本文最后更新于 66 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
分布式消息队列kafka概述
一.kafka的基础架构
1.kafka概述
Apache Kafka是一个开放源代码的分布式事件流平台,成千上万的公司使用它来实现高性能数据管道,流分析,数据集成和关键任务应用程序。
kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于日志分析,大数据实时处理领域。
kafka官方地址:
http://kafka.apache.org/
有很多公司在使用kafka:
http://kafka.apache.org/powered-by
kafka的下载地址:(下载时一定要注意观察该版本的摘要信息哟~)
http://kafka.apache.org/downloads
kafka的官方使用文档:
http://kafka.apache.org/documentation/
2.kafka基础架构概述
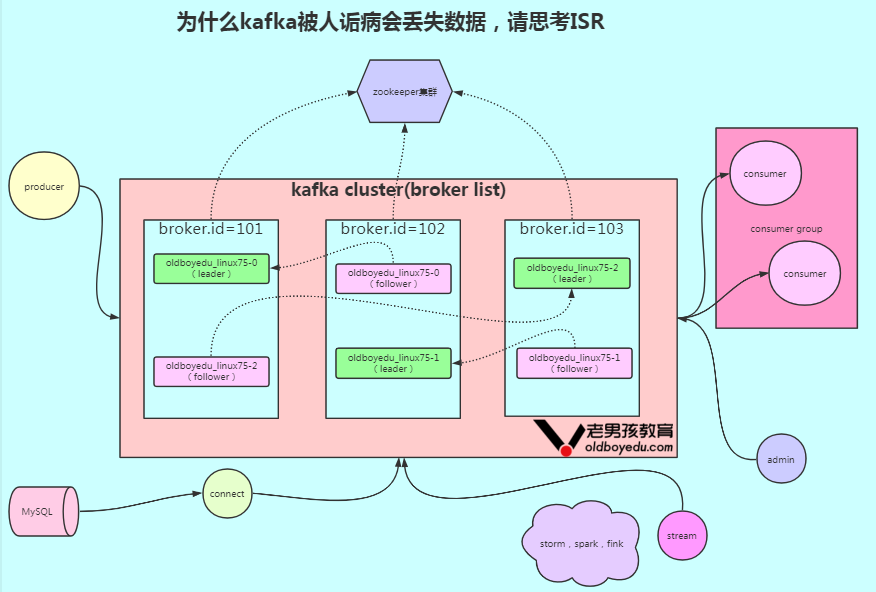
kafka的架构图如下所示。
有关kakfa相关的术语如下所示:
Producer:
消息生产者,就是向kafka broker发消息的客户端。
Consumer:
消息消费者,向kafka broker取消息的客户端。
Consumer Group(简称"CG"):
消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,消费者组之间互不影响。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
Broker:
一台kafka服务器就是一个broker,一个集群由多个broker组成。一个broker可以容纳多个topic。
Topic:
可以理解为一个队列,生产者和消费者面向的都是一个topic。
Parition:
为了实现扩展性,一个非常大的topic可以分不到多个broker(即服务器)上,一个topic可以分为多个pairtition,每个partition是一个有序的队列。
Replica:
副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
leader:
每个分区多个副本为"主",生产者发送数据的对象,以及消费者消费数据的对象都是leader。
follower:
每个分区多个副本中的"从",实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
温馨提示:
(1)kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
(2)topic是逻辑上的概念,而partition是物理上的概念,每个paritition对应于一个log文件,该log文件中存储的就是producer生产的数据;
(3)producer生产的数据会被不断追加到该log文件末尾,且每条数据都有自己的offset;
(4)消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费;
3.kafka文件存储机制
kafka文件存储机制如下左图所示。
温馨提示:
(1)由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,kafka采取了分片和索引机制,将每个partition分为多个segment;
(2)每个segment对应两个文件,即"*.index"文件和"*.log"文件,这些文件位于一个文件夹下,该文件夹的命名规则为: "topic名称 + 分区序号",如下所示:
[root@kafka101.oldboyedu.com ~]# ll /oldboyedu/data/kafka/ # 查看kafka数据的存储路径。
总用量 12
drwxr-xr-x 10 root root 4096 5月 8 14:57 logs1
drwxr-xr-x 10 root root 4096 5月 8 14:57 logs2
drwxr-xr-x 10 root root 4096 5月 8 14:57 logs3
[root@kafka101.oldboyedu.com ~]# ll /oldboyedu/data/kafka/logs1/ # 查看某一个数据路径下的部分数据
总用量 20
-rw-r--r-- 1 root root 4 5月 7 12:04 cleaner-offset-checkpoint
drwxr-xr-x 2 root root 141 5月 7 15:20 __consumer_offsets-13
drwxr-xr-x 2 root root 141 5月 7 15:20 __consumer_offsets-19
drwxr-xr-x 2 root root 141 5月 7 15:20 __consumer_offsets-22
drwxr-xr-x 2 root root 141 5月 7 15:20 __consumer_offsets-25
drwxr-xr-x 2 root root 141 5月 7 15:20 __consumer_offsets-46
drwxr-xr-x 2 root root 141 5月 7 15:03 demo2021-1
-rw-r--r-- 1 root root 4 5月 8 14:57 log-start-offset-checkpoint
-rw-r--r-- 1 root root 90 5月 7 10:51 meta.properties
drwxr-xr-x 2 root root 141 5月 7 12:17 myNginx-0
drwxr-xr-x 2 root root 141 5月 7 14:52 myNginx-6
-rw-r--r-- 1 root root 161 5月 8 14:57 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 161 5月 8 14:57 replication-offset-checkpoint
[root@kafka101.oldboyedu.com ~]#
[root@kafka101.oldboyedu.com ~]# ll /oldboyedu/data/kafka/logs1/myNginx-0/ # 查看名为"myNginx"的topic编号为0的分区数据信息如下所示。
总用量 20488
-rw-r--r-- 1 root root 10485760 5月 7 12:17 00000000000000000000.index # 存储下面的"*.log"文件的索引信息
-rw-r--r-- 1 root root 77 5月 7 17:18 00000000000000000000.log # 存储的已经被序列化的数据
-rw-r--r-- 1 root root 10485756 5月 7 12:17 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 5月 7 12:17 leader-epoch-checkpoint
[root@kafka101.oldboyedu.com ~]#
(3)"*.index"文件和"*.log"文件以当前segment的第一条消息的offset命名,下右图为"*.index"文件和"*.log"文件的结构示意图。
二.kafka生产者
1.分区的原因
(1)可以提高数据的负载均衡能力,如果一个topic只有一个partition,那么所有的消息都只能在一个broker,但一个topic有多个partition时,就可以有效的解决数据的负载均衡啦;
(2)可以提高并发,因为可以用以partition为单位进行读写了。2.如何选定分区数量的分区策略
为topic选定分区数量并不是一件可有可无的事情,在进行数量选择时,需要考虑如下几个因素:
(1)topic需要达到多大的吞吐量?例如,是希望每秒钟写入100KB的数据还是1GB数据呢?
(2)从单个分区读取数据的最大吞吐量是多少?每个分区一般都会有一个消费者,如果你知道消费者将数据写入数据库的速度不会超过50MB,那么你也该知道,从一个分区读取数据的吞吐量不需要超过每秒50MB。
(3)可以通过类似的方法估算生产者向单个分区写入数据的吞吐量,不过生产者的速度一般比消费者快得多,所以最好为生产者多估算一些吞吐量。
(4)每个broker包含的分区个数,可用的磁盘空间和网络带宽。
(5)如果消息是按照不同的键来写入分区的,那么为已有的主题新增分区就会很困难;
(6)单个broker对分区个数是有限制的,因为分区越多,占用的内存越多,完成leader选举需要的时间也越长;
很显然,综合考虑以上几个因素,你需要很多分区,但不能太多。如果你估算出topic的吞吐量和消费者吞吐量,可以用topic吞吐量除以消费者算出分区的个数。
也就是说,如果每秒钟要从topic上写入和读取1GB的数据,并且每个消费者每秒钟可以处理50MB的数据,那么至少需要20个分区,这样就可以让20个消费者同时读取这些分区,从而达到每秒钟1GB的吞吐量。
选择分区数的粗略公式基于吞吐量。您可以衡量在单个分区上可以实现的整体产量,将其用于生产(称为p)和消费(称为c)。假设您的目标吞吐量为t。然后,您至少需要有max(t / p,t / c)个分区。
推荐阅读:
https://www.confluent.io/blog/how-choose-number-topics-partitions-kafka-cluster/
3.生产者提交分区的原则
我们需要将producer发送的数据封装成一个ProducerRecord对象。
(1)指明partition的情况下,直接将指明的值直接作为partition值;
(2)如下所示,没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到要提交的partition编号;
Math.abs(key.hashCode()) % numPartitions
(3)既没有partition值有没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法;
4.数据可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
何时发送ack?
确保有follower与leader同步完成,leader再发送ack,这样才能保证leader挂掉之后,能在follower中选举出新的leader。
多少个follower同步完成之后发送ack?请思考以下两种方案:
(1)半数以上的follower同步完成,即可发送ack;
优点:
延迟低。
缺点:
选举新的leader时,容忍N台节点的故障,需要2N+1个副本。
举例:
假设N为1,容忍1台节点故障,则需要3个副本,因为此时只有半数以上的副本数是完全同步的,理想情况下是2个副本是数据同步的,这样就算挂掉一个leader副本,还有一个副本立马能顶上去。
(2)全部的follower同步完成,才可以发送ack;
优点:
选举新的leader时,容忍N台节点的故障,需要N+1个副本。
缺点:
延迟高。
举例:
假设N为1,容忍1台节点故障,则需要2个副本,因为此时全部的副本是完全同步的,理想情况下2个副本是数据同步的,这样就算挂掉一个副本,还有一个副本立马能顶上去。
kafka选择了第二种方案,原因如下:
(1)同样容忍N台节点故障,第一种方案需要2N+1个副本,而第二种方案只需要N+1个副本,而kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
(2)虽然第二种方案的网络延迟会比较高,但网络延迟对kafka的影响较小。与此同时,提出了优化策略,即ISR:
采用第二种方案之后,设想以下情景:
leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ACK,这个问题怎么解决呢?
leader维护了一个动态的in-sync replica set(ISR),意味和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给生产者发送ACK。
如果follower长时间未向leader同步数据,则该follower将被剔出ISR,该时间阈值由"replica.lag.time.max.ms"参数设定(在kafka 0.9版本之前,还有"replica.lag.max.messages"参数可以控制),leader发生故障之后,就会从ISR中选举新的leader。
ack应答机制:
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中follower全部接受成功。
所以kafka为用户提供了三种可靠型级别,用户根据对可靠性和延迟的要求进行权衡,可供选择以下acks参数配置:
0:
producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据。
1:
producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步之前leader故障,那么将会丢失数据。
-1(all):
producer等待broker的ack,partition的leader和ISR中的follower全部落盘成功后才返回ACK,但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会就造成数据重复。
该模式下值得注意的是:当ISR只有leader一个节点时,其他的follower均不在ISR中,而是被剔出到OSR,此时当leader提交ack后立刻宕机,数据也可能会丢失的,因为ISR中没有其他的follower哟~
如下图所示,描述了HW(High Watermark,高水位)和LEO(Log End Offset)的关系。
温馨提示:
为什么在kafka 0.9版本之后,"replica.lag.max.messages"参数被移除了呢?
举个例子,假设我们设置最大延迟的消息数是100,而生产者在批量写入数据时,很可能所有的follower节点的延迟消息均大于100条消息,而过段时间后,各个节点又逐渐追回消息,这会导致频繁的出现follower节点重新加入或被剔出ISR的现象。
一旦修改比较频繁,这些ISR数据都会同步到zookeeper集群中,无疑是增加了成本。
而保留的基于时间间隔来判断可以减少频繁被剔出或加入到ISR的现象哟~
推荐阅读:
http://kafka.apache.org/documentation/#upgrade_9_breaking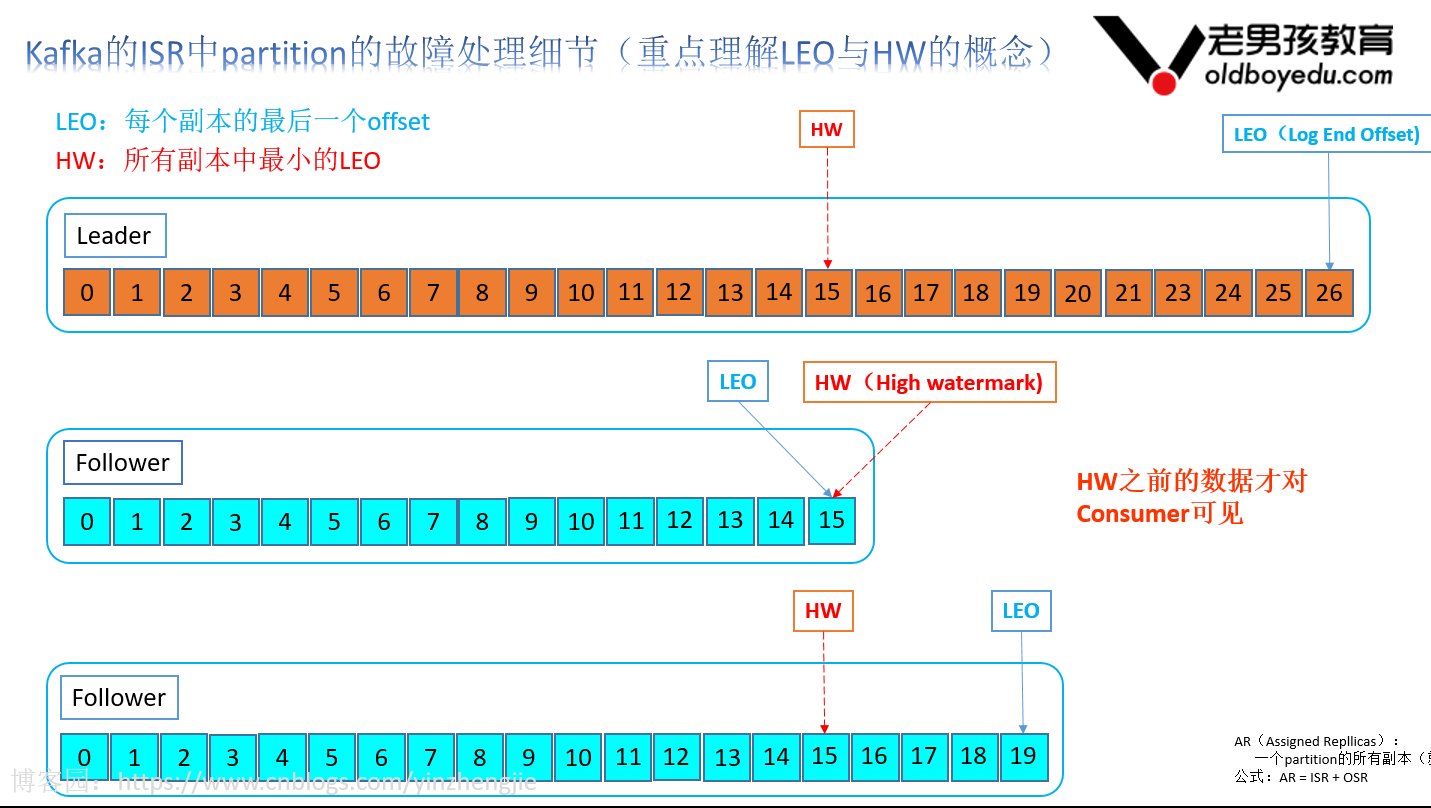
5.Exactly Once(就一次)语义(了解即可)
At Least Once(至少一次):
将服务器的ACK级别设置为"-1",即"At Least Once(至少一次)"语义。
结合前面的知识点,我们可以说严谨一点,前提是ISR中包含多个副本,如果只有一个leader,当leader挂掉后依旧会丢失数据。
At Most Once(最多一次):
将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即"At Most Once(最多一次)"语义。
这种模式理想情况下可以保证数据不重复,但无法保证数据不丢失。
Exactly Once(就一次):
对于一些非常重要的数据信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once(就一次)。
在kafka 0.11之前的版本对此是无能为力的,只能在理想情况下保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
kafka 0.11版本引入一项重大特性:幂等性。所谓的幂等性就是指producer不论向server发送多少次重复数据,server端都只会持久化一条数据,幂等性结合At Least Once语义,就构成了kafka的Exactly Once语义。
即:"At Least Once(至少一次) + 幂等性(server端去重功能) = Exactly Once "。
温馨提示:
要启用幂等性,只需要将Producer的参数中"enable.idompotence"设置为true即可。kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。
开启幂等性的producer在初始化的时候会被分配一个PID,发往同一个Partition的消息会附带Sequence Number。而Broker端会对<PID,Partition,SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条数据。
但是PID重启就会变化,同时不同的partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once(就一次)。
三.kafka消费者
1.消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
针对这一点,kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
2.分区分配策略(了解即可)
一个consumer group中有多个consumer,一个topic有多个partition,所以必然会涉及到partition的分配问题,即确定哪个partition由哪个consumer来消费。
kafka有两种分配策略,一个是RoundRobin,一个是Range。
RoundRobin策略:
工作原理:
将消费者组订阅的一个或多个主题的所有分区进行排序,而后依次将partition分发给该组的各个消费者。
优点:
轮询使不同topic的所有分区看作一个整体,分区数相对来说比较均衡的分配到同一个消费者组的各个消费者上。
缺点:
当同一个消费者组的不同消费者订阅了不同的topic时,这种方式方式就不太合适了,因为很有可能导致消费者消费到未订阅的topic。
Range策略(也是官方的默认策略):
工作原理:
将分区数和同一个消费者组的消费者数量进行取商,然后多出来的余数会随机分配到该组的某个消费者。当订阅的topic数量的分区较少时,可能还看不出明显的数据不均衡现象。
优点:
范围是订阅同一topic的所有消费者组。
缺点:
当同一个消费者组的某个消费者单独订阅了一个主题,按照range策略的话会将topic的所有分区都分配给该消费者,而该消费者所在的消费者组内的其它成员(由于没有订阅该主题)无法消费数据。
举个例子: 999个分区被100个消费者进行消费,就会出现严重的不均衡的现象!
温馨提示:
当消费者组中的消费者个数发生变化(比如消费者增加或减少),都会触发消费者分区策略进行对分区的重新分配(reblance)。
注意哈,即使同一个消费者组中新增消费者数量后,此时消费者数量已经大于订阅topic的分区数,也会触发分区的重新均衡,因为我们改变了该消费者组中的消费者数量。当然,多出来的消费者会处于空闲状态。
3.offset的维护
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
温馨提示:
kafka 0.9版本之前,consumer默认将offset保存在zookeeper中,从0.9版本开始,consumer默认将offset保存在kafka内置的一个topic中,该topic为"__consumer_offsets"。4.消费者组案例
略,有相应的章节讲解。四.kafka高效读写数据的底层原理
1.顺序写磁盘
kafka的producer生产数据,将数据顺序写入磁盘,从而优化的磁盘的写入效率.
官方有数据表明,同样的写能到600M/s,而随机写只有100K/s。这与磁盘的机械结构有关,顺序写之所以快,是因为节省去了大量磁头寻址时间。
2.零拷贝技术
如下图所示,DMA的英文拼写是"Direct Memory Access",汉语的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式。
温馨提示:
(1)JDK NIO零拷贝实现分为两种方案,即mmap和sendFile。
1>.mmap比较适合小文件读写,对文件大小有限制,一般在1.5GB~2.0GB之间;
2>.sendFile比较适合大文件传输,可以利用DMA方式,减少CPU拷贝;
(2)下图中的万兆网卡我指的是服务器的硬件网卡,但也有人喜欢使用专业术语Network Interface Controller(简称"NIC")来进行说明。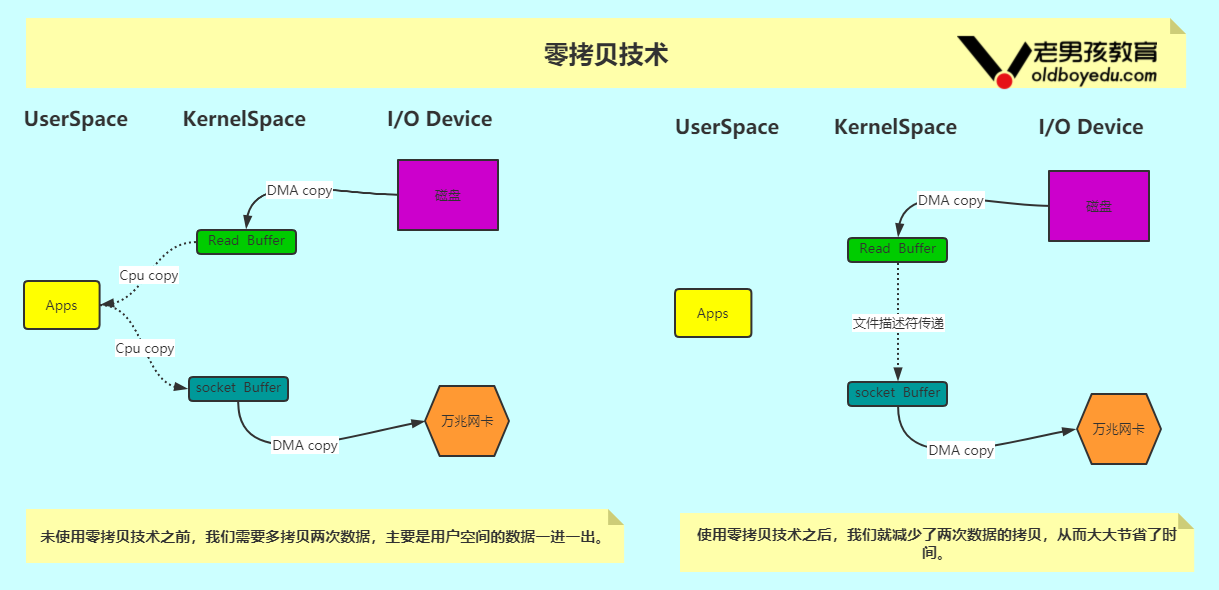
3.异步刷盘
kafka并不会将数据直接写入到磁盘,而是写入OS的cache,而后由OS实现数据的写入。
这样做的好处就是减少kafka源代码更多关于兼容各种厂商类型的磁盘驱动,而是交给更擅长和硬件打交道的操作系统来完成和磁盘的交互。
不得不说异步刷盘的确提高了效率,但也意味着带来了数据丢失的风险,假设数据已经写入到OS的cache page,但数据并未落盘之前服务器断电,很可能会导致数据的丢失。4.分布式集群
我们知道topic可以被划分多个partition,而partition可以分布在kafka集群的各个broker实例上。
分布式充分利用了各个broker节点的性能,包括但不限于CPU,内存,磁盘,网卡等。
五.zookeeper在kafka中的作用
1.partition的leader选举
partition的leader选举最简单最直观的方案是:
leader在zk上创建一个永久znode,所有Follower对此节点注册监听,当leader宕机时,此时ISR里的所有Follower会选举出新的leader,并更新该znode的数据(这一点可以参考zk的znode的"Data Version"属性)。
实际上的实现思路也是这样,只是优化了下,多了个代理控制管理类(controller)。
引入的原因是,当kafka集群业务很多,partition达到成千上万时,当broker宕机时,造成集群内大量的调整,会造成大量Watch事件被触发,Zookeeper负载会过重。zk是不适合大量写操作的。
2.kafka的controller是做什么的
kafka集群中有一个broker会被选举为Controller(这会在zk集群上创建一个临时的znode哟~),这个controller是负责管理和协调kafka集群的,其功能包括但不限于以下几点:
UpdateMetadataRequest:
更新元数据请求。
topic分区状态经常会发生变更(比如leader重新选举了或副本集合变化了等)。由于当前clients只能与分区的leader broker进行交互,那么一旦发生变更,controller会将最新的元数据广播给所有存活的broker。
具体方式就是给所有broker发送UpdateMetadataRequest请求
CreateTopics:
创建topic请求。
当前不管是通过API方式、脚本方式或是CreateTopics请求方式来创建topic,做法几乎都是在Zookeeper的/brokers/topics下创建znode来触发创建逻辑,而controller会监听该path下的变更来执行真正的"创建topic"逻辑
DeleteTopics:
删除topic请求。
和CreateTopics类似,也是通过创建Zookeeper下的/admin/delete_topics/<topic>节点来触发删除topic,controller执行真正的逻辑。
不信的话,你可以将一个已存在的topic名称创在"/admin/delete_topics/"试试看呗!
分区重分配:
即kafka-reassign-partitions.sh脚本做的事情。同样是与Zookeeper结合使用,脚本写入/admin/reassign_partitions节点来触发,controller负责按照方案分配分区。
Preferred leader分配:
preferred leader选举当前有两种触发方式:
(1)自动触发(auto.leader.rebalance.enable = true);
(2)kafka-preferred-replica-election脚本触发。两者"玩法"相同,向Zookeeper的/admin/preferred_replica_election写数据,controller提取数据执行preferred leader分配;
分区扩展:
即增加topic分区数。
标准做法也是通过kafka-reassign-partitions.sh脚本完成,不过用户可直接往Zookeeper中写数据来实现,比如直接把新增分区的副本集合写入到/brokers/topics/<topic>下,然后controller会为你自动地选出leader并增加分区。
集群扩展:
新增broker时Zookeeper中/brokers/ids下会新增znode,controller自动完成服务发现的工作
broker崩溃:
同样地,controller通过Zookeeper可实时侦测broker状态。一旦有broker挂掉了,controller可立即感知并为受影响分区选举新的leader。
ControlledShutdown:
broker除了崩溃,还能"优雅"地退出。broker一旦自行终止,controller会接收到一个ControlledShudownRequest请求,然后controller会妥善处理该请求并执行各种收尾工作
Controller leader选举:
controller必然要提供自己的leader选举以防这个全局唯一的组件崩溃宕机导致服务中断。这个功能也是通过Zookeeper的帮助实现的。
推荐阅读:
https://www.cnblogs.com/huxi2b/p/6980045.html
六.kafka事务(了解即可)
1.kafka事务概述
kafka从0.11版本开始引入了事务支持。
事务可以保证kafka在Exactly Once语义的基础上,生产和消费可以跨分区的会话,要么全部成功,要么全部失败。2.producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。
Transaction Coordinator还负责所有写入kafka的内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以的得到恢复,从而继续进行。
3.Consumer事务
上述事务机制主要从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被精确消费。
这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事物的消费可能会出现重启后被删除的情况。