张翠山");
Stream<String> result = Stream.concat(streamA, streamB);
}
}4.5 Stream综合案例
现在有两个ArrayList集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)依次进行以下若干操作步骤:
- 第一个队伍只要名字为3个字的成员姓名;
- 第一个队伍筛选之后只要前3个人;
- 第二个队伍只要姓张的成员姓名;
- 第二个队伍筛选之后不要前2个人;
- 将两个队伍合并为一个队伍;
- 根据姓名创建
Person对象; - 打印整个队伍的Person对象信息。
两个队伍(集合)的代码如下:
public class DemoArrayListNames {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("老子");
one.add("庄子");
one.add("孙子");
one.add("洪七公");
List<String> two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("张三丰");
two.add("赵丽颖");
two.add("张二狗");
two.add("张天爱");
two.add("张三");
// ....
}
}而Person类的代码为:
public class Person {
private String name;
public Person() {}
public Person(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{name='" + name + "'}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}传统方式
使用for循环 , 示例代码:
public class DemoArrayListNames {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
// ...
List<String> two = new ArrayList<>();
// ...
// 第一个队伍只要名字为3个字的成员姓名;
List<String> oneA = new ArrayList<>();
for (String name : one) {
if (name.length() == 3) {
oneA.add(name);
}
}
// 第一个队伍筛选之后只要前3个人;
List<String> oneB = new ArrayList<>();
for (int i = 0; i < 3; i++) {
oneB.add(oneA.get(i));
}
// 第二个队伍只要姓张的成员姓名;
List<String> twoA = new ArrayList<>();
for (String name : two) {
if (name.startsWith("张")) {
twoA.add(name);
}
}
// 第二个队伍筛选之后不要前2个人;
List<String> twoB = new ArrayList<>();
for (int i = 2; i < twoA.size(); i++) {
twoB.add(twoA.get(i));
}
// 将两个队伍合并为一个队伍;
List<String> totalNames = new ArrayList<>();
totalNames.addAll(oneB);
totalNames.addAll(twoB);
// 根据姓名创建Person对象;
List<Person> totalPersonList = new ArrayList<>();
for (String name : totalNames) {
totalPersonList.add(new Person(name));
}
// 打印整个队伍的Person对象信息。
for (Person person : totalPersonList) {
System.out.println(person);
}
}
}运行结果为:
Person{name='宋远桥'}
Person{name='苏星河'}
Person{name='洪七公'}
Person{name='张二狗'}
Person{name='张天爱'}
Person{name='张三'}Stream方式
等效的Stream流式处理代码为:
public class DemoStreamNames {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
// ...
List<String> two = new ArrayList<>();
// ...
// 第一个队伍只要名字为3个字的成员姓名;
// 第一个队伍筛选之后只要前3个人;
Stream<String> streamOne = one.stream().filter(s -> s.length() == 3).limit(3);
// 第二个队伍只要姓张的成员姓名;
// 第二个队伍筛选之后不要前2个人;
Stream<String> streamTwo = two.stream().filter(s -> s.startsWith("张")).skip(2);
// 将两个队伍合并为一个队伍;
// 根据姓名创建Person对象;
// 打印整个队伍的Person对象信息。
Stream.concat(streamOne, streamTwo).map(s-> new Person(s)).forEach(s->System.out.println(s));
}
}运行效果完全一样:
Person{name='宋远桥'}
Person{name='苏星河'}
Person{name='洪七公'}
Person{name='张二狗'}
Person{name='张天爱'}
Person{name='张三'}4.6 收集Stream结果
对流操作完成之后,如果需要将其结果进行收集,例如获取对应的集合、数组等,如何操作?
收集到集合中
Stream流提供collect方法,其参数需要一个java.util.stream.Collector<T,A, R>接口对象来指定收集到哪种集合中。幸运的是,java.util.stream.Collectors类提供一些方法,可以作为Collector接口的实例:
public static <T> Collector<T, ?, List<T>> toList():转换为List集合。public static <T> Collector<T, ?, Set<T>> toSet():转换为Set集合。
下面是这两个方法的基本使用代码:
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo15StreamCollect {
public static void main(String[] args) {
Stream<String> stream = Stream.of("10", "20", "30", "40", "50");
List<String> list = stream.collect(Collectors.toList());
Set<String> set = stream.collect(Collectors.toSet());
}
}收集到数组中
Stream提供toArray方法来将结果放到一个数组中,由于泛型擦除的原因,返回值类型是Object[]的:
Object[] toArray();其使用场景如:
import java.util.stream.Stream;
public class Demo16StreamArray {
public static void main(String[] args) {
Stream<String> stream = Stream.of("10", "20", "30", "40", "50");
Object[] objArray = stream.toArray();
}
}5.接口的默认方法和静态方法
5.1 默认方法
在Java8之前,接口中只能包含抽象方法。那么这有什么样弊端呢?比如,想再Collection接口中添加一个spliterator抽象方法,那么也就意味着之前所有实现Collection接口的实现类,都要重新实现spliterator这个方法才行。而接口的默认方法就是为了解决接口的修改与接口实现类不兼容的问题,作为代码向前兼容的一个方法。
那么如何在接口中定义一个默认方法呢?来看下JDK中Collection中如何定义spliterator方法的:
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}可以看到定义接口的默认方法是通过default关键字。因此,在Java8中接口能够包含抽象方法外还能够包含若干个默认方法(即有完整逻辑的实例方法)。
public interface IAnimal {
default void breath(){
System.out.println("breath!");
};
}
public class DefaultMethodTest implements IAnimal {
public static void main(String[] args) {
DefaultMethodTest defaultMethod = new DefaultMethodTest();
defaultMethod.breath();
}
}输出结果为:breath!
问题
可以看出IAnimal接口中有由default定义的默认方法后,那么其实现类DefaultMethodTest也同样能够拥有实例方法breath。但是如果一个类继承多个接口,多个接口中有相同的方法就会产生冲突该如何解决?实际上默认方法的改进,使得java类能够拥有类似多继承的能力,即一个对象实例,将拥有多个接口的实例方法,自然而然也会存在方法重复冲突的问题。
下面来看一个例子:
public interface IDonkey{
default void run() {
System.out.println("IDonkey run");
}
}
public interface IHorse {
default void run(){
System.out.println("Horse run");
}
}
public class DefaultMethodTest implements IDonkey,IHorse {
public static void main(String[] args) {
DefaultMethodTest defaultMethod = new DefaultMethodTest();
defaultMethod.breath();
}
}定义两个接口:IDonkey和IHorse,这两个接口中都有相同的run方法。DefaultMethodTest实现了这两个接口,由于这两个接口有相同的方法,因此就会产生冲突,不知道以哪个接口中的run方法为准,编译会出错:inherits unrelated defaults for run.....
解决办法
针对由默认方法引起的方法冲突问题,只有通过重写冲突方法,并方法绑定的方式,指定以哪个接口中的默认方法为准。
public class DefaultMethodTest implements IAnimal,IDonkey,IHorse {
public static void main(String[] args) {
DefaultMethodTest defaultMethod = new DefaultMethodTest();
defaultMethod.run();
}
@Override
public void run() {
IHorse.super.run();
}
}DefaultMethodTest重写了run方法,并通过 IHorse.super.run();指定以IHorse中的run方法为准。
5.2 静态方法
在Java8中还有一个特性就是,接口中还可以声明静态方法,如下例:
private interface DefaulableFactory {
// Interfaces now allow static methods
static Defaulable create( Supplier< Defaulable > supplier ) {
return supplier.get();
}
}下面的代码片段整合了默认方法和静态方法的使用场景:
public static void main( String[] args ) {
Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new );
System.out.println( defaulable.notRequired() );
defaulable = DefaulableFactory.create( OverridableImpl::new );
System.out.println( defaulable.notRequired() );
}这段代码的输出结果如下:
Default implementation
Overridden implementation