本文最后更新于 481 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
docker的容器监控方案-prometheus实战篇
一.前置知识
1.监控与报警
很多小伙伴总是把监控和报警混在混在一起说,其实这是两个概念,我们需要单独理解。
监控:
监控是把行为表现展示出来,用来观察的。
报警:
报警则是当监控获取的数据发生异常并且到达了某个临界点的时候,采用各种报警媒介来通知用户(比如项目负责人,运维人员,公司领导等)。2.监控系统的设计
如果监控系统设计的不好,那么在实际工作中可能会频繁出问题。
监控系统的设计部分应该包括但不限于以下几个参考点:
(1)评估系统的业务流程,业务种类和架构系统
各个企业的产品不同,业务方向不同,程序代码不同,系统架构更不同。
因此对于各个地方的细节都需要有一定程度的认知,才可以开起设计的源头。
(2)分类出所需的监控系种类:
一般可分为业务级别监控,系统级别监控,网络监控,程序代码监控,日志监控,用户行为分析监控和其它种类监控。
(3)监控技术的方案选择
各种监控软件层出不穷,开源的,商业的,自行开发的,几百种可选方案。
运维架构师凭借一些因素开始选材,针对企业的结构特点,大小,种类,人员多少等等选择合适的技术方案。
(4)监控的人员安排
运维团队的任务划分,责任到人,分块进行。
开发团队的配合人员选取,很多监控涉及的工作,都需要跟开发人员配合才开源进行。
(5)其它
3.监控系统的分类
接下来我们对监控系统的分类做简单的概要说明,让大家对这些数据有一个大致的印象。
业务监控:
可以包含用户访问QPS,DAU日活,访问状态(可以基于返回状态码),业务接口(注册,登录,聊天,上传,留言,短信,搜索等),产品转换率,充值额度,用户投诉等等这些宏观的概念(公司上层领导比较关心,因此我们运维人员应该将其放在第一位)。
系统监控:
主要是跟操作系统相关的基本监控项,比如CPU,内存,硬盘,IO,TCP链接,流量等等。
网络监控:
对网络状态的监控(交换机,路由器,防火墙,VPN等),互联网公司必不可少,但是很多时候又被忽略,例如:IDC机房内网之间,外网之间的丢包率,延迟等等。
日志监控:
监控中的重头戏,往往单独设计和搭建,全部种类的日志都有需要采集,常见的解决方案如Elstic stack(有免费版),Splunk(付费版)等。
程序监控:
一般需要和开发人员配合,程序中嵌入各种接口,直接获取数据或者特质的日志格式。
二.prometheus概述
1.什么是prometheus
Prometheus是一个开源系统监控和警报工具包,最初是在SoundCloud上构建的。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发者和用户社区。
Prometheus现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并澄清项目的治理结构,Prometheus于2016年加入云原生计算基金会,作为继Kubernetes之后的第二个托管项目。
我们可以简单的理解Prometheus是一个监控系统同时也是一个时间序列数据库。
推荐阅读:
官网地址:
https://prometheus.io
官方文档:
https://prometheus.io/docs/introduction/overview/
GitHub地址:
https://github.com/prometheus
2.prometheus的历史
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。
2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。
2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
推荐阅读:
https://www.prometheus.wang/quickstart/why-monitor.html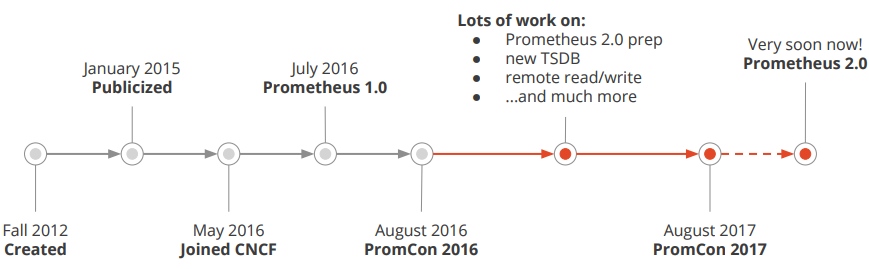
3.为什么要学习prometheus
可能你在网上看到了有网友使用zabbix监控docker和kubernetes的解决方案,并行之有效,那咱们为啥还要学习prometheus这个监控系统呢?
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。
相比于传统监控系统Prometheus具有以下优点:
(1)易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
(2)监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
(3)时间序列(time series)
所谓的时间序列(time series)指的是一系列有序的数据,通常是指等时间间隔的采样数据,说白了就是分为X和Y轴,其中X轴是按照时间间隔进行推进,而Y轴是有序的数字。
(4)强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。
(5)强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
1>.在过去一段时间中95%应用延迟时间的分布范围?
2>.预测在4小时后,磁盘空间占用大致会是什么情况?
4>.CPU占用率前5位的服务有哪些?(过滤)
(6)高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:数以百万的监控指标和每秒处理数十万的数据点。而zabbix对此相对来说就有点吃力了;
(7)可扩展(支持集群)
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
(8)易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: "Java","JMX","Python","Go","Ruby",".Net", "Node.js"等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:"Graphite", "Statsd", "Collected", "Scollector", "muini", "Nagios"等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:"JMX", "CloudWatch", "EC2","MySQL","PostgresSQL", "Haskell", "Bash", "SNMP", "Consul", "Haproxy", "Mesos", "Bind", "CouchDB", "Django", "Memcached", "RabbitMQ", "Redis", "RethinkDB", "Rsyslog"等等。
(9)可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。
同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。
最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
(10)开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
Prometheus除了上述说到的优点,其实也有以下不足之处:
(1)学习成本太大,尤其是其独有的数学命令行,学习起来很吃力,而且全是英文文档;
(2)对磁盘资源也是耗费的较大,这个具体要看监控的集群量和监控项的多少和保存时间的长短;
(3)有网友称在1.x版本中可能会发生数据丢失的风险,因此生产环境中建议大家使用较新的2.x发行版;
温馨提示:
(1)zabbix采用的是MySQL数据库,Prometheus采用的是时间序列数据库,由于监控数据并不需要更新,监控数据会存在大量的写入和查询,其底层实现会更高,具体细节原理可自行查阅资料,Prometheus是支持外部数据库存储的,但我觉得完全没有必要在生产环境中这样做;
(2)如果上述10点还不足以打动你学习Prometheus,那我再说一点比较现实的,国内目前很多中小企业都在使用Prometheus监控docker,Kubernetes,学习它有助于咱们找工作。
4.prometheus的使用场景
适用的场景(When does it fit?)
Prometheus适用于记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的架构。在微服务的世界中,它对多维数据收集和查询的支持是一个特殊的优势。
Prometheus是为可靠性而设计的,它是您在中断期间访问的系统,让您能够快速诊断问题。每个 Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。当基础架构的其他部分损坏时,您可以依赖它,并且您无需设置大量基础架构即可使用它。(请记住该点,这是优点也是缺点哟~)
不适用的场景(When does it not fit?)
如上所示,Prometheus重视可靠性。即使在出现故障的情况下,您也可以随时查看有关系统的可用统计信息。
如果您需要100%的准确性,例如按请求计费,Prometheus不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用Prometheus进行其余的监控。
推荐阅读:
https://prometheus.io/docs/introduction/overview/#when-does-it-fit
https://prometheus.io/docs/introduction/overview/#when-does-it-not-fit5.prometheus的宏观架构图:star:
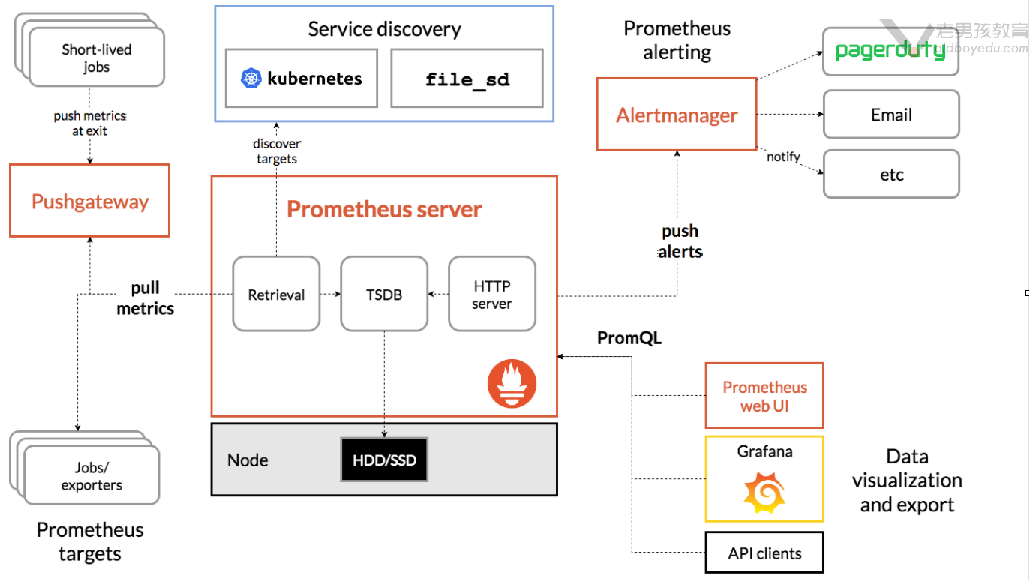
如下图所示,展示了普罗米修斯(prometheus)的建筑和它的一些生态系统组成部分。
(1)Prometheus server:
prometheus的服务端,负责收集指标和存储时间序列数据,并提供查询接口。
(2)exporters:
如果想要监控,前提是能获取被监控端数据,并且这个数据格式必须遵循Prometheus数据模型,这样才能识别和采集,一般使用exporter数据采集器(类似于zabbix_agent端)提供监控指标数据。
exporter数据采集器,除了官方和GitHub提供的常用组件exporter外,我们也可以为自己自研的产品定制exporters组件哟。
(3)Pushgateway:
短期存储指标数据,主要用于临时性的任务。比如备份数据库任务监控等。
本质上我们可以理解为Pushgateway可以帮咱们监控自定义的监控项,这需要咱们自己编写脚本来推送到Pushgateway端,而后由Prometheus server从Pushgateway去pull监控数据。
换句话说,请不要被官方的架构图蒙骗了,咱们完全可以基于Pushgateway来监控咱们自定义的监控项哟,这些监控项完全可以是长期运行的呢!
(4)Service discovery:
服务发现,例如我们可以配置动态的服务监控,无需重启Prometheus server实例就能实现动态监控。
(5)Alertmanager:
支持报警功能,比如可以支持基于邮件,微信,钉钉报警。
据网友反馈该组件在生产环境中存在缺陷,因此我们可以考虑使用Grafana来展示并实现报警功能。
(6)Prometheus Web UI
Prometheus比较简单的Web控制台,通常我们可以使用grafana来集成做更漂亮的Web展示哟。
温馨提示:
大多数Prometheus组件都是用Go编写的,这使得它们易于构建和部署为静态二进制文件。
6.prometheus软件下载地址
官方的下载地址:
https://prometheus.io/download/
推荐阅读:
https://prometheus.io/docs/instrumenting/exporters/
https://github.com/danielqsj/kafka_exporter
https://github.com/prometheus-community/elasticsearch_exporter
https://github.com/oliver006/redis_exporter
https://github.com/prometheus/mysqld_exporter
https://github.com/nlighten/tomcat_exporter
https://github.com/nginxinc/nginx-prometheus-exporter
https://github.com/dabealu/zookeeper-exporter
...

三.部署prometheus server监控软件
1.同步集群时间
我们在安装prometheus server监控软件之前,需要同步集群时间。
由于prometheus是一个时间序列数据库,因此其对系统时间的准确性要求很高,必须保证本机时间实时同步。
关于集群时间同步,此处我就不浪费口舌了,在以前的章节中我们已经介绍过了,请自行实现。
仅供参考:
yum -y install ntpdate && ntpdate ntp1.aliyun.com2.下载prometheus软件包
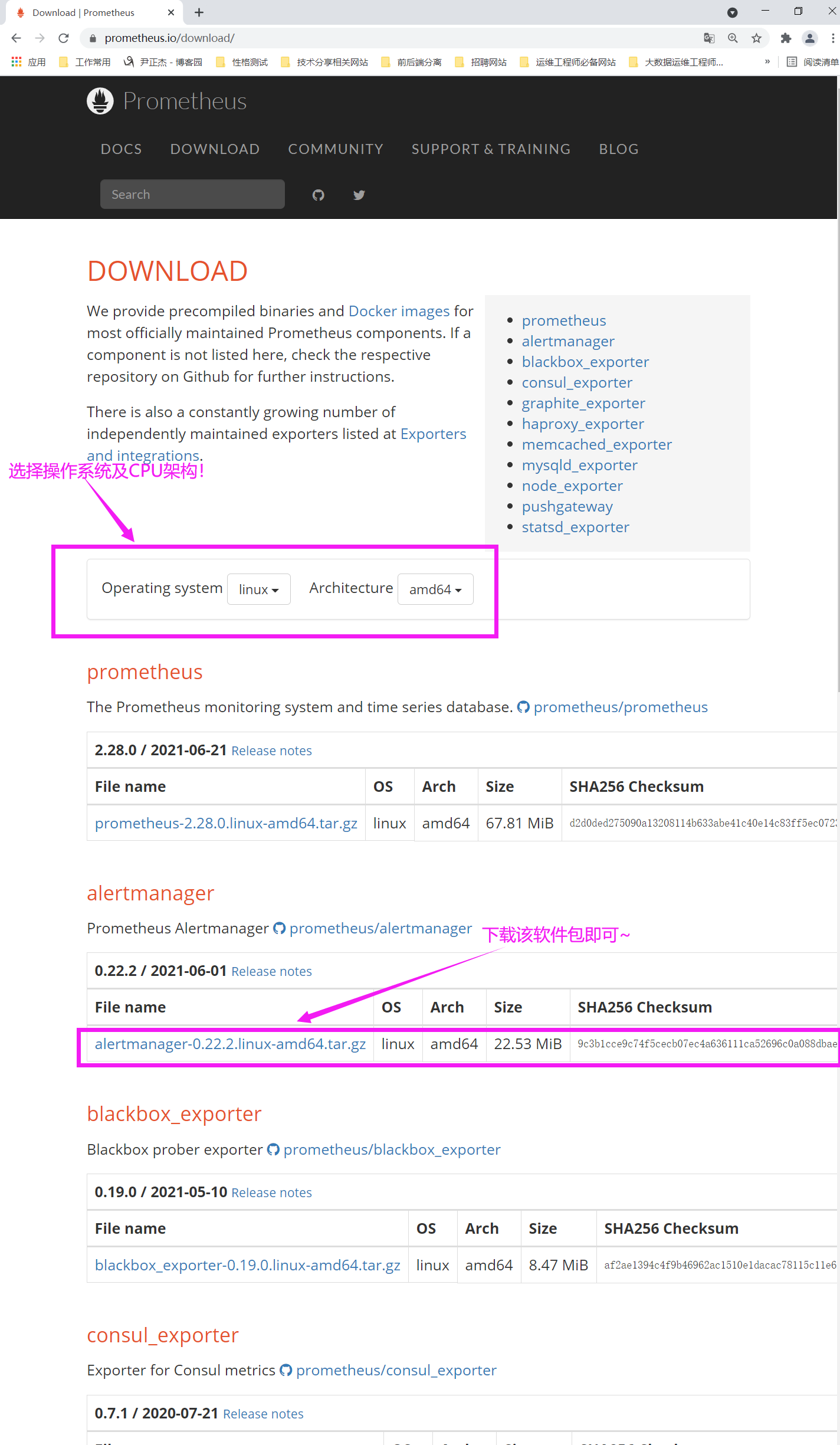
如下图所示,我们在下载软件之前,可以先选择prometheus将要安装的操作系统及其CPU架构.
推荐阅读:
https://prometheus.io/download/
3.安装prometheus软件包
[root@docker201.oldboyedu.com /oldboyedu/softwares]# tar xf prometheus-2.28.0.linux-amd64.tar.gz -C /oldboy/softwares/
[root@docker201.oldboyedu.com /oldboyedu/softwares]#
[root@docker201.oldboyedu.com /oldboyedu/softwares]# cd /oldboy/softwares/
[root@docker201.oldboyedu.com /oldboy/softwares]#
[root@docker201.oldboyedu.com /oldboy/softwares]#
[root@docker201.oldboyedu.com /oldboy/softwares]# ln -sv prometheus-2.28.0.linux-amd64 prometheus
"prometheus" -> "prometheus-2.28.0.linux-amd64"
[root@docker201.oldboyedu.com /oldboy/softwares]#
温馨提示:
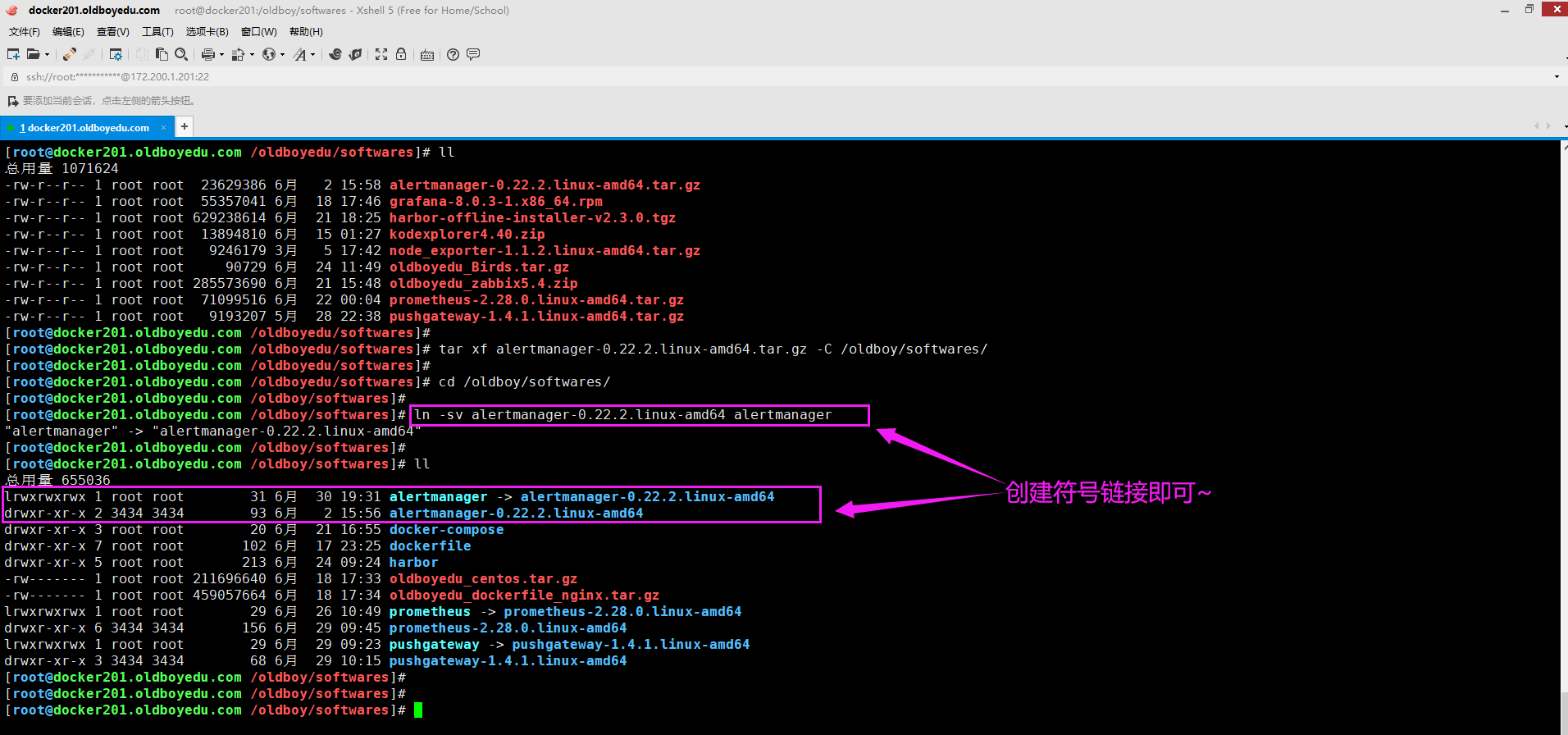
如下图所示,建议大家创建符号链接,不仅仅可以输入更短的路径,而是方便版本管理。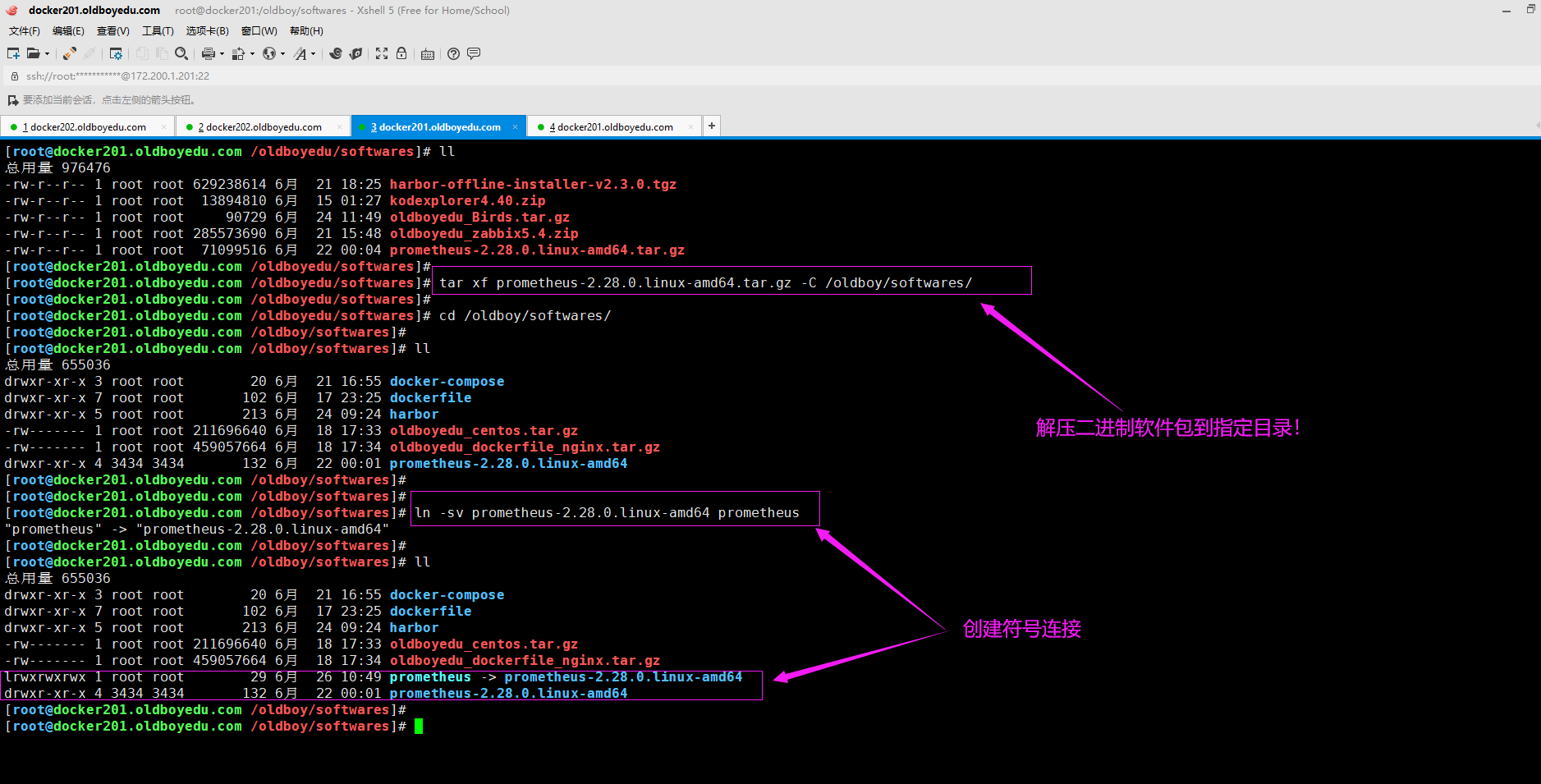
4.查看prometheus程序的帮助信息
[root@docker201.oldboyedu.com /oldboy/softwares/prometheus]# ./prometheus --help
温馨提示:
启动时若不指定配置文件,则会使用其默认的配置参数哟:
"--config.file"的默认值为"prometheus.yml"
"--web.listen-address"的默认值为"0.0.0.0:9090"
"--web.max-connections"的默认值为"512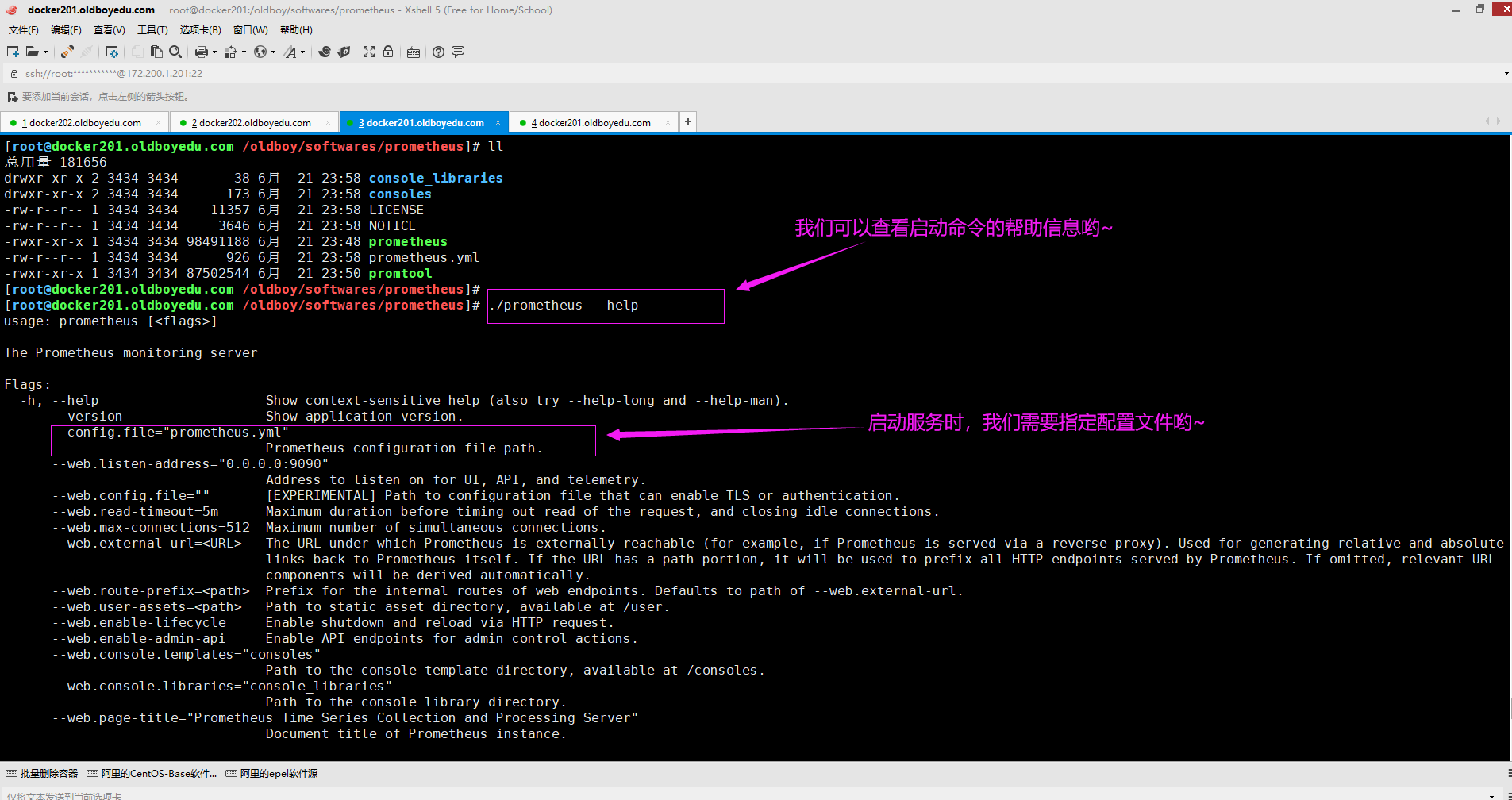
5.前台启动prometheus服务
[root@docker201.oldboyedu.com /oldboy/softwares/prometheus]# ./prometheus
生产环境中启动参数参考案例:
--web.listen-address="0.0.0.0:9090"
--web.read-timeout=5m
请求连接最大的等待时间,防止太多的空闲链接占用资源。
--web.max-connections=10
最大网络连接数。
--storage.tsdb.path="data/"
指定本地存储数据的路径,这个参数很重要,请将指定的路径有足够的存储空间。不要随便放在一个目录,比如某些开发随意将数据放在根目录下,导致根目录存储容量100%,从而见解导致服务(我在生产环境中就有一个开发犯过这样的错误,导致tomcat无法访问)无法访问,甚至连sshd服务也无法对外提供服务。
--storage.tsdb.retention=15d
prometheus开始采集监控数据后,会存在内存和硬盘中。
对于保留期限的设置很重要,太长的话硬盘和内存吃不消,太短的话要查看历史数据就没有了,企业中设置15天(保留最近2个星期的数据)比较合适。
--query.timeout=2m
可以防止用户查询语句出现了慢查询超过2分钟后会自动中止PQL的执行哟~
--query.max-concurrency=20
防止太多的用户并发查询。
温馨提示:
(1)如下图所示,我们启动时可以使用默认配置参数,启动服务时会阻塞当前终端。
(2)如果想要后台启动可以使用nohup工具实现后台启动;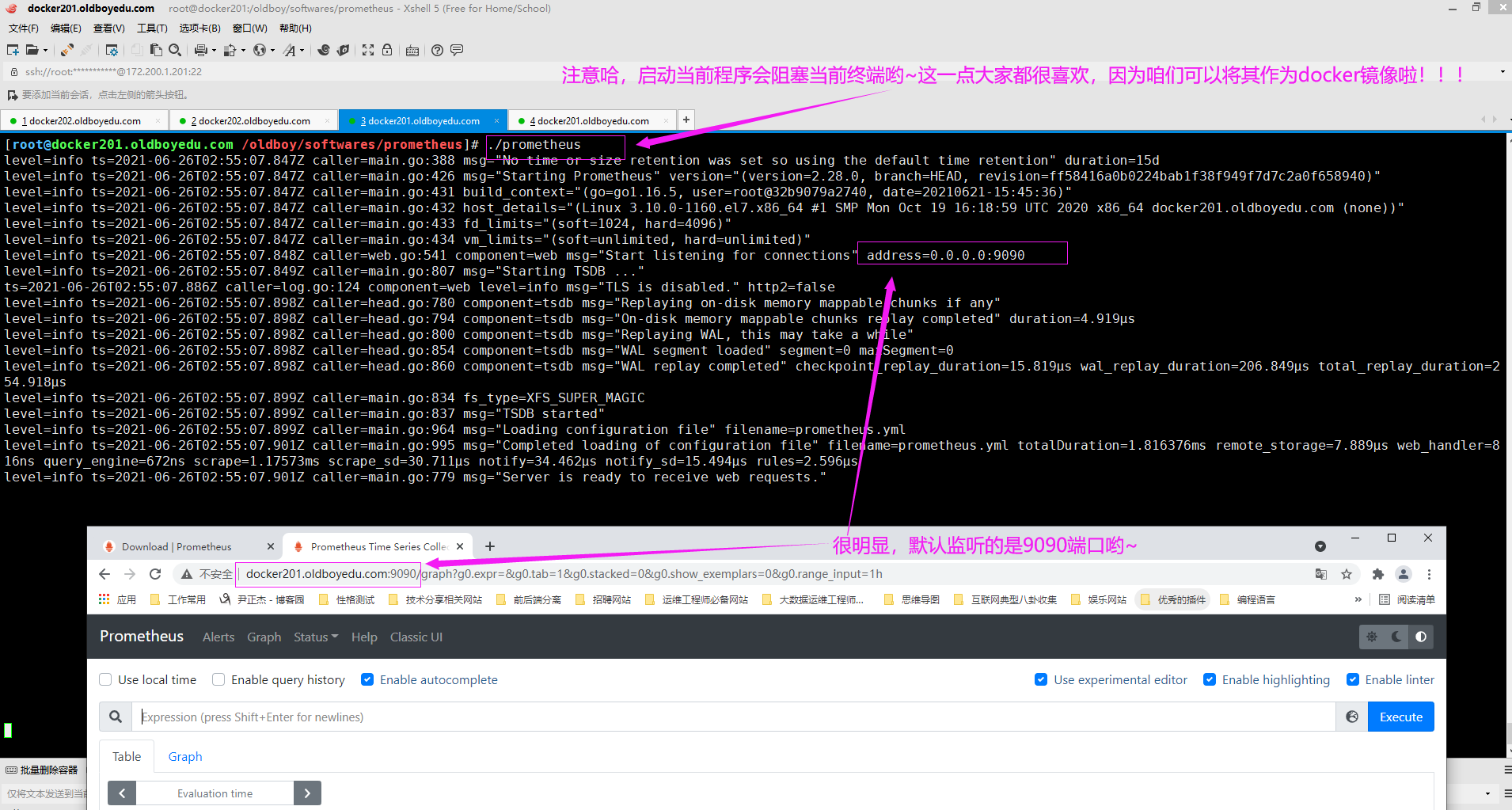
6.后台启动prometheus服务
[root@docker201.oldboyedu.com ~]# vim /etc/profile.d/prometheus.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# cat /etc/profile.d/prometheus.sh
#!/bin/bash
export PROMETHEUS_HOME=/oldboy/softwares/prometheus
export PATH=$PATH:$PROMETHEUS_HOME
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# source /etc/profile.d/prometheus.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# nohup prometheus --config.file="$PROMETHEUS_HOME/prometheus.yml" &>>/var/log/oldboyedu_prometheus.log &
[1] 2728
[root@docker201.oldboyedu.com ~]#
除了使用nohup工具之外,我们也可以使用"screen"工具将其放在后台管理哟:
(1)screen -ls
查看放在后台的进程。存在"Attached"和"Detached"两种进程。
(2)screen
开启一个终端,可以运行一些命令,比如ping,然后按"ctrl + a + d"直接将当前终端放在后台。"crtl + d"则表示直接退出当前终端。
(3)screen -r ID
进入到某个终端ID,建议进入到标记有"Detached"的终端哟~
温馨提示:
当screen管理几十个后台任务时,可能就有点可读性较差了,此时我们也可以使用daemonize将其放入后台进行管理哟~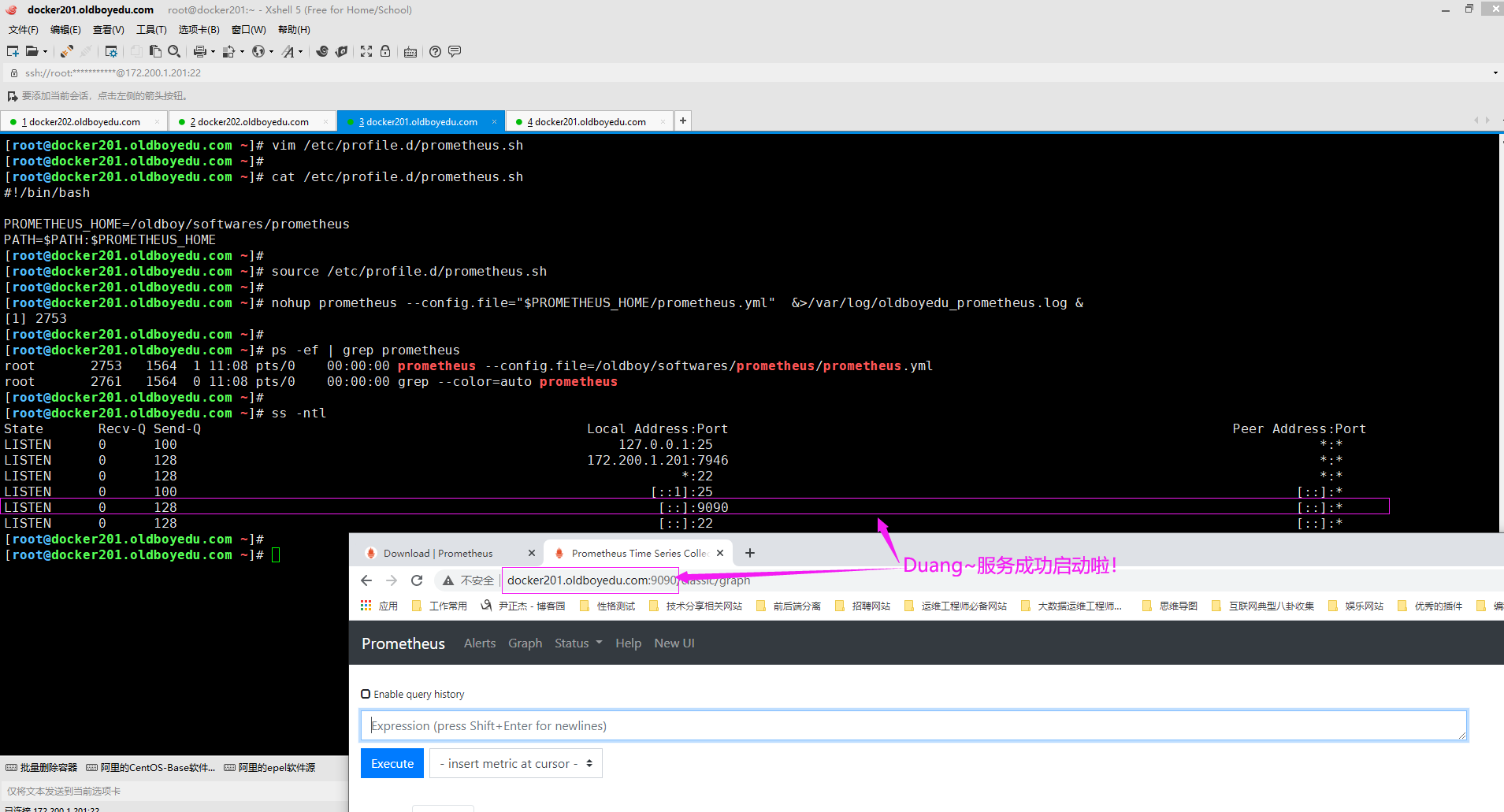
7.prometheus的配置文件说明
global:
scrape_interval:
设置prometheus采集数据的间隔时间,默认是1分钟。通常该值设置15秒就够用了。
学习环境中我们可以将其设置为5秒。
如果设置的间隔时间过短,比如设置为1秒,可能会造成更多的存储空间哟。
evaluation_interval:
监控数据规则的评估评论,默认值为每1分钟。通常该值设置每15秒评估一次规则就够用了。
举个例子: 假如我们定义的rule(规则)是当内存使用率大于70%就发出报警,那么prometheus会默认15秒来执行这个规则并检查内存的情况。
# Alertmanager configuration(先战略性忽略)
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 抓取数据的配置
scrape_configs:
job_name:
定义任务的名称。
static_configs:
定义静态的配置,比如使用targets指定要监控的对象。
file_sd_configs:
定义基于文件的动态配置,比如使用files指定文件路径,使用refresh_interval指定监控的间隔时间。
温馨提示:
(1)Alertmanager configuration是用来报警的,我们会有专门的章节来讲解它,此处先忽略;
(2)Alertmanager也可以被其它插件取代,比如基于grafana实现监控报警;8.课堂练习
默认情况下是无账号密码验证的,我们可以基于nginx实现反向代理,而后设置相应的账号密码。
该步骤过于简单,请同学们使用5分钟搞定,课件休息10分钟。四.部署node exporter监控软件
1.node exporter作用概述
大多数exporter下载之后,就提供了启动的命令,一般直接运行,带上一定的参数就可以了。
最常见的"node exporter"这个exporter非常强大,几乎可以把Linux系统中和系统自身相关的监控数据全抓出来了(很多参数,说真的,很可能咱们都没有听过,要比你想象的,学过的,多得多哟~)2.下载node exporter软件包
如下图所示,我们在下载软件之前,可以先选择prometheus将要安装的操作系统及其CPU架构.
推荐阅读:
https://prometheus.io/download/
3.解压软件包到指定路径
[root@docker202.yinzhengjie.com ~]# tar xf node_exporter-1.1.2.linux-amd64.tar.gz -C /oldboy/softwares/
[root@docker202.yinzhengjie.com ~]#
[root@docker202.yinzhengjie.com ~]# cd /oldboy/softwares/
[root@docker202.yinzhengjie.com /oldboy/softwares]#
[root@docker202.yinzhengjie.com /oldboy/softwares]# ln -sv node_exporter-1.1.2.linux-amd64 node_exporter
"node_exporter" -> "node_exporter-1.1.2.linux-amd64"
[root@docker202.yinzhengjie.com /oldboy/softwares]#
4.配置环境变量
[root@docker202.yinzhengjie.com ~]# vim /etc/profile.d/prometheus.sh
[root@docker202.yinzhengjie.com ~]#
[root@docker202.yinzhengjie.com ~]# cat /etc/profile.d/prometheus.sh
#!/bin/bash
EXPORTER_HOME=/oldboy/softwares/node_exporter
PATH=$PATH:$EXPORTER_HOME
[root@docker202.yinzhengjie.com ~]#
[root@docker202.yinzhengjie.com ~]#
[root@docker202.yinzhengjie.com ~]# source /etc/profile.d/prometheus.sh
[root@docker202.yinzhengjie.com ~]#
5.查看帮助信息
[root@docker202.yinzhengjie.com ~]# node_exporter --help
温馨提示:
如下图所示,我们可以查看"node_exporter"工具的帮助信息哟~
6.启动node exporter实例
[root@docker202.yinzhengjie.com ~]# nohup node_exporter &>/var/log/oldboyedu_node_exporter.log &
[1] 3423
[root@docker202.yinzhengjie.com ~]#
温馨提示:
直接执行node_exporter会阻塞当前终端,因此我们可以将其放在后台启动哟~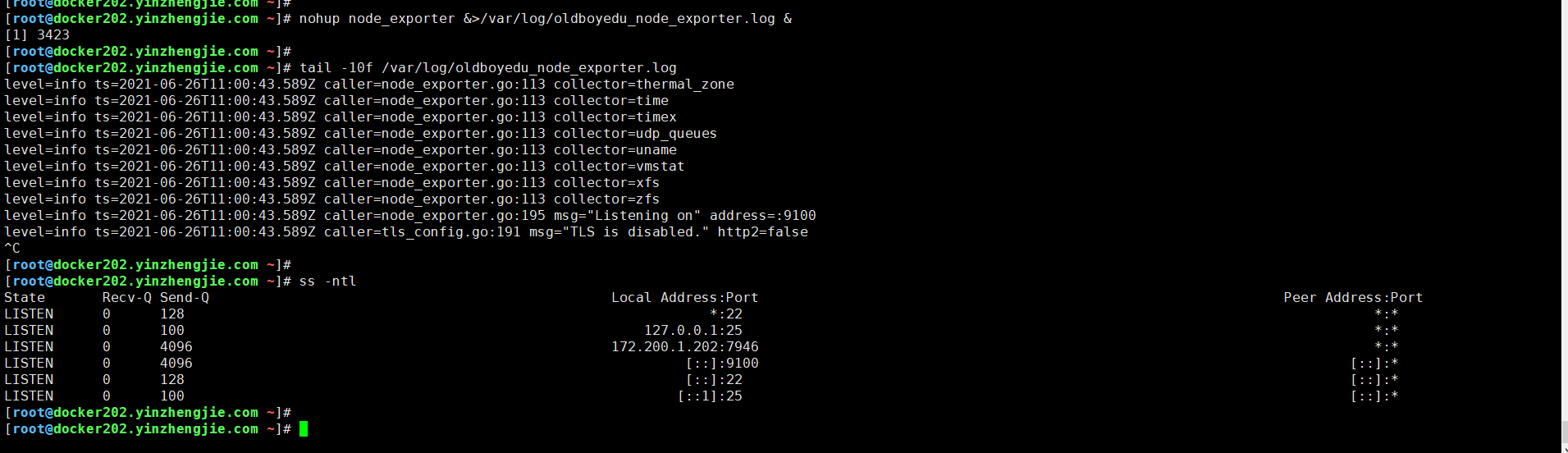
7.查看node exporter实例采集的metrics指标
如下图所示,我们可以访问"http://172.200.1.202:9100/metrics"这URL就能查看到当前node exporter实例访问的数据啦。
很明显,当我们运行程序成功后,就可以响应prometheus server发过来的HTTP GET请求啦。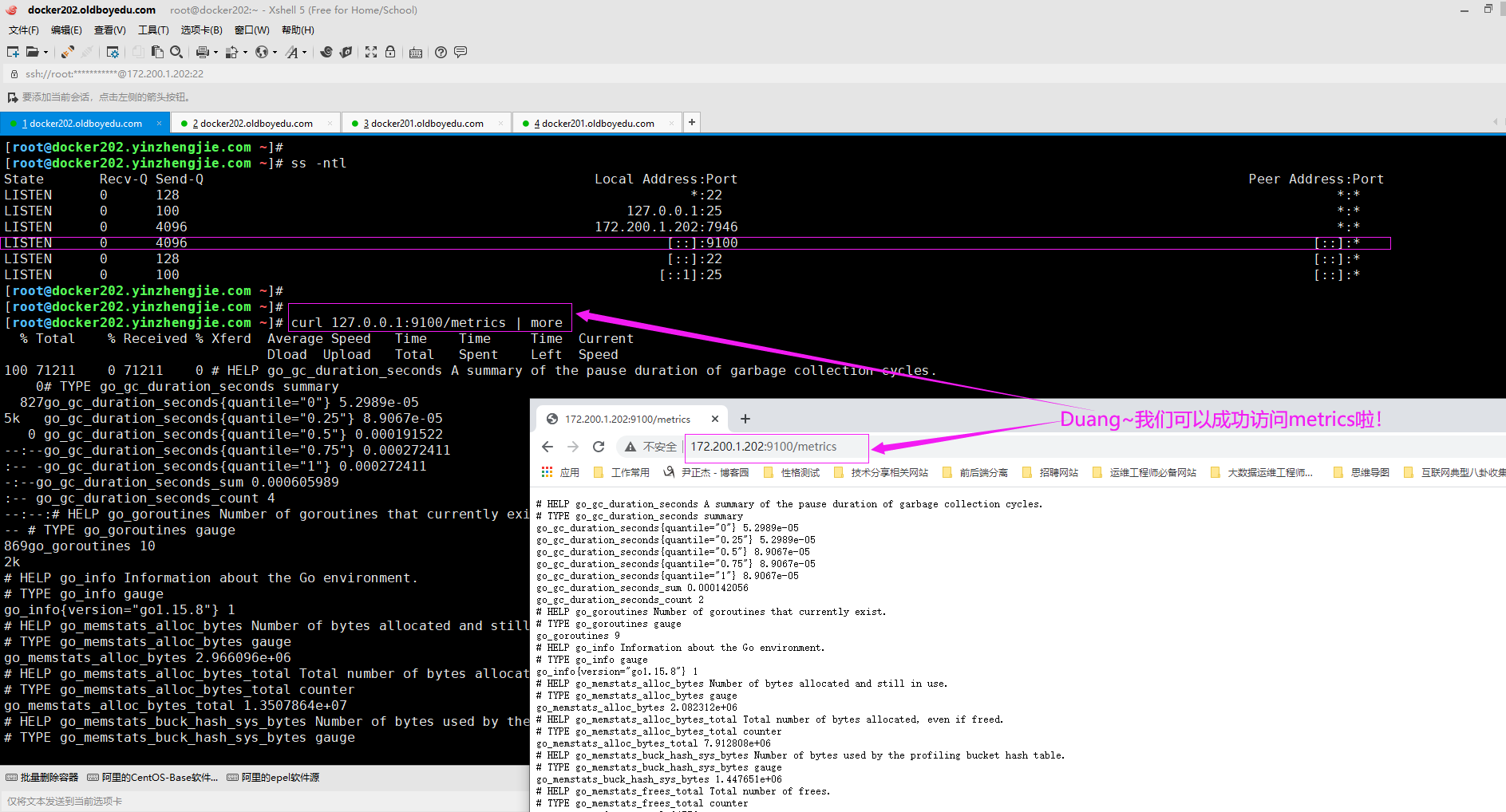
8.查看官方文档
默认启用的采集器:
https://github.com/prometheus/node_exporter#enabled-by-default
默认禁用的采集器:
https://github.com/prometheus/node_exporter#disabled-by-default
温馨提示:
对于中小型企业,推荐大家使用默认的采集器启用的采集器即可,基本上也够咱们使用了,除非你要开启监控一些特殊的数据,可以启用对应的采集器。
五.通过容器启动node_exporter和cadvisor
1.加载镜像
docker image load -i oldboyedu_docker_monitor_node.tar.gz
quay.io/prometheus/node-exporter:
node-exporter容器,用于监控Linux服务器的基本信息。
google/cadvisor:
由Google公司研发,监控容器。
温馨提示:
我们也是直接使用pull指令下载最新的镜像哟~但我仍然建议先跟我使用相同的镜像环境。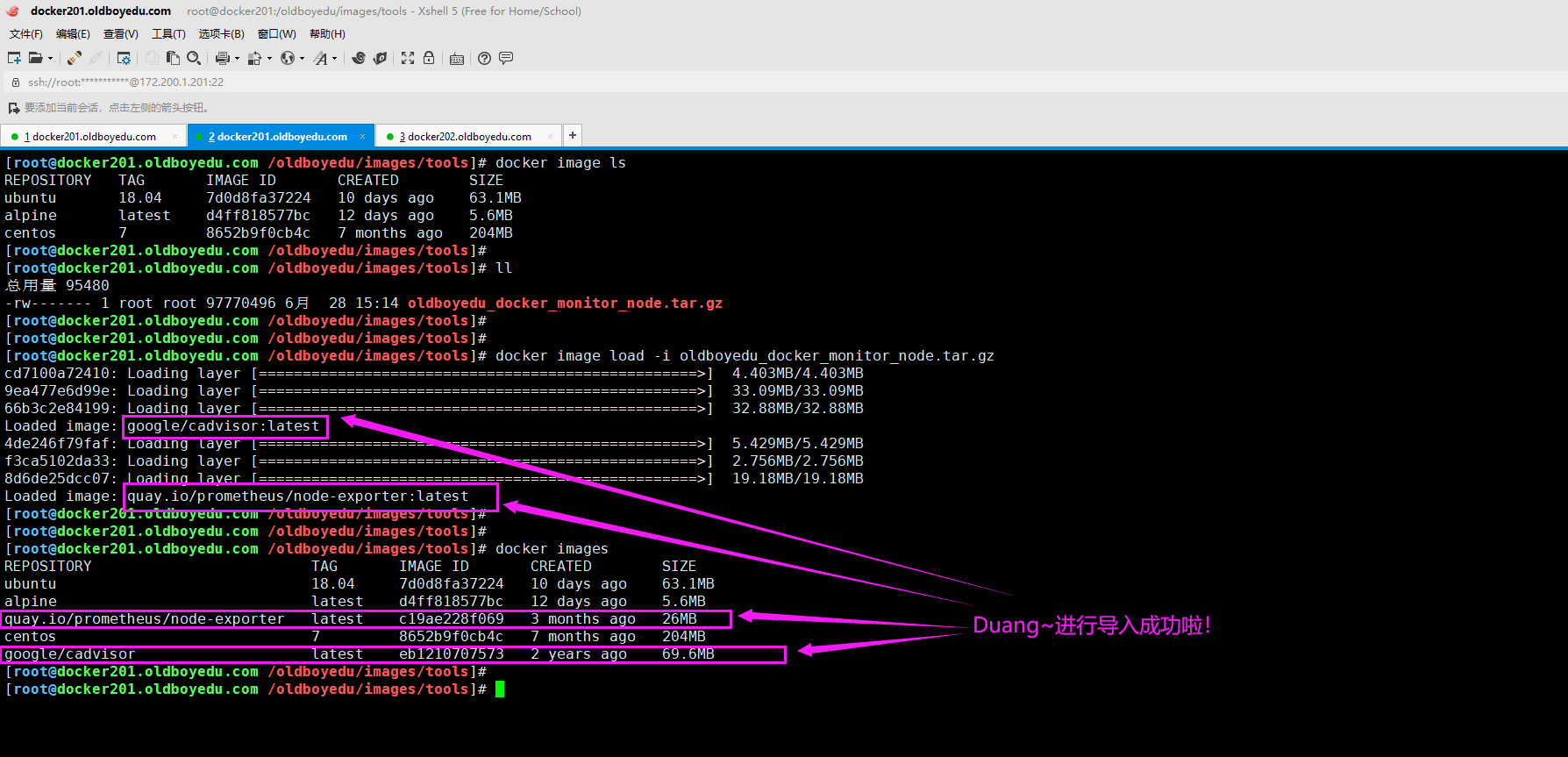
2.启动node-exporter容器
docker container run -dp 9100:9100 -v "/:/host:ro,rslave" --name=node_exporter quay.io/prometheus/node-exporter --path.rootfs /host
相关启动参数说明:
-v "/:/host:ro,rslave"
将宿主机的"/"目录挂载到容器的"/host"目录并设置相应的权限。
其中"ro"表示只读权限,"rslave"表示同步权限,即宿主机目录发生变化后会同步到容器。
--path.rootfs /host
这是启动参数,指定根目录在"/host"目录中。
温馨提示:
如下图所示,启动容器后,访问"http://docker201.oldboyedu.com:9100/metrics"进行测试即可。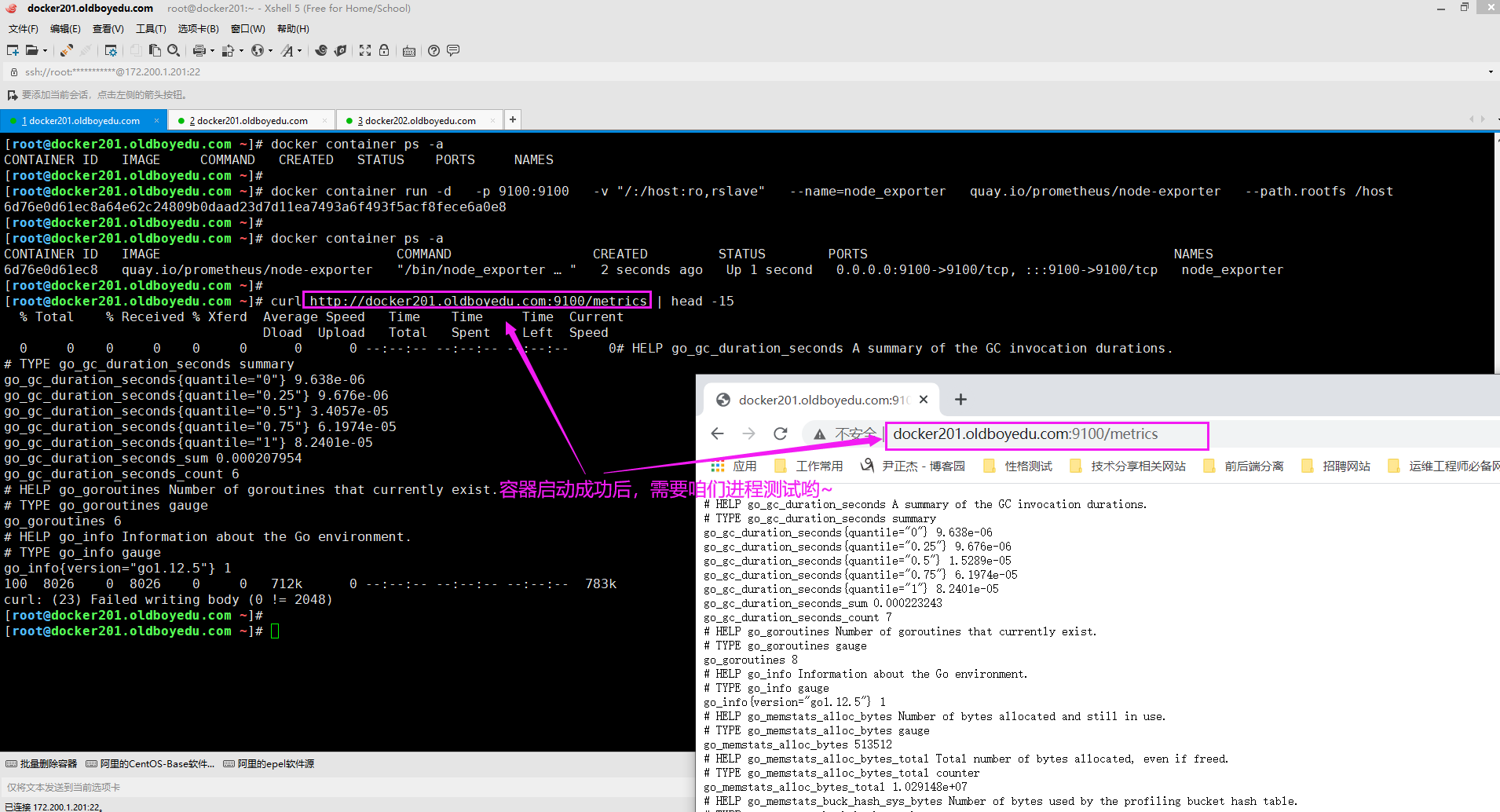
3.启动cadvisor容器
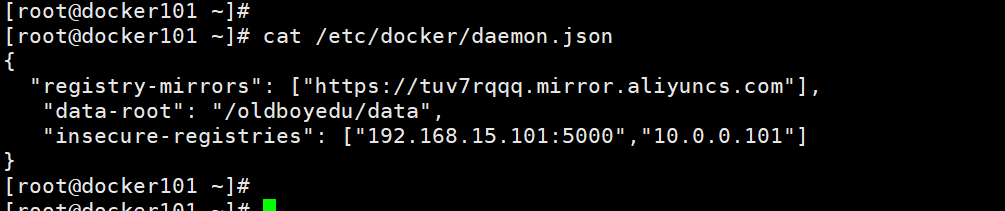
如上图所示,由于我修改了docker存储数据的目录("data-root"),因此我们也需要做相应的调整如下:
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/oldboyedu/data/:/var/lib/docker:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
如果你未修改docker的数据目录,直接使用如下配置即可:
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
相关启动参数说明:
--volume=/:/rootfs:ro
将宿主机的"/"目录挂载到容器的"/rootfs"目录并设置相ro的权限。
我们也可以将"--volume"简写为"-v"。
--publish=8080:8080
指定端口映射,将宿主机的8080端口映射到容器的8080端口。
我们也可以将"--publish"简写为"-p"。
--detach=true
表示在后端运行容器,我们可以简写为"-d"。
温馨提示:
如下图所示,启动容器后,访问"http://docker201.oldboyedu.com:8080/metrics"进行测试即可。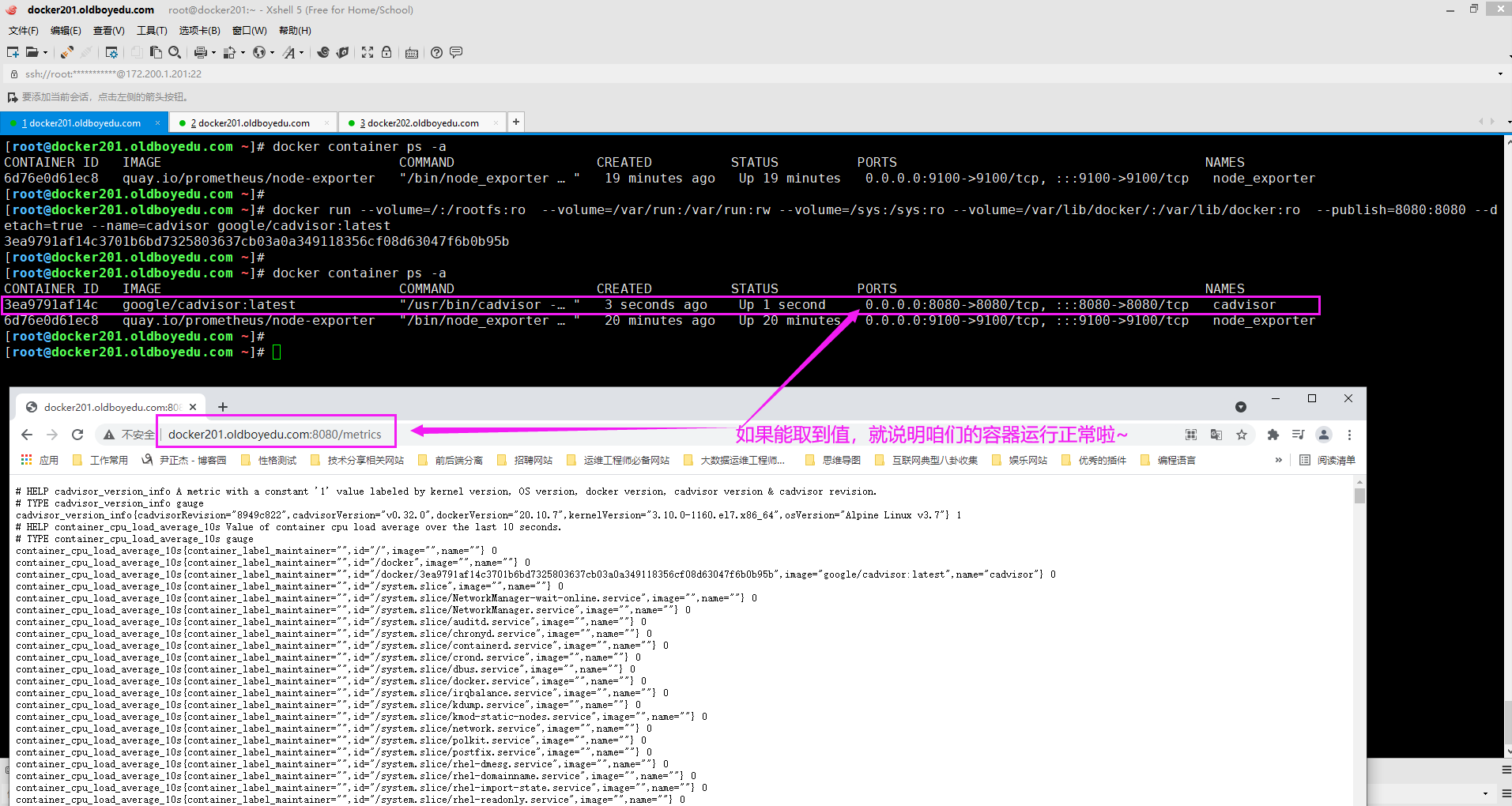
六.添加静态配置(static_configs)实战案例
1.修改prometheus的配置文件并重启服务
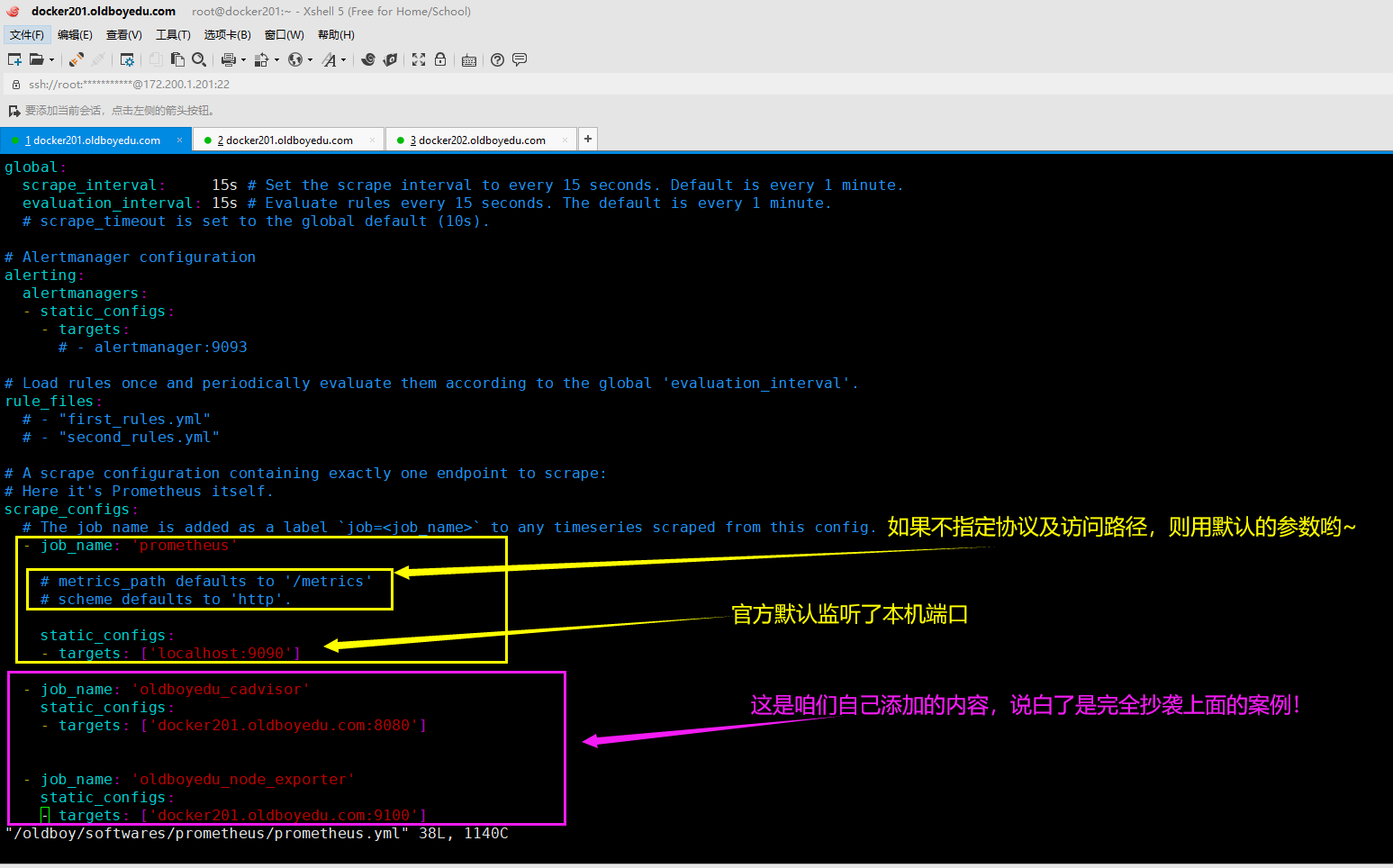
(1)修改配置文件(/oldboy/softwares/prometheus/prometheus.yml)
scrape_configs:
...
- job_name: 'oldboyedu_cadvisor'
static_configs:
- targets: ['docker201.oldboyedu.com:8080']
- job_name: 'oldboyedu_node_exporter'
static_configs:
- targets: ['docker201.oldboyedu.com:9100']
(2)重启prometheus服务(需要先手动kill掉进程,可以先使用netstat命令过滤)
nohup prometheus --config.file="$PROMETHEUS_HOME/prometheus.yml" &>>/var/log/oldboyedu_prometheus.log &
2.查看prometheus的WebUI界面
如下图所示,依次点击"Status" ---> "Targets" ---> "show more"。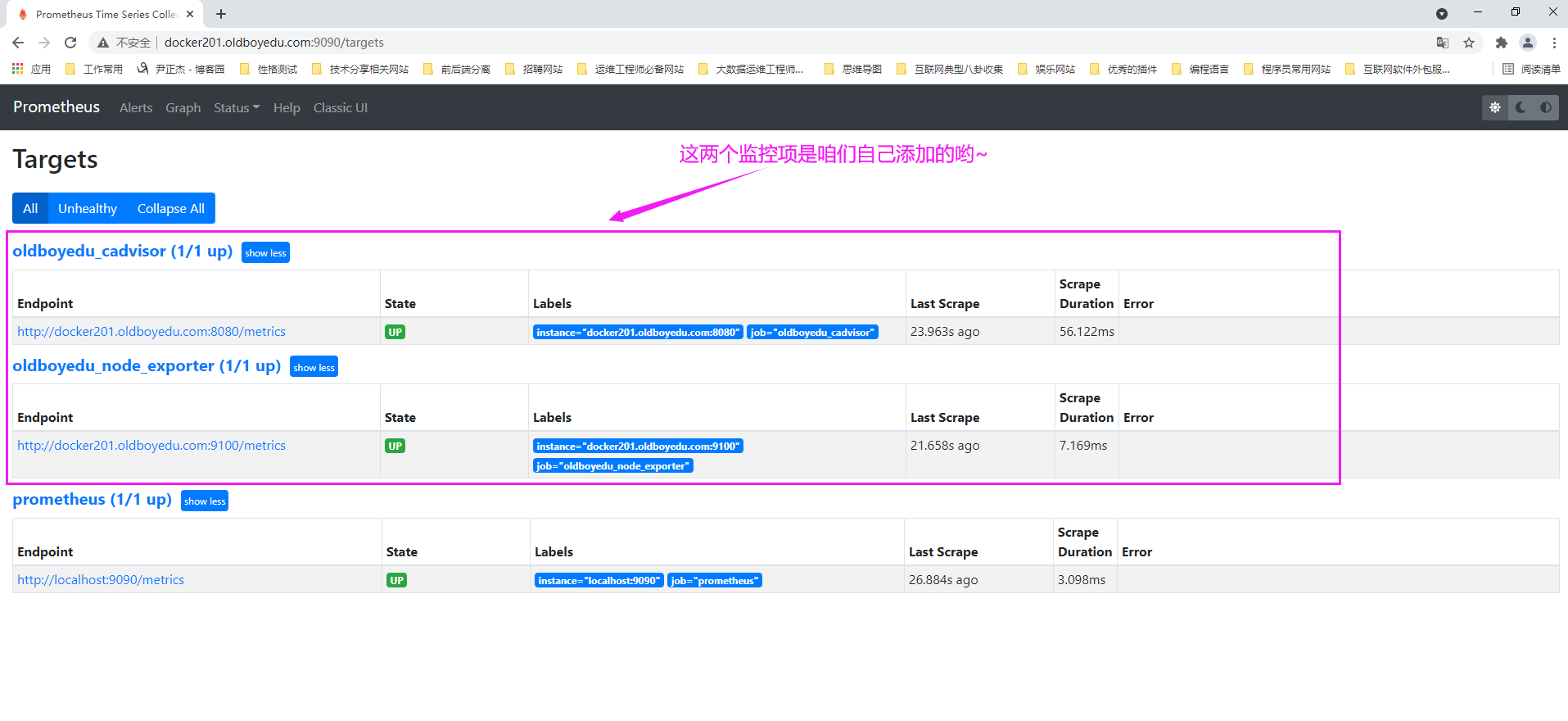
3.关于添加静态配置(static_configs)的吐槽
通过上面案例我们发现添加静态配置(static_configs)的确可以实现对node-exporter以及cadvisor实例的监控,但也存在缺陷。
一个致命的缺点就是每次添加一个监控项咱们都得去重启prometheus server,这一点实在忍不了,因为重启的时候会导致prometheus server在这段时间是不可用的。
如果重启后速度比较快也就罢了,如果配置文件写错导致服务长时间启动不了就得不偿失了。
综上所述,我们需要实现动态发现添加exporter哟~七.动态发现添加exporter实战案例
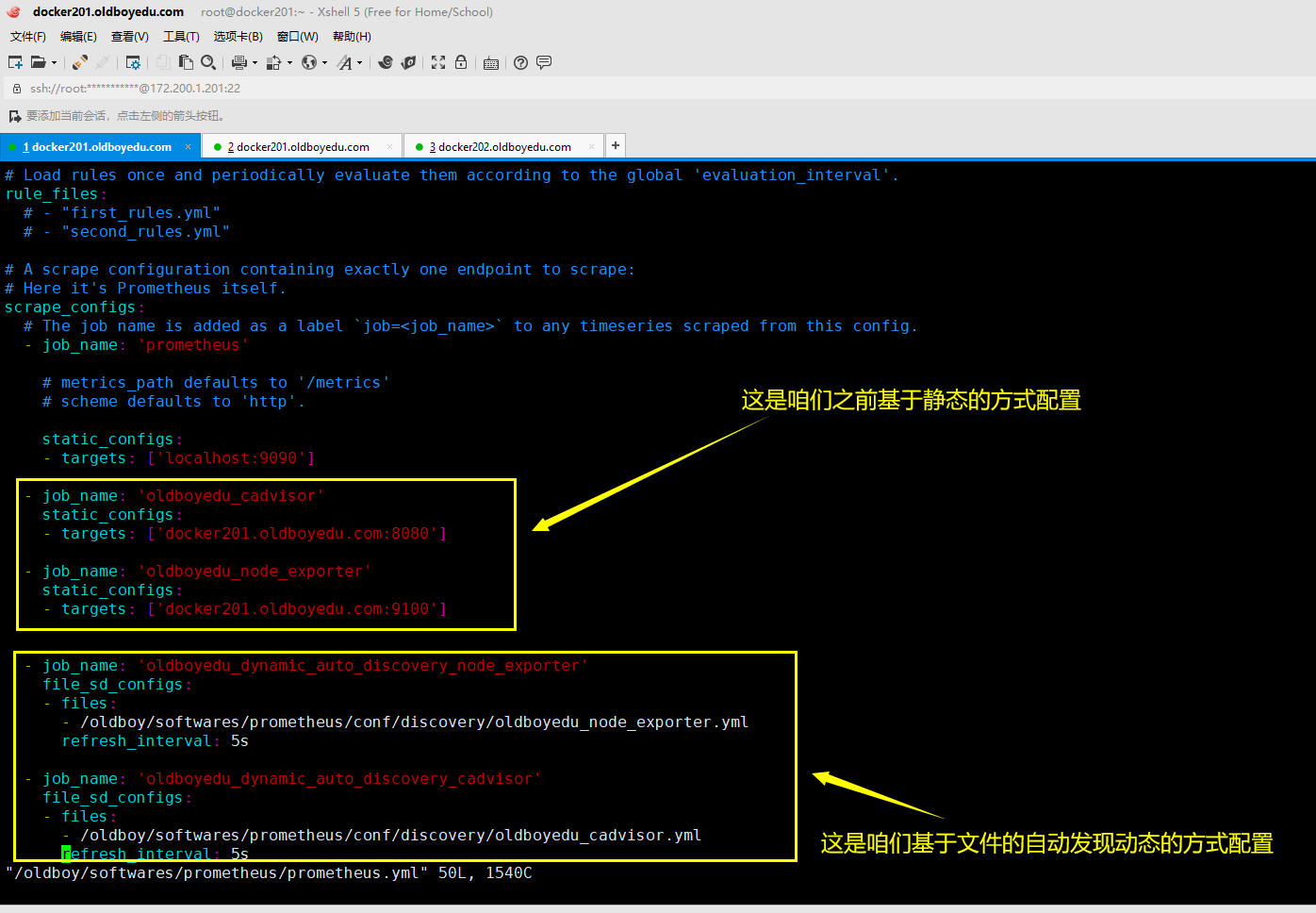
1.修改prometheus的配置文件
修改prometheus的配置文件
scrape_configs:
...
- job_name: 'oldboyedu_dynamic_auto_discovery_node_exporter'
file_sd_configs:
- files:
- /oldboy/softwares/prometheus/conf/discovery/oldboyedu_node_exporter.yml
refresh_interval: 5s
- job_name: 'oldboyedu_dynamic_auto_discovery_cadvisor'
file_sd_configs:
- files:
- /oldboy/softwares/prometheus/conf/discovery/oldboyedu_cadvisor.yml
refresh_interval: 5s
相关参数说明:
file_sd_configs:
指定基于文件的动态配置,这句话的含义是prometheus还可以基于其它的方式实现自动发现,比如基于consul类似的服务。
files:
指定文件的位置。
refresh_interval:
指定刷新配置的间隔时间,测试时可以适当调小,生产环境中为了减小压力可以稍微调大,比如跳到30秒。
2.创建自动发现相关的文件
(1)创建目录
mkdir -pv /oldboy/softwares/prometheus/conf/discovery
(2)创建oldboyedu_node_exporter.yml配置文件
[
{
"targets": ["docker201.oldboyedu.com:9100"]
}
]
(3)创建oldboyedu_cadvisor.yml配置文件
[
{
"targets": ["docker201.oldboyedu.com:8080"]
}
]
温馨提示:
如下图所示,配置文件需要遵循yaml的语法格式哟~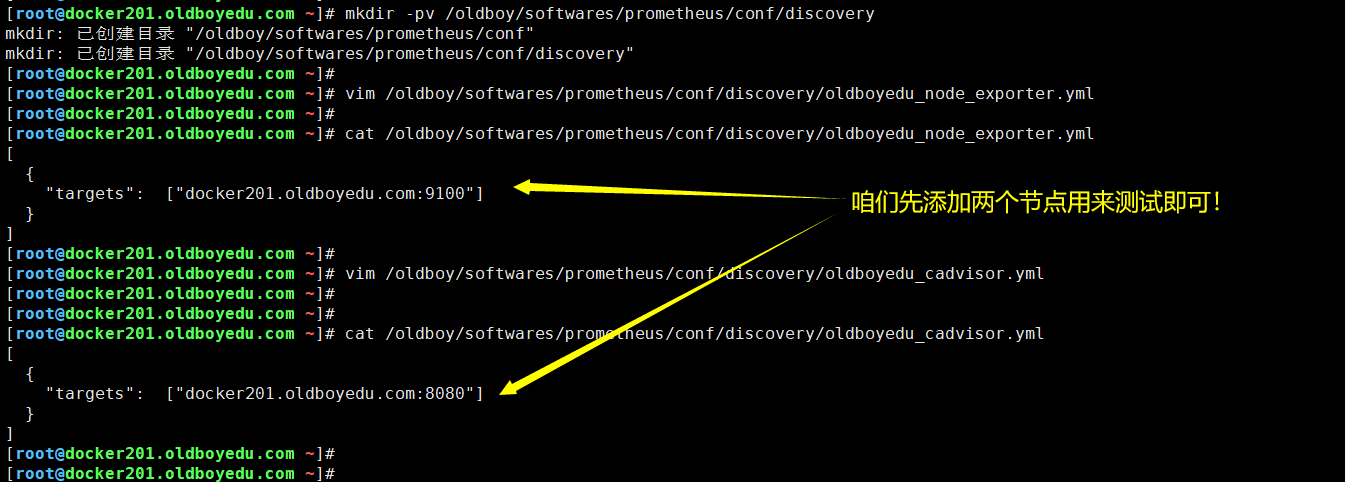
3.重启prometheus server端
nohup prometheus --config.file="$PROMETHEUS_HOME/prometheus.yml" &>>/var/log/oldboyedu_prometheus.log &
温馨提示:
如下图所示,启动时请先kill掉进程哟~否则启动会失败!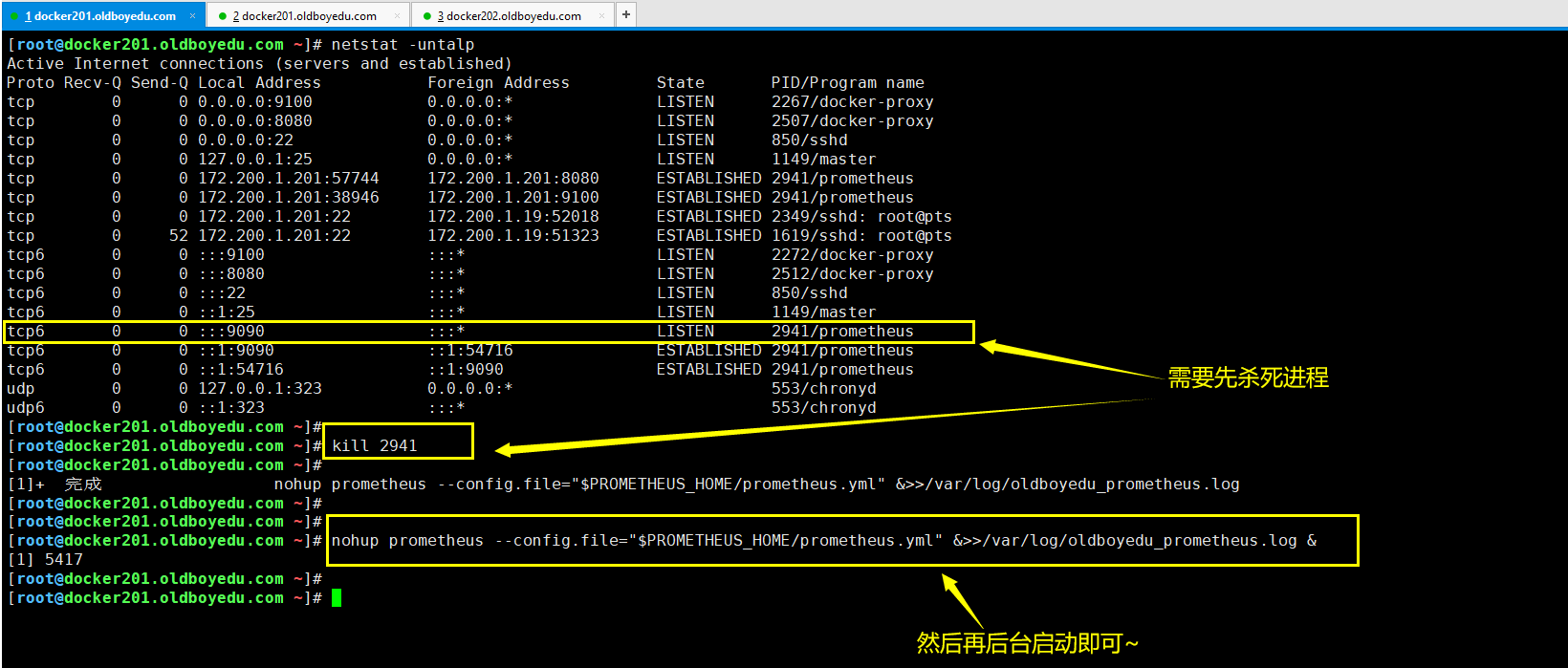
4.查看prometheus的WebUI
如下图所示,不难发现咱们的被监控实例被成功监控了。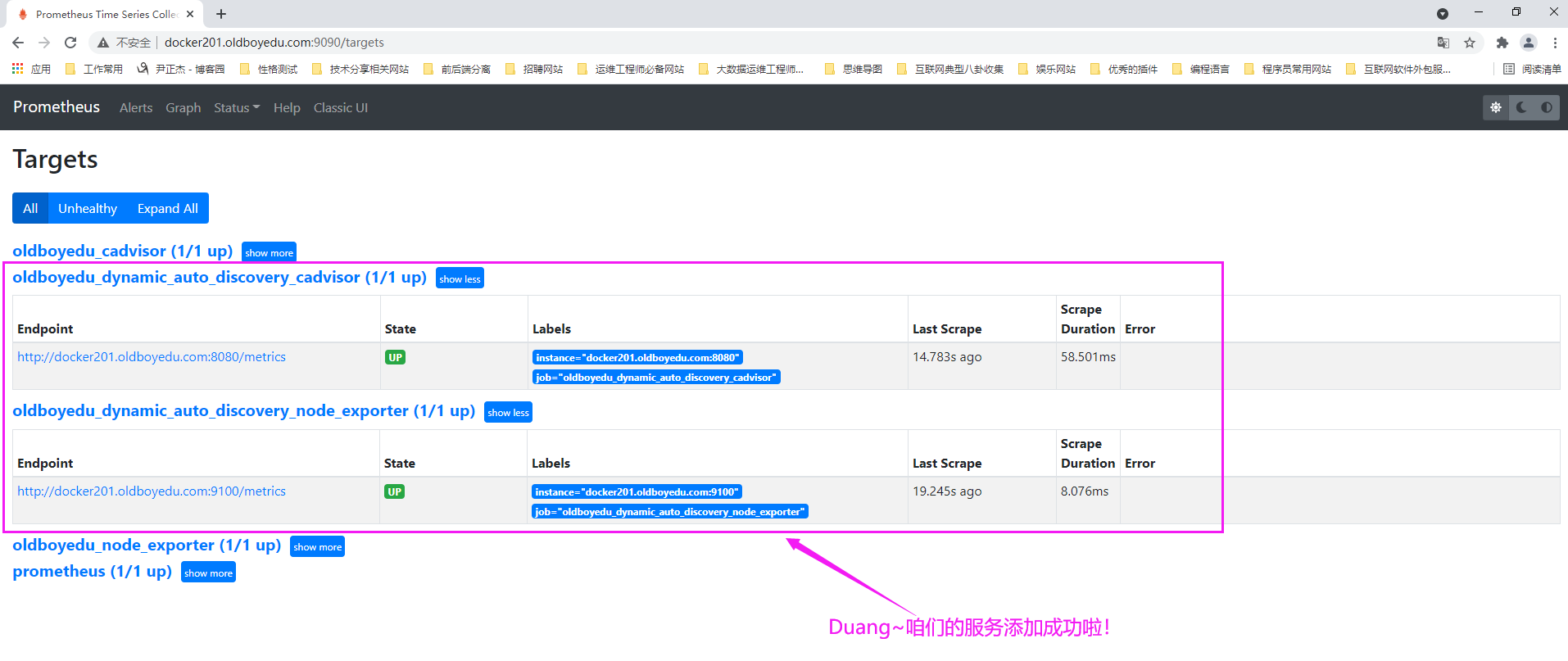
5.再次修改配置文件
如下图所示,我们再次添加其它节点,无需重启prometheus服务。
(1)修改oldboyedu_node_exporter.yml配置文件
[
{
"targets": ["docker201.oldboyedu.com:9100","172.200.1.202:9100"]
}
]
(2)修改oldboyedu_cadvisor.yml配置文件
[
{
"targets": ["docker201.oldboyedu.com:8080","172.200.1.202:8080"]
}
]
温馨提示:
请确保咱们要添加的实例已成功运行相应的node_exporter和cadvisor实例哟。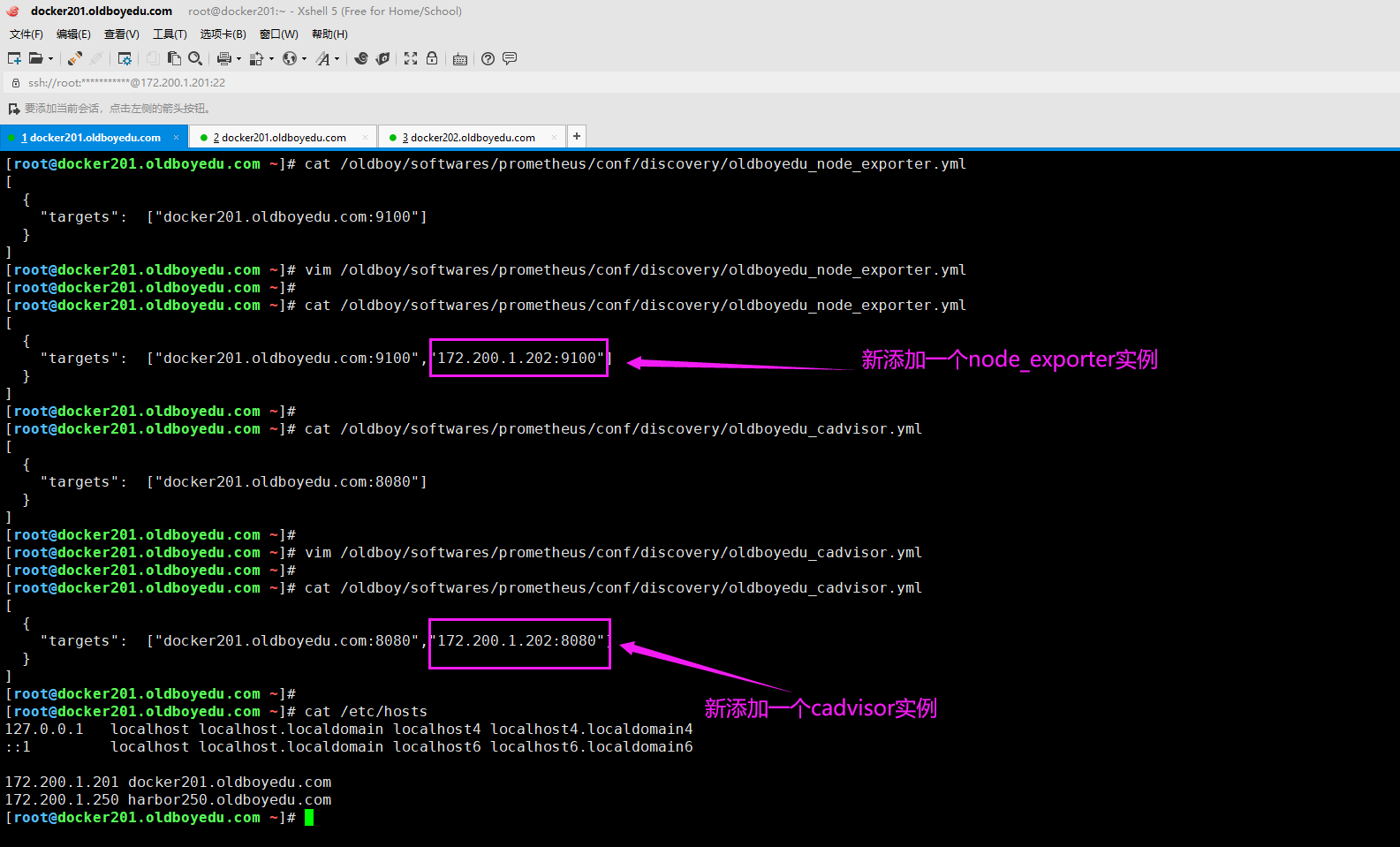
6.再次查看prometheus的WebUI
如下图所示,我们成功的添加了新的节点哟~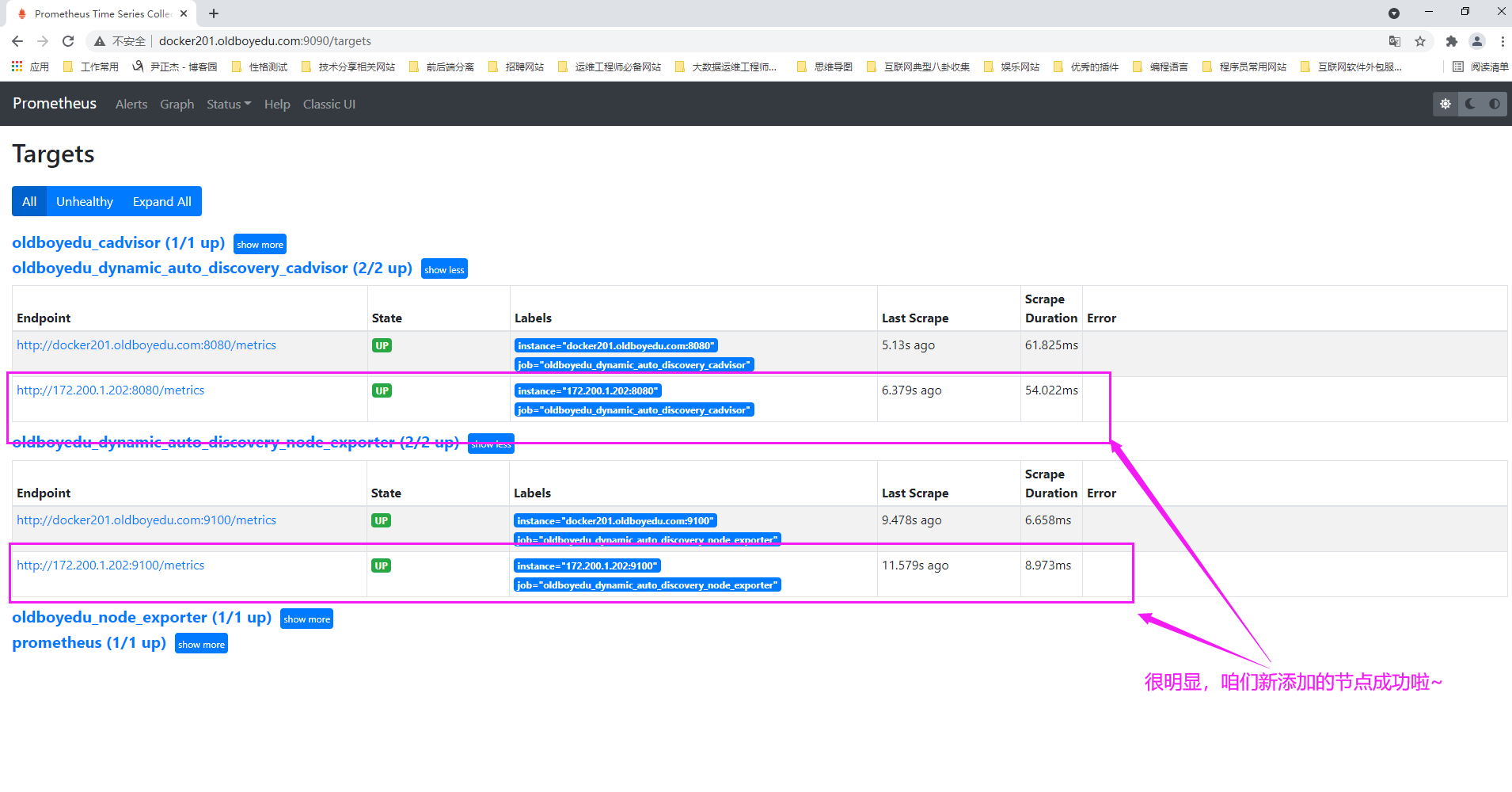
八.prometheus监控数据格式概述
1.prometheus metrics的指标类型(Metric Types)
prometheus监控中对于采集过来的数据统一称为metrics数据。
metrics是一种对采样数据的总称,其并不代表一种具体的数据格式,而是一种对于度量计算单位的抽象。
当我们需要为某个系统或者某个服务做监控,统计时,就需要用到metrics。
prometheus支持的metrics包括但不限于以下几种常见的类型:
gauge:
Gauges是最简单的度量指标,只有一个简单的返回值,或者叫瞬时状态。例如,我们想衡量一个待处理队列中任务的个数,这个个数是会变化的。
当我们要监控硬盘容量或者内存的使用量,那么就应该使用Gauges的metrics格式来衡量,因为硬盘的容量或者内存的使用量是随时间的推移,不断瞬时且无规则变化的。
这种变化没有规律,当前是多少,采集回来的就是多少。
counter:
Counters就是计数器,从数据量0开始积累计算,在理想情况下,只能是永远的增长,不会降低(一些特殊情况另说,比如说粉丝数,未必就是只增不减.)。
比如统计一小时,一天,一周,一个月的用户的访问量,这就是一个累加的操作。
histograms:
histograms是统计数据的分布情况。比如最小值,最大值,中间值,还有中位数,75百分位,90百分位,95百分位,98百分位,99百分位和99.9百分位的值(percentiles)。
很显然,这是一种特殊的metrics数据类型,代表的是一种近似百分比估算数值。
举个例子:
如果我们想通过监控的方式抓取当天nginx的access.log,并且想监控用户的访问服务出现的故障时间,我们应该怎么做呢?
错误解决方案:
把日志每行的"http_response_time"数值统统采集下来,然后计算一下总的平均值。这是毫无意义的,因为故障发生时间可能只有一小段时间,比如网络延迟放生在12:30-12:40之间,其它时间都是正常的,如果计算总的平均值,则结果看起来会很正常,无法触发报警功能,运维人员可能也不知道这件事情发生了。
正确解决方案:
通过Histograms函数,可以分别统计出全部用户的响应时间在0.05秒,1秒,2秒,5秒,10秒的量。这样运维人员就能根据这个值进行报警,分析这些时间的产生原因,从而避免以后类似的问题发生。
summary:
因为histogram在客户端就是简单的分桶计数,在prometheus服务端基于这么有限的数据做百分位估算,所以的确不是很准确,summary就是解决百分位准确的问题而来的。
我们可以简单理解summary是Histogram的扩展类型,如果想要清除的了解histograms和summary的更多细节,可自行查阅相关的文档。2.K/V的数据形式
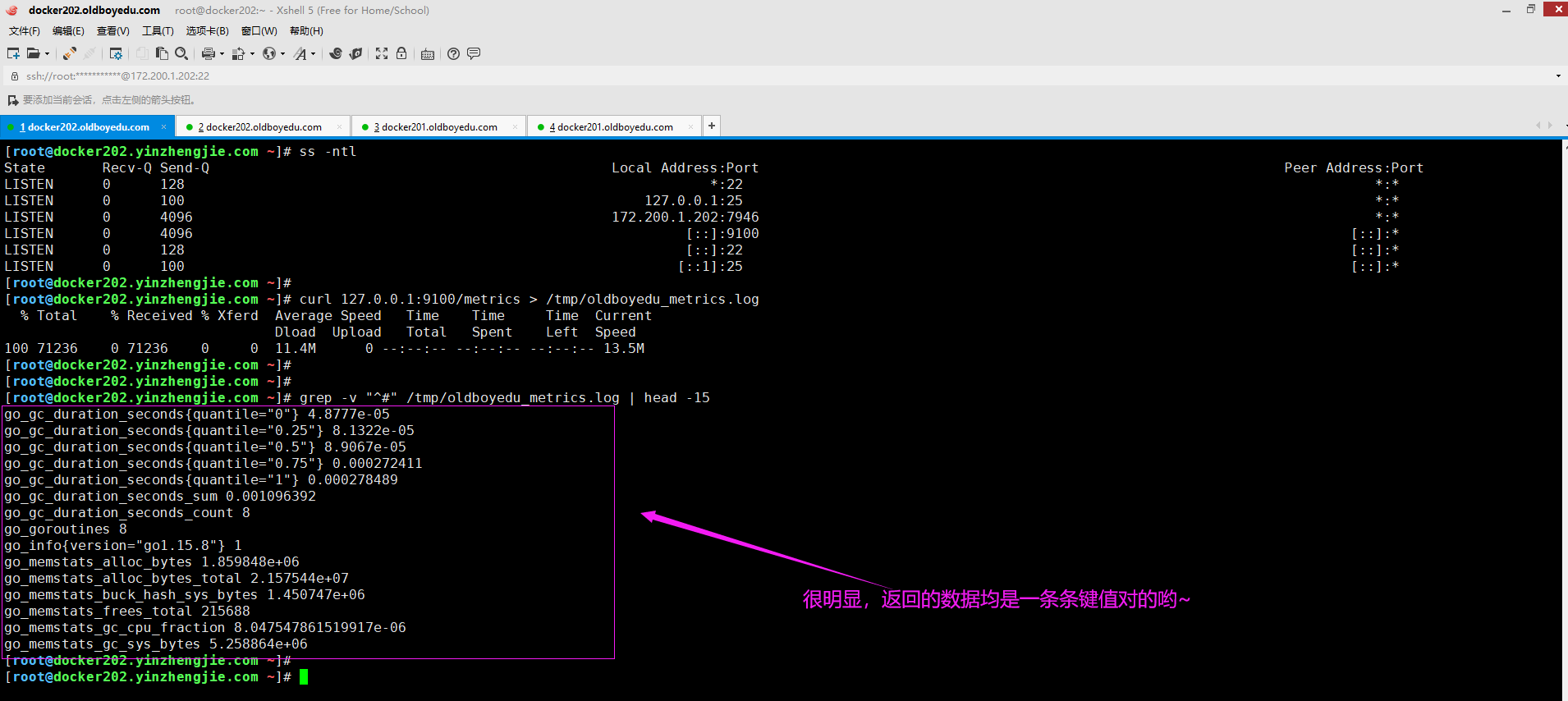
prometheus的数据类型就是依赖于上面提到的metris的类型来计算的。而对于采集回来的数据类型,必须要以一种具体的数据格式供我们查看和使用。
如上图所示,是一个node_exporter被安装和运行在被监控的服务器上后,使用简单的curl命令就可以看到exporter帮我们采集到metrics数据的样子,均是以空格分割的K/V的形式展现和保存的。
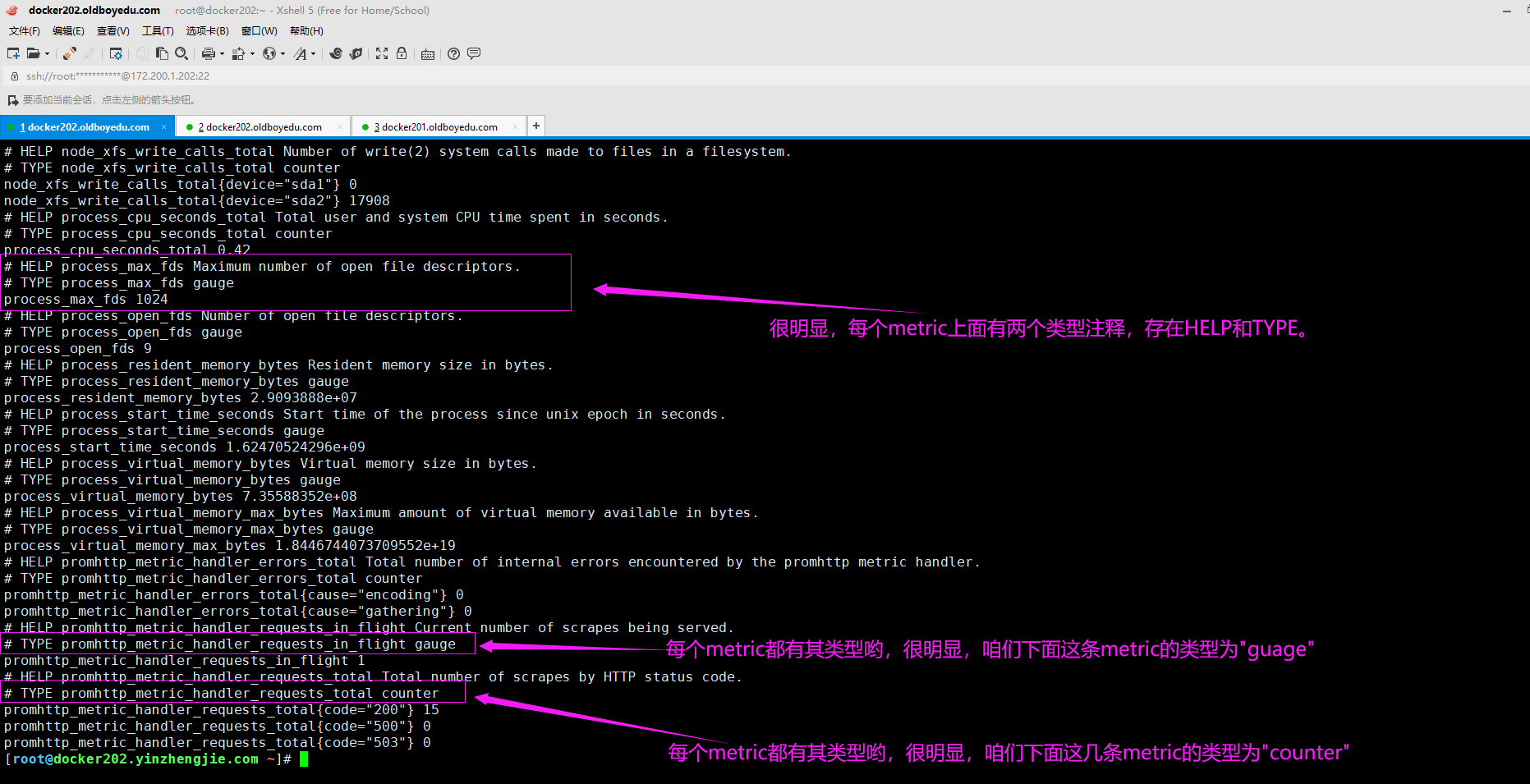
如下图所示,请不要忽略以"#"开头的行,每个metric都除了以空格分割的K/V数据外,其上面会最少存在两行注释信息,分别为HELP和TYPE,其中HELP是对该条metric作用的简单描述,而TYPE表示该metric的类型。
3.PromQL的数据类型
Prometheus基于指标名称(metrics name)以及附属的标签集(labelset)唯一定义一条时间序列。
(1)指标名称代表着监控目标上某类可测量数量的基本特征标识;
(2)标签则是这个基本特征上再次细分的多个可测量维度;
PromQL(Prometheus Query Language)是Prometheus Server内置数据查询语言:
(1)PromQL使用表达式(expression)来表述查询需求;
(2)根据其使用的指标和标签,以及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上,甚至是只包含单个时间序列的单个样本;
基于PromQL表达式,用户可以针对指定的特征及其细分的维度进行过滤,聚合,统计等运算而产生期望的计算结果。
PromQL的表达式中支持以下四种数据类型:
即时向量(Instant Vector):
特定或全部的时间序列集合上,具有相同时间戳的一组样本称为即时向量。
范围向量(Range Vector):
特定或全部的时间序列集合上,在指定的同一范围内的所有样本值。
标量(Scalar):
一个浮点型的数据值。
字符串(String):
支持使用单引号,双引号或反引号进行引用,但反引号中不会转移字符进行转义。九.查看Linux相关的key
1.查看内存信息
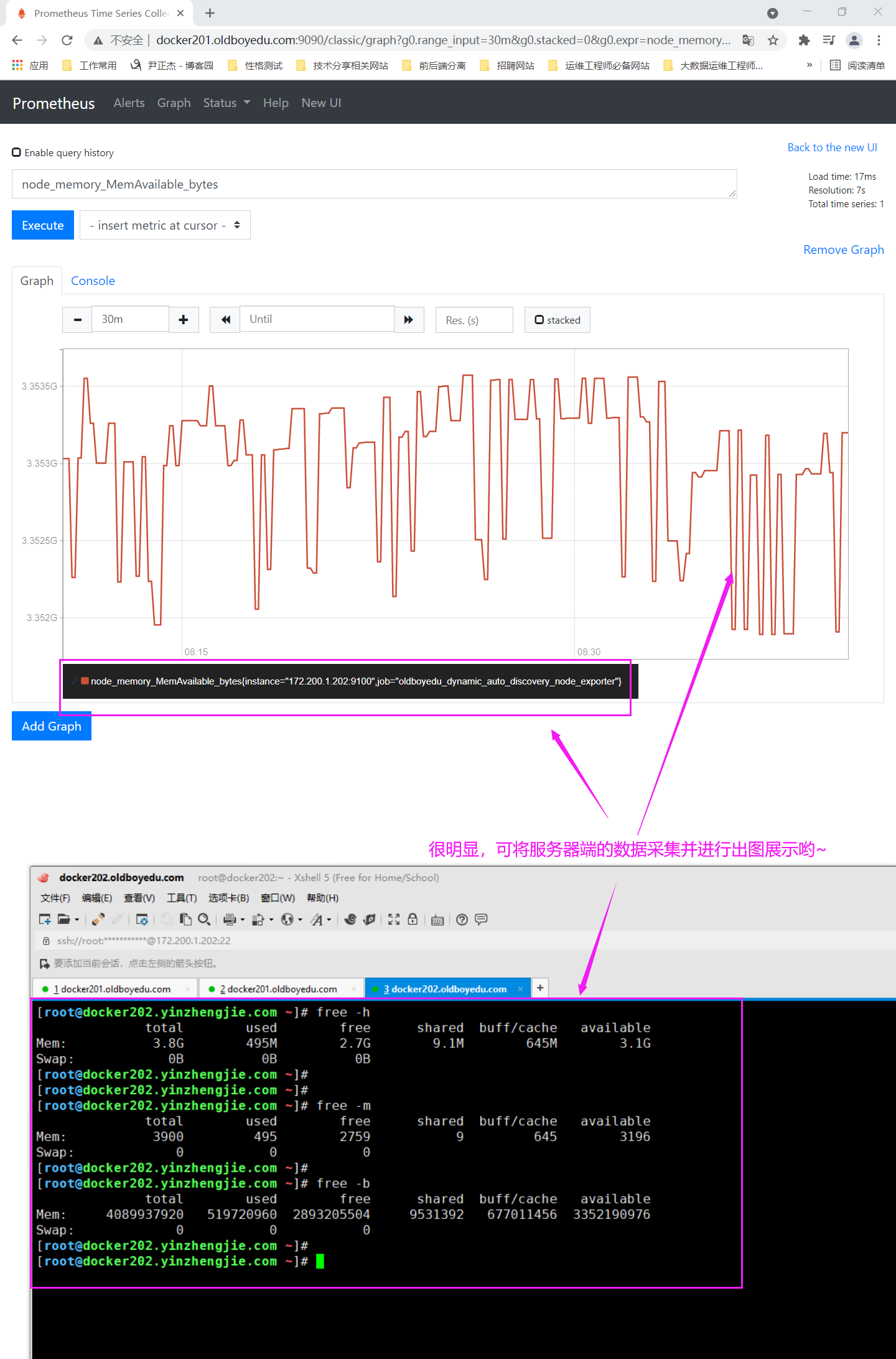
node_memory_MemFree_bytes:
查看CPU的空闲内存。
node_memory_MemTotal_bytes:
查看CPU的总内存。
node_memory_MemAvailable_bytes:
查看CPU的可用内存。
2.查看CPU信息
node_cpu_seconds_total{mode="idle"}:
使用标签过滤器查看所有CPU核心的空闲状态的总时间。
node_cpu_seconds_total{mode!="idle"}:
使用标签过滤器查看所有CPU核心的非空闲状态的总时间。
node_cpu_seconds_total{mode=~"i.*"}:
使用标签过滤器查看mode名称以"i"开头的所有CPU核心。
node_cpu_seconds_total{mode!~"i.*"}:
使用标签过滤器查看除了mode名称以"i"开头的所有CPU核心。
node_cpu_seconds_total:
表示查看所有CPU核心的所有状态的耗费时间。
jiffies是内核中的一个全局变量,用来记录自系统启动以来产生的节拍数,在Linux中,一个节拍大致可以理解为操作系统进程调度的最小时间片,不同的Linux内核可能值有所不同,通常在1ms-10ms之间。
CPU使用率 = CPU各种状态除了idle(空闲)这个状态外,其它所有的CPU状态的累加和 / 总的CPU使用时间
Linux的CPU时间实际是指从操作系统启动开始算起(CPU就开始工作了),记录自己在工作中总共使用"时间"的积累量把它保存在系统中,而积累的CPU使用时间还会分成几个重要的状态类型:
user:
从系统启动开始累计到当前时刻,处于用户态的运行时间,不包含nice值为负进程。
nice:
从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间。
system:
从系统启动开始累计到当前时刻,处于核心态的运行时间。
idle:
从系统启动开始累计到当前时刻,除IO等待时间意外的其它等待时间。
iowait:
从系统启动开始累计到当前时刻,IO等待时间。
irq:
从系统启动开始累计到当前时刻,硬中断时间。
softirq:
从系统启动开始累计到当前时刻,软中断时间。
...
推荐阅读:
http://c.biancheng.net/view/6242.html
温馨提示:
如下图所示,Prometheus对LinuxCPU的采集并不是直接给我们返回一个现成的CPU百分比,而是返回Linux中很底层的CPU时间片累计数值的这样一个数据,因此图形看起来是逐渐递增的。
我们平时习惯了top,uptime,sar,vmstat,iostat这些简便的方式查看CPU使用率,往往浅尝辄止根本没有好好深入理解所谓的CPU使用率在Linux中到底是怎么回事。
当懒人当的时间长了,请扪心自问一下对计算机底层原理的知识到底又了解多少呢?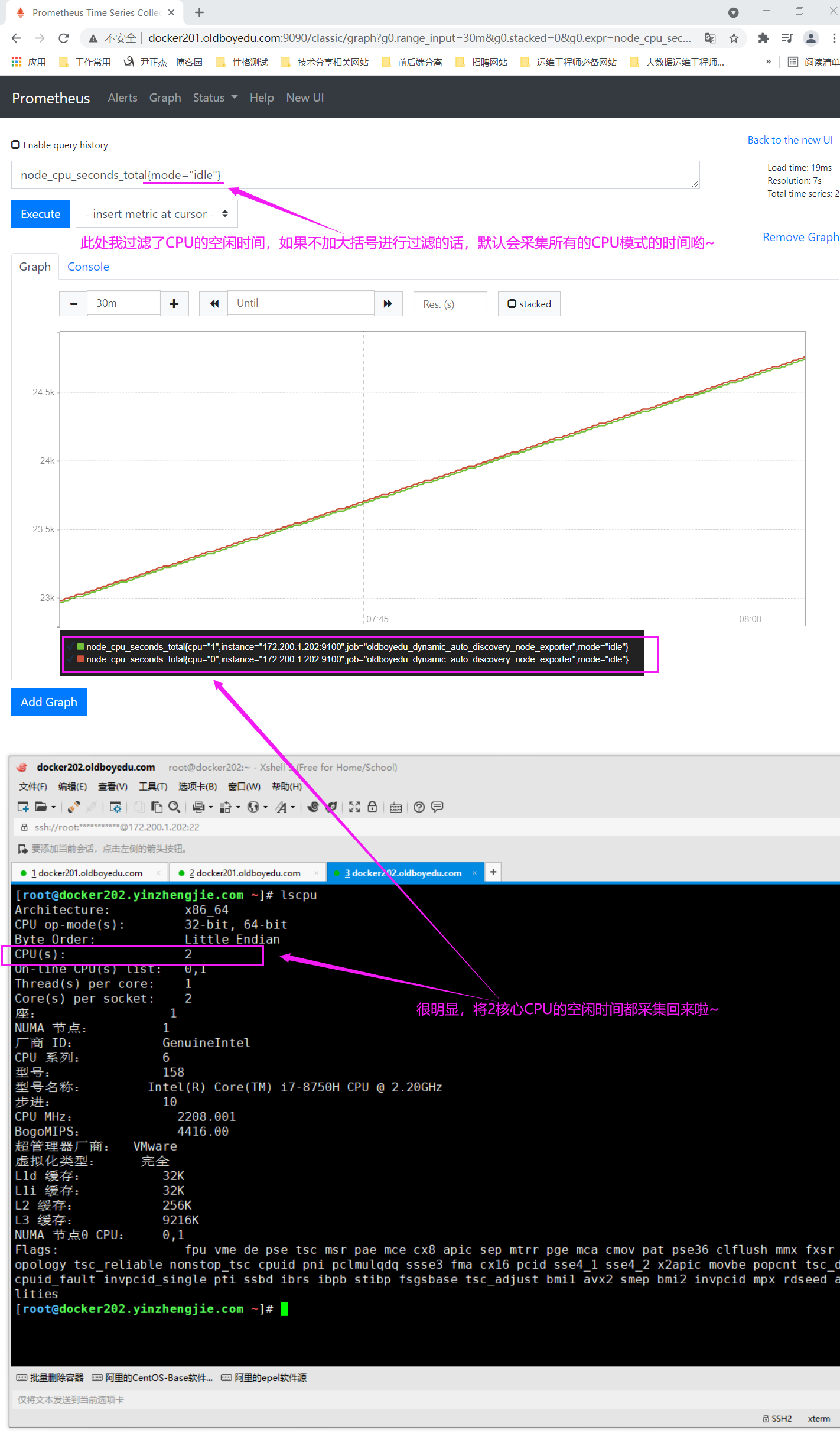
3.查看磁盘
rate(node_disk_write_time_seconds_total[10m]):
查看磁盘最近10分钟总的增长量并以每秒的形式出图显式。
温馨提示:
我们看到的图都是临时的,当关闭浏览器就不存在了,如果想要其永久存在,则可以借助grafana实现永久的图形的存储哟。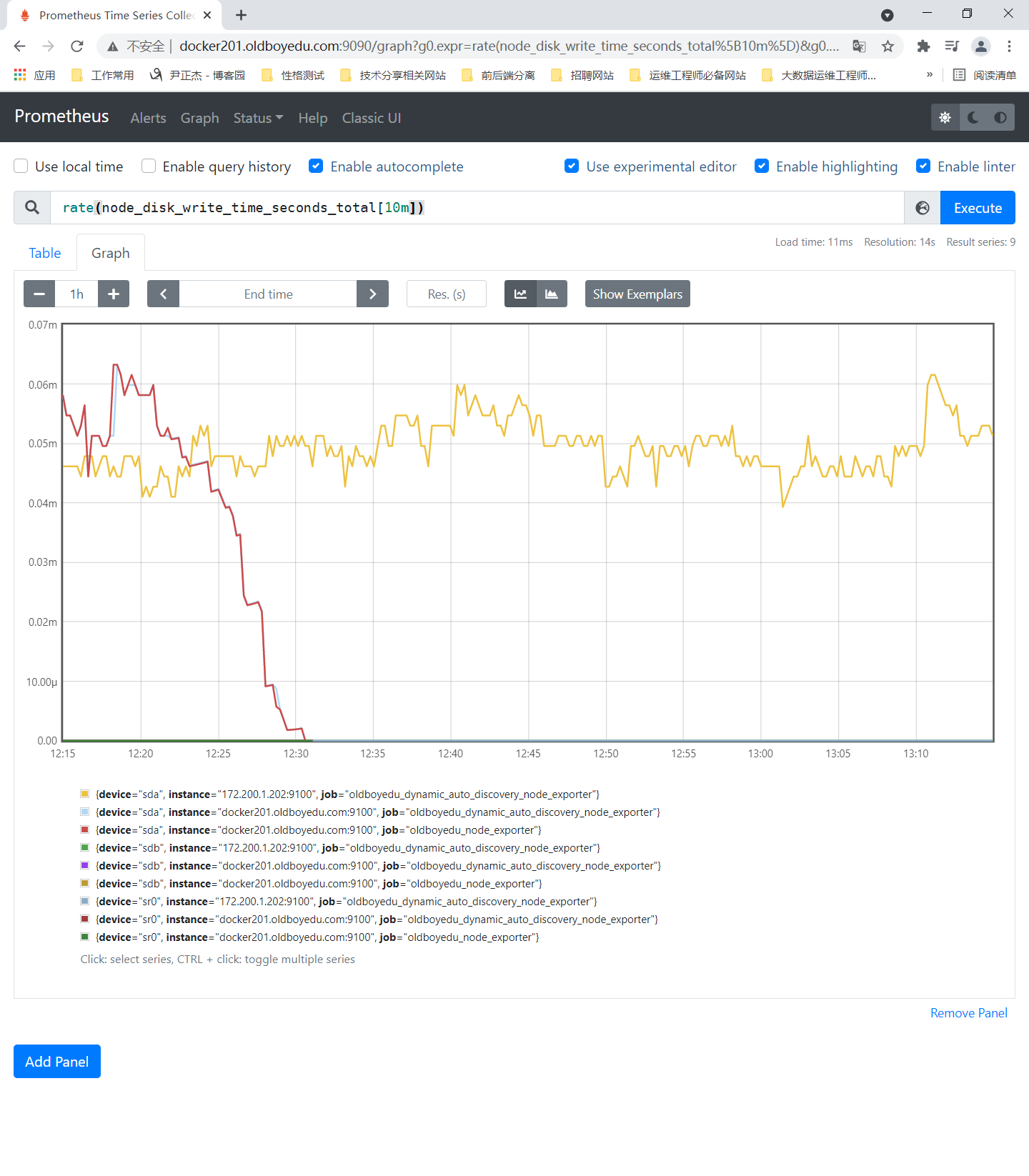
十.prometheus中常用的函数
1.increase函数
increase函数:
在prometheus中是用来针对Counter这种持续增长的数值,截取其中的一段时间的增量。
举个例子:
increase(node_cpu_seconds_total[1m]):
获取CPU总使用时间在1分钟内的增量,计算的是1分钟内增加的总量。
在实际工作中,我们的服务器通常是多核的,因此这个采集的是所有核心的值哟。
increase(node_cpu_seconds_total{instance="10.0.0.101:9100"}[100m]):
我们也可以借助标签选择器过滤查看某个服务器实例的配置.2.sum函数
sum函数:
顾名思义,主要是起到加和的作用。
举个例子:
sum(increase(node_cpu_seconds_total[1m])):
在"increase(node_cpu[1m])"外面套用一个sum函数就可以把所有CPU核心数在1分钟内的增量做一个累加。3.by函数
by函数:
将数据进行分组,类似于MySQL的"group by"。
举个例子:
by (instance):
这里的"instance"代表的是机器名称,意思是将数据按照instance标签进行强行拆分。
该函数通常会和sum函数搭配使用,比如"(sum(increase(node_cpu_seconds_total[1m])) by (instance))",表示把sum函数中累加和按照"instance"(机器名称)强行拆分成多组数据。当然,如果只有一个机器名称的话,你会发现只有一组数据,因此从结果上可能看不到明显的变化哟。
温馨提示:
instance是node_exporter内置的标签,当然,我们也可以自定义标签,比如根据生产环境中不同的集群添加相应的标签。比如基于自定义的"cluster_name"标签进行分组等。
4.rate函数
rate函数:
它的功能是按照设置的一个时间段,取counter在这个时间段中的平均每秒的增量。因此是专门搭配counter类型数据使用的函数。
举个例子:
rate(node_cpu_seconds_total[1m]):
获取CPU总使用时间在1分钟内的增加的总量并除以60秒,计算的是每秒的增量。
rate(node_network_receive_bytes_total[1m]):
获取一分钟内网络接收的总量。
查看的时间越短,某一瞬间的突起或降低在成图的时候会体现的更细致,更铭感。
rate(node_network_receive_bytes_total[20m])
获取二十分钟内网络接收的总量。
查看的时间越长,那么当发生瞬间的突起或降低时候,会显得平缓一些,因为取得时间段越长会把波峰波谷都给平均消下去了。
increase函数和rate函数如此相似如何选择?
(1)对于采集频率较低的数据采用建议使用increase函数,因为使用rate函数可能会出现断点(比如按照5分钟采样数据量较小的场景,以采集硬盘可用容量为例,可能会出现某次采集数据未采集到的情况,因为会按照平均每秒来计算最终的增量)的情况;
(2)对于采集频率较高的数据采用建议使用rate函数,比如对CPU,内存,网络流量等都可以基于rate函数来采样,当然,硬盘也是可以用rate函数来采样的哟;
温馨提示:
在实际工作中,我们取监控频率为1分钟还是5分钟这取决与我们对于监控数据的敏感程度来挑选。5.topk函数
topk函数:
取前几位的最高值。实际使用的时候一般会用该函数进行瞬时报警,而不是为了观察曲线图。
举个例子:
topk(3,rate(node_cpu_seconds_total[1m])):
获取CPU总使用时间在1分钟内的增加的总量并除以60秒,计算的是每秒的数量。并只查看top3。
温馨提示:
如下图所示,我们通常使用topk只会关注"Console"中的瞬时结果,不太会关心Graph的出图效果,因为关注他并没有太大意义,存在太多的断点啦!
下图之所以会出现中断的情况,是因为在20分钟内这一刻的数据其并没有排进top3,自然就会出现断点的状况。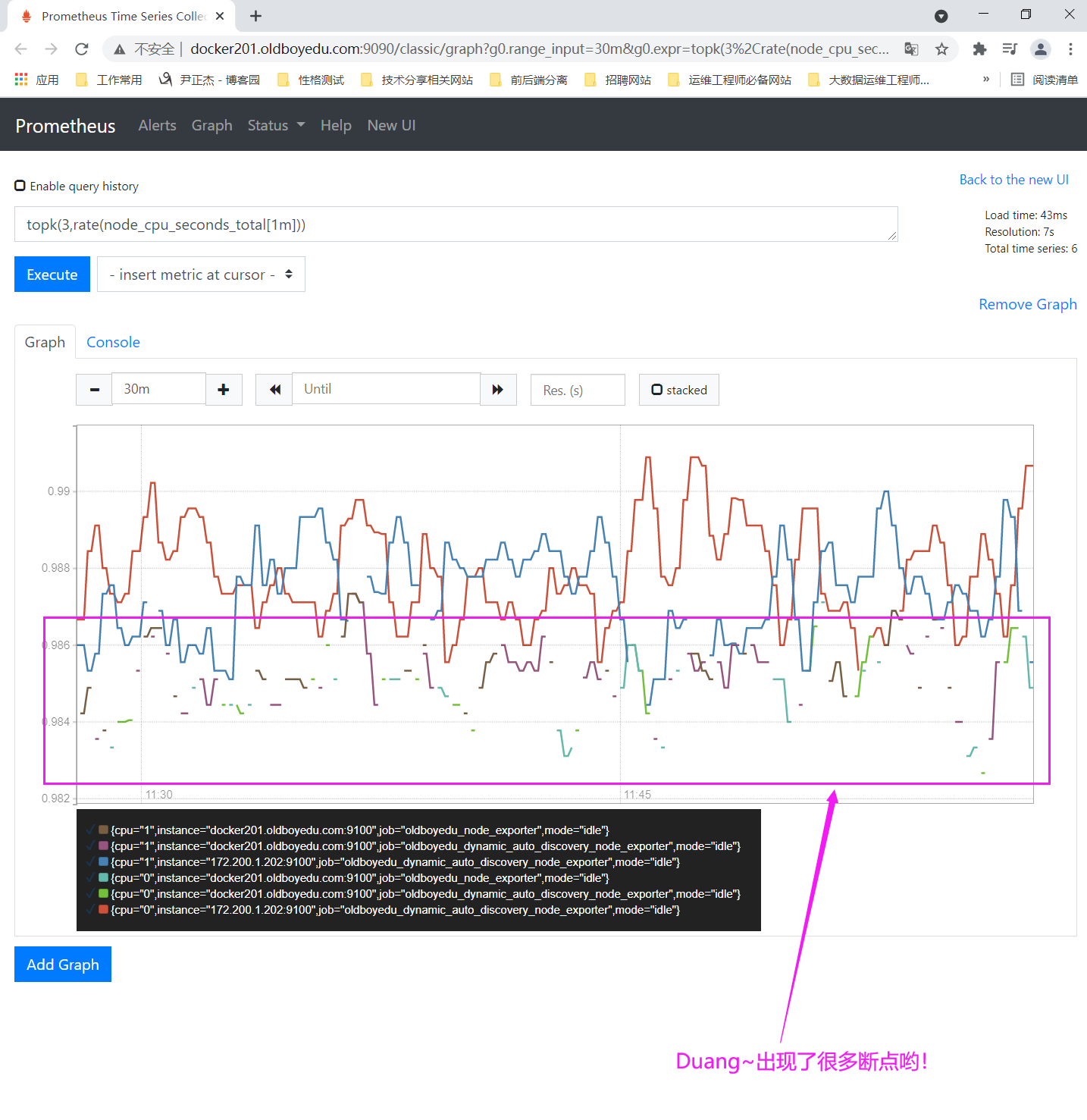
6.count函数
count函数:
把数值符合条件的,输出数目进行累计加和。一般用它进行一些模糊的监控判断。
比如说企业中有100台服务器,那么只有10台服务器CPU使用率高于80%的时候,这个时候不需要报警,当符合80%CPU的服务器数量超过70台的时候那么就触发报警。
举个例子:
count(oldboyedu_tcp_wait_conn > 500):
我们假设oldboyedu_tcp_wait_conn是咱们自定义的KEY,上述案例是找出当前(或者历史的)当前TCP等待数大于500的机器数量。7.prometheus的其它函数
prometheus提供的函数其实远远不止上面提到的6个,但我们学习上面的6个函数后,基本上就可以做一些基本的监控啦。
我个人感觉没必要把官网的每个函数都去学一遍,如果用到了在学也不迟!基本上上面6个函数也够咱们实现对服务的基础监控啦~当然,如果你有精力的话可以去学习一下官方的函数也没有毛病!
其它更多的函数,感兴趣的小伙伴,可以自行阅读官网:
https://prometheus.io/docs/prometheus/latest/querying/functions/
十一.课堂练习
1.计算各节点的CPU的总使用率,参考公式: "100% - (CPU空闲时间/总时间)"
(1)我们需要先找到查看CPU的key名称
node_cpu_seconds_total
(2)过滤cpu的空闲("idle")时间和全部CPU时间,使用"{}"做过滤
node_cpu_seconds_total{mode="idle"}:
过滤空闲的CPU时间。
node_cpu_seconds_total{}:
此处是可用省略"{}"的哟,因为里面没有任何参数,代表获取CPU的所有状态时间。
(3)把1分钟的增量的CPU时间取出来
increase(node_cpu_seconds_total{mode="idle"}[1m]):
1分钟内CPU空闲状态的增量。
increase(node_cpu_seconds_total[1m]):
1分钟内CPU所有状态的增量。
(4)将结果集进行加和统计
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])):
将1分钟内CPU空闲状态的增量数据进行加和计算。
sum(increase(node_cpu_seconds_total[1m])):
将1分钟内CPU所有状态的增量数据进行加和计算。
温馨提示:
细心的小伙伴可能已经发现了,这里会有一个坑,因为它不光把每一台机器的多个核加载一起,还会把所有机器的CPU也全都加到了一起,这意味着变成了集群CPU的平均值了,需要解决该问题。
(5)按照"instance"(机器名称)强行拆分成多组数据
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance):
将1分钟内CPU空闲状态的增量数据进行加和计算并按照"increase"(机器名称)强行拆分成多组数据。
sum(increase(node_cpu_seconds_total[1m])) by (instance):
将1分钟内CPU所有状态的增量数据进行加和计算并按照"increase"(机器名称)强行拆分成多组数据。
(6)计算CPU空闲时间的百分比
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)
(7)计算CPU使用率,计算公式: "(1 - CPU空闲时间的百分比) * 100%"。
(1 - ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100

2.计算用户态的CPU使用率
sum(increase(node_cpu_seconds_total{mode="user"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100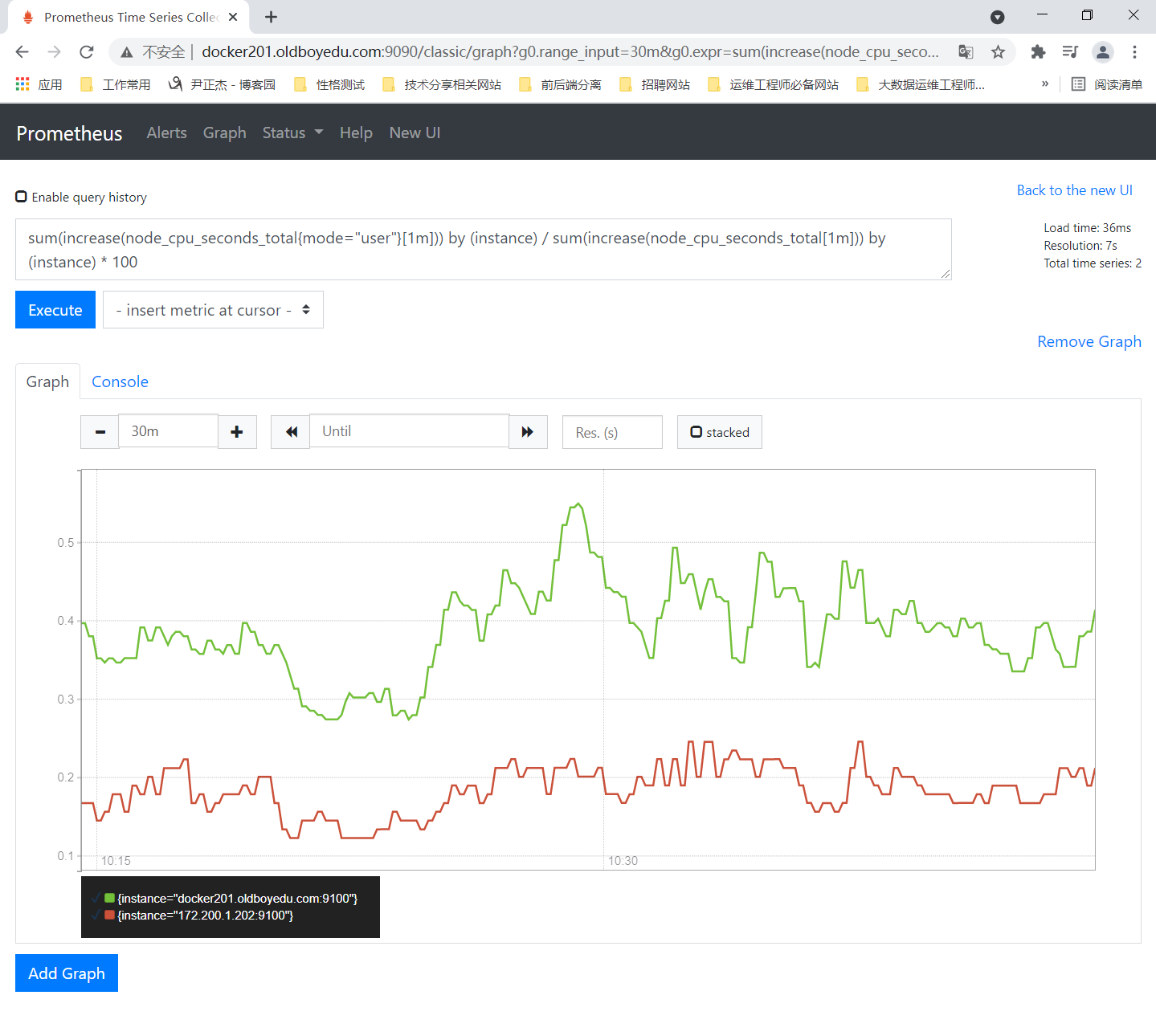
3.计算内核态的CPU使用率
sum(increase(node_cpu_seconds_total{mode="system"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100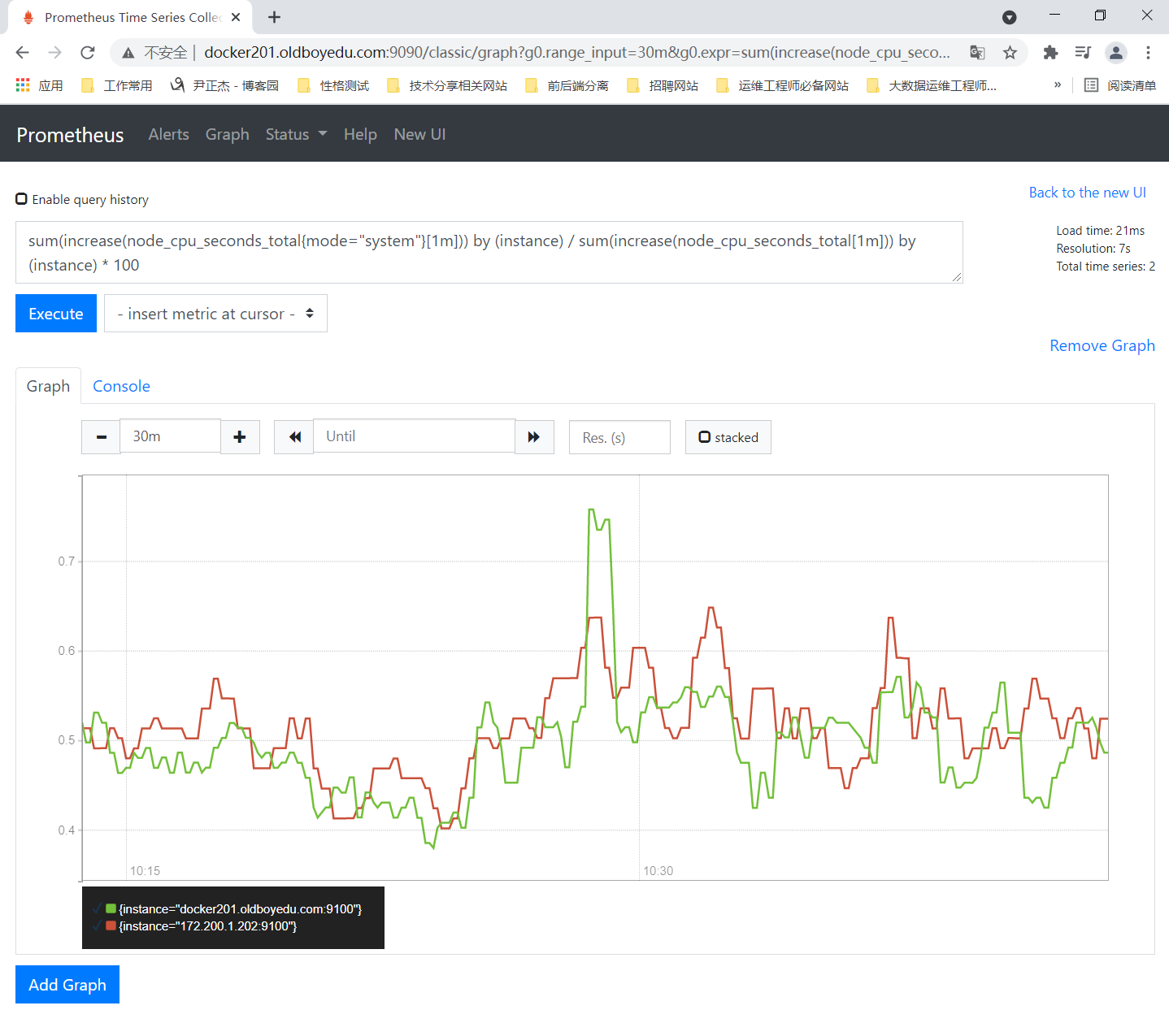
4.计算IO等待的CPU使用率
sum(increase(node_cpu_seconds_total{mode="iowait"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100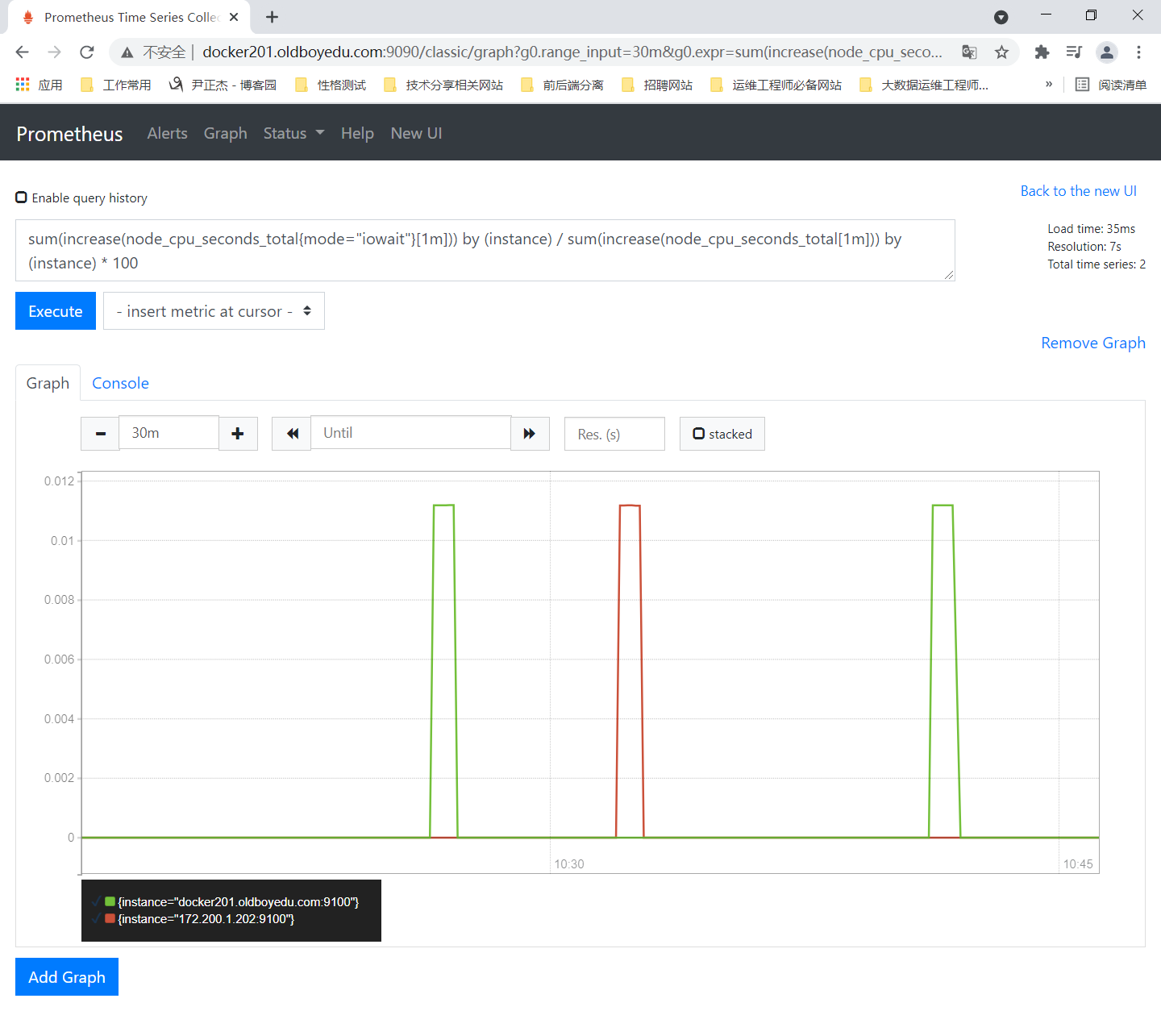
5.通过top命令查看CPU的使用率的启发
如下图所示,现在你应该知道top工具如何帮咱们计算这个百分比的值了吧?
prometheus计算公式的使用强制要求我们运维人员必须要对linux系统的深层次的知识有一定的掌握,不然连上面简单的计算公式都不会写哟~
prometheus操作起来看似很麻烦,但与此同时也给咱们提供了一个可用尽情发挥的平台。
温馨提示:
我们的确要对计算机底层的一些东西进行一些了解,这对于咱们以后称为运维架构师或者运维专家都只有好处,这些计算机底层基础的技能能体现出一个运维工程师的内功深厚,如果知识会上层应用层服务,而忽略底层的技术,则就好像笑傲江湖小说华山派中的剑宗和气宗的斗争。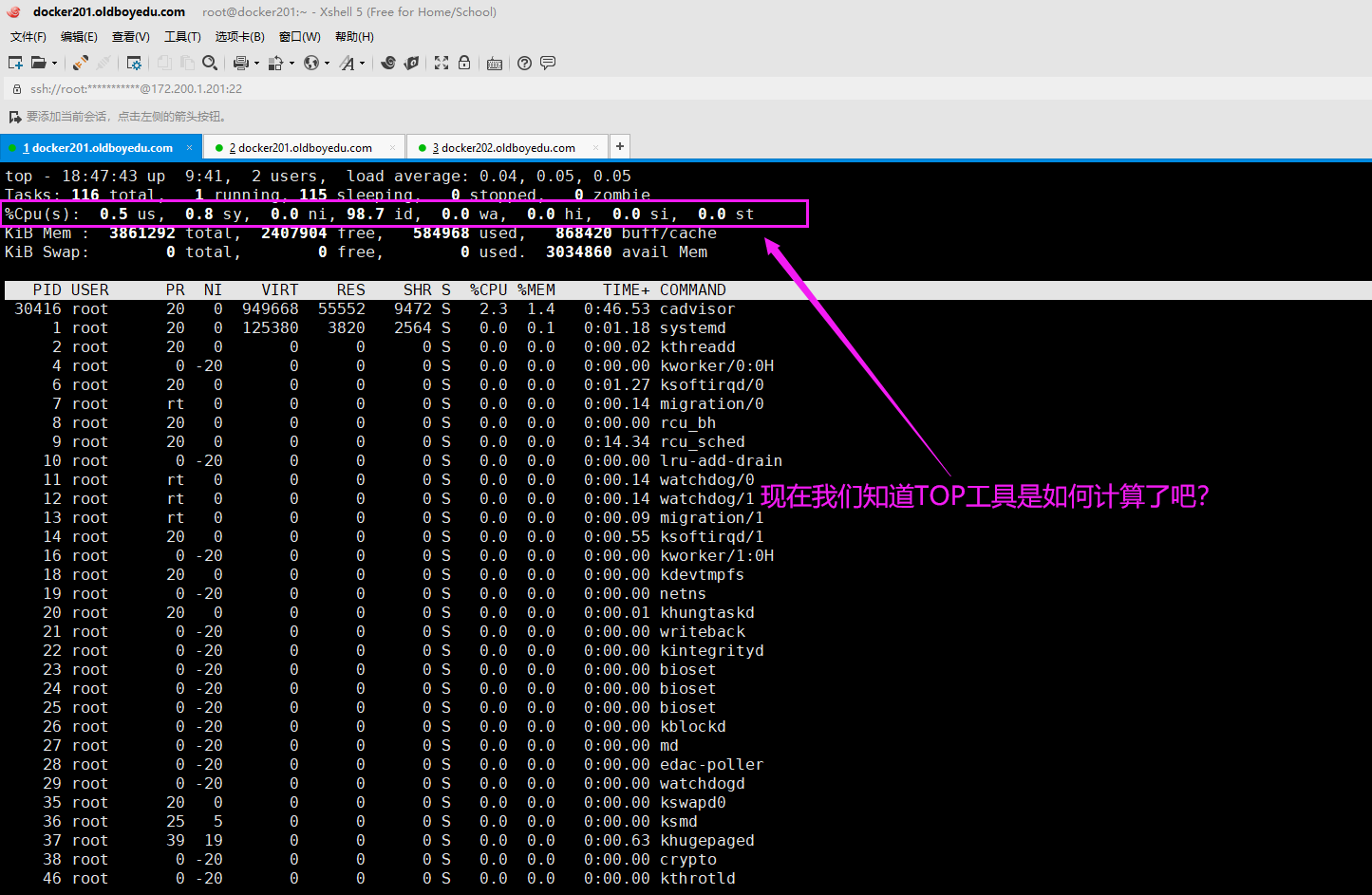
十二.pushgateway的部署
1.pushgateway概述
pushgateway是另一种采用被动推送(push)的方式(而不像exporter需要pull)获取监控数据的prometheus插件。
它是可以单独运行在任何节点(不一定是在被监控客户端)上的插件,然后通过用户自定义开发脚本把需要监控的数据发送给pushgateway,再由pushgateway暴露http接口,而后由把prometheus server去pull数据。
pushgateway组件本身是没有任何抓取监控数据功能的,它只能被动的等待监控数据被推送过来。2.下载pushgateway
下载地址:
https://prometheus.io/download/#pushgateway
gtihub地址:
https://github.com/prometheus/pushgateway
温馨提示:
pushgateway也是基于Go语言研发,但我们无需安装Golang环境,因为我们在编写GO语言程序时,可以将程序直接编译为对应操作系统的字节码文件哟~
3.解压并创建符号链接
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# tar xf pushgateway-1.4.1.linux-amd64.tar.gz -C /oldboy/softwares/
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# cd /oldboy/softwares/
[root@docker201.oldboyedu.com /oldboy/softwares]#
[root@docker201.oldboyedu.com /oldboy/softwares]# ln -sv pushgateway-1.4.1.linux-amd64 pushgateway
"pushgateway" -> "pushgateway-1.4.1.linux-amd64"
[root@docker201.oldboyedu.com /oldboy/softwares]#
4.配置环境变量并后台启动pushgateway
[root@docker201.oldboyedu.com ~]# cat /etc/profile.d/prometheus.sh
#!/bin/bash
# Add by Jason Yin for prometheus server
PROMETHEUS_HOME=/oldboy/softwares/prometheus
PATH=$PATH:$PROMETHEUS_HOME
# Add by Jason Yin for pushgateway
PUSHGATEWAY=/oldboy/softwares/pushgateway
PATH=$PATH:$PUSHGATEWAY
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# source /etc/profile.d/prometheus.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# nohup pushgateway &>>/var/log/oldboyedu_pushgateway.log &
[1] 46032
[root@docker201.oldboyedu.com ~]#
温馨提示:
服务启动成功后,会监听9091端口。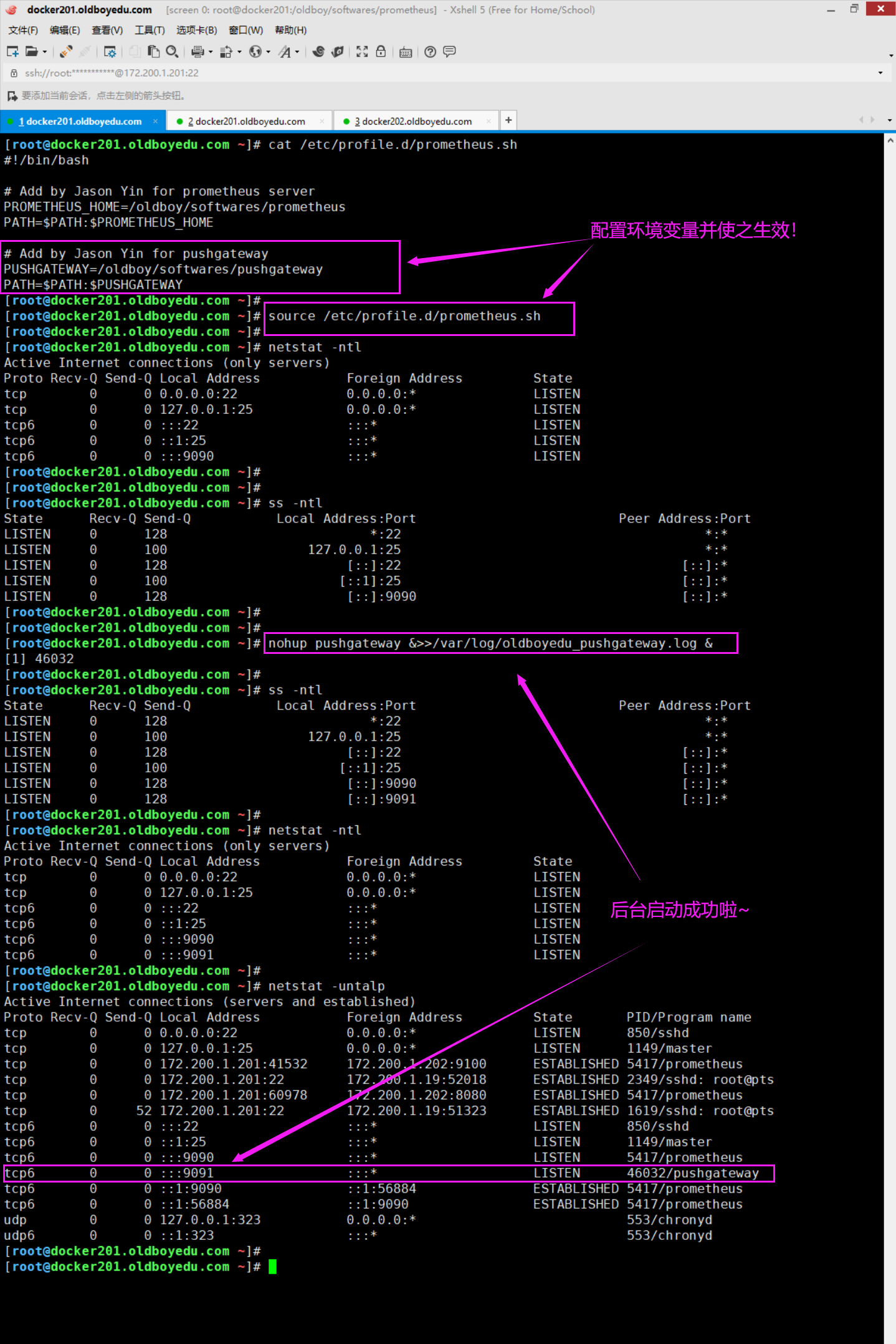
5.修改prometheus server的配置文件监听pushgateway组件并重启服务
[root@docker201.oldboyedu.com ~]# cat /oldboy/softwares/prometheus/prometheus.yml
...
scrape_configs:
...
- job_name: 'pushgateway'
static_configs:
- targets: ['docker201.oldboyedu.com:9091']
温馨提示:
修改配置文件后一定要重启prometheus server服务哟~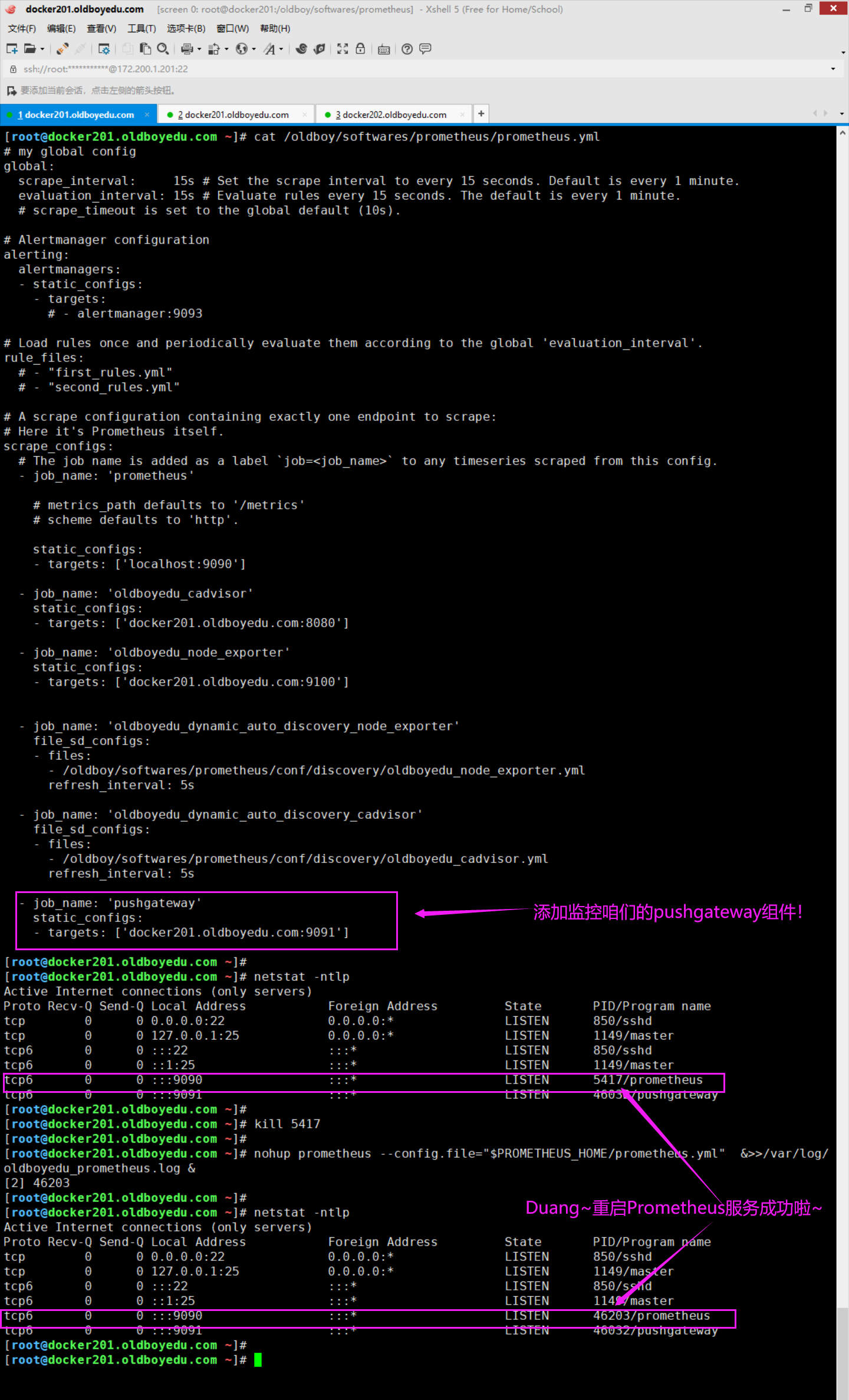
6.查看prometheus server的Web UI
如下图所示,我已经成功监听了"pushgateway"组件哟~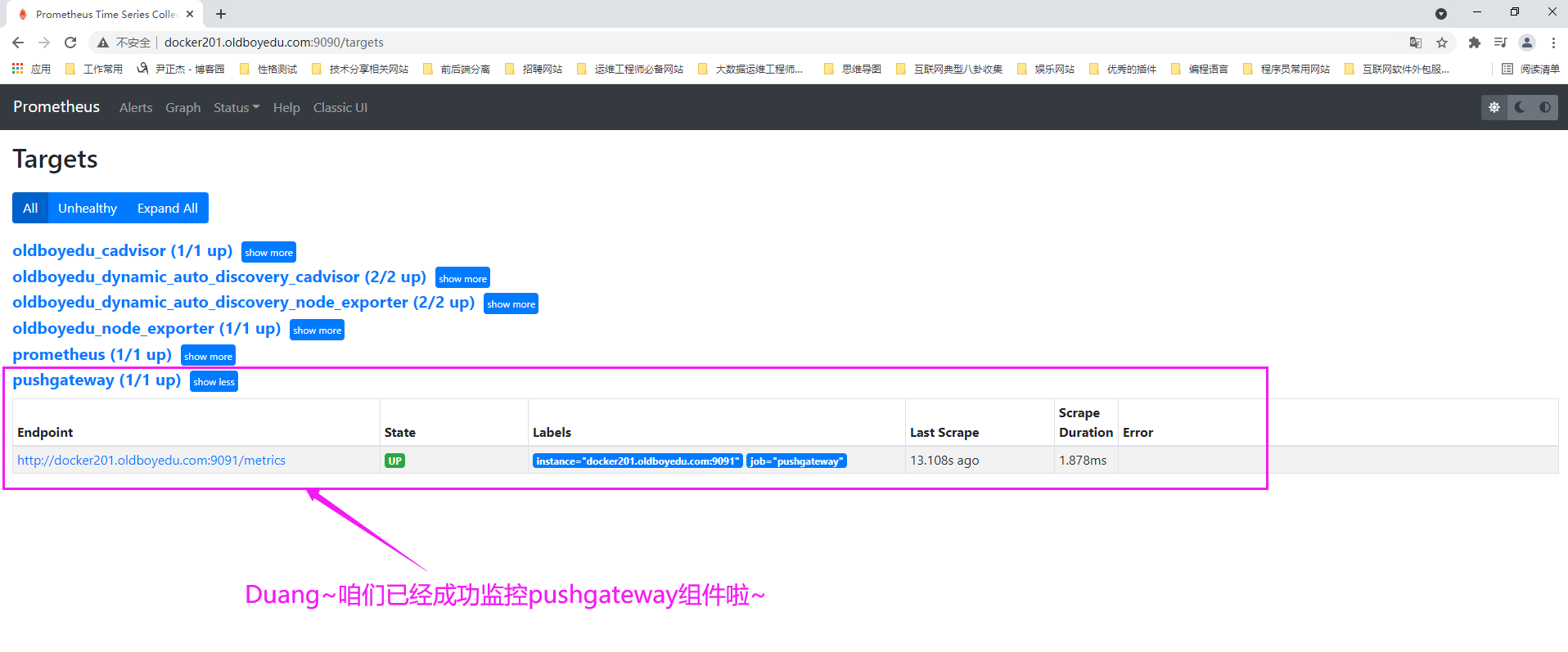
7.pushgateway的优缺点
优点:
灵活性更强。
缺点:
(1)存在单点瓶颈,加入有多个脚本同时发给一个pushgateway进程,如果该pushgateway进程挂掉了,那么监控数据也就没了。
(2)pushgateway并不能对发送过来的脚本采集数据进行更智能的判断,假如脚本中间采集出了问题,那么有问题的数据pushgateway组件会照单全收发送给Prometheus server。
温馨提示:
对于缺点一,建议大家在生产环境中多制作开启几个pushgateway进程,以便于备份使用。
对于缺点二,建议大家在编写脚本时要注意业务逻辑,尽可能避免脚本出错的情况发生。十三.监控TCP状态脚本案例
1.编写pushgateway的采集脚本
(1)编写采集脚本
[root@docker201.oldboyedu.com ~]# cat /oldboy/softwares/pushgateway/script/node_exporte.sh
#!/bin/bash
# author: Jason Yin
#instance_name=`hostname -i` # 该指令要求hosts文件必须有解析
instance_name=`hostname -f | cut -d '.' -f 1` # 以点号作为分割只取第一段作为本机的主机标签
# 要求机器名不能是"localhost"不然标签就没有区分了
if [ $instance_name == "localhost" ]
then
echo "Must FQDN hostname"
exit
fi
# 定义Prometheus抓取的KEY值,用于保存TCP的wait状态相关的连接(connections)
label="oldboyedu_tcp_wait_conn"
# 通过netstat工具抓取wait链接的数量
oldboyedu_tcp_wait_conn=`netstat -an| grep -i wait|wc -l`
# echo "$label $oldboyedu_tcp_wait_conn":
# 指定KEY和VALUE,注意中间是空格分割,不要尝试用其它字符分割。
# 如果你使用":"分割,可能在Prometheus server端是无法查询到数据的哟;
# "curl --data-binary":
# 表示发起的是POST请求数据为纯二进制数据。
# "http://docker201.oldboyedu.com:9091/metrics":
# 表示pushgateway的服务器地址
# "job/oldboyedu_linux":
# 表示第一个标签,相当于推送到prometheus server配置文件中"prometheus.yml"中定义的job名称。
# 该名称咱们完全是可以自定义的哟~
# "instance/$instance_name":
# 推送有关于instance这个变量其对应的主机名。
# 方便后期我们在prometheus server的WebUI界面使用{instance="server"}对主机进行过滤哟~
#
# 温馨提示:
# 注意Prometheus server支持的数据类型,如果类型不支持,则无法在Prometheus server的Web UI中进行查看。
#
echo "$label $oldboyedu_tcp_wait_conn" | curl --data-binary @- http://docker201.oldboyedu.com:9091/metrics/job/oldboyedu_linux/instance/$instance_name
[root@docker201.oldboyedu.com ~]#
(2)为脚本添加执行权限
[root@docker201.oldboyedu.com ~]# chmod +x /oldboy/softwares/pushgateway/script/node_exporte.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# ll /oldboy/softwares/pushgateway/script/node_exporte.sh
-rwxr-xr-x 1 root root 1735 6月 29 11:45 /oldboy/softwares/pushgateway/script/node_exporte.sh
[root@docker201.oldboyedu.com ~]#
(3)编写周期性任务
[root@docker201.oldboyedu.com ~]# crontab -l
* * * * * /oldboy/softwares/pushgateway/script/node_exporte.sh
* * * * * sleep 10;/oldboy/softwares/pushgateway/script/node_exporte.sh
* * * * * sleep 20;/oldboy/softwares/pushgateway/script/node_exporte.sh
* * * * * sleep 30;/oldboy/softwares/pushgateway/script/node_exporte.sh
* * * * * sleep 40;/oldboy/softwares/pushgateway/script/node_exporte.sh
* * * * * sleep 50;/oldboy/softwares/pushgateway/script/node_exporte.sh
[root@docker201.oldboyedu.com ~]#
温馨提示:
如下图所示,当数据采集后,我们就可以在pushgateway中看到数据啦。
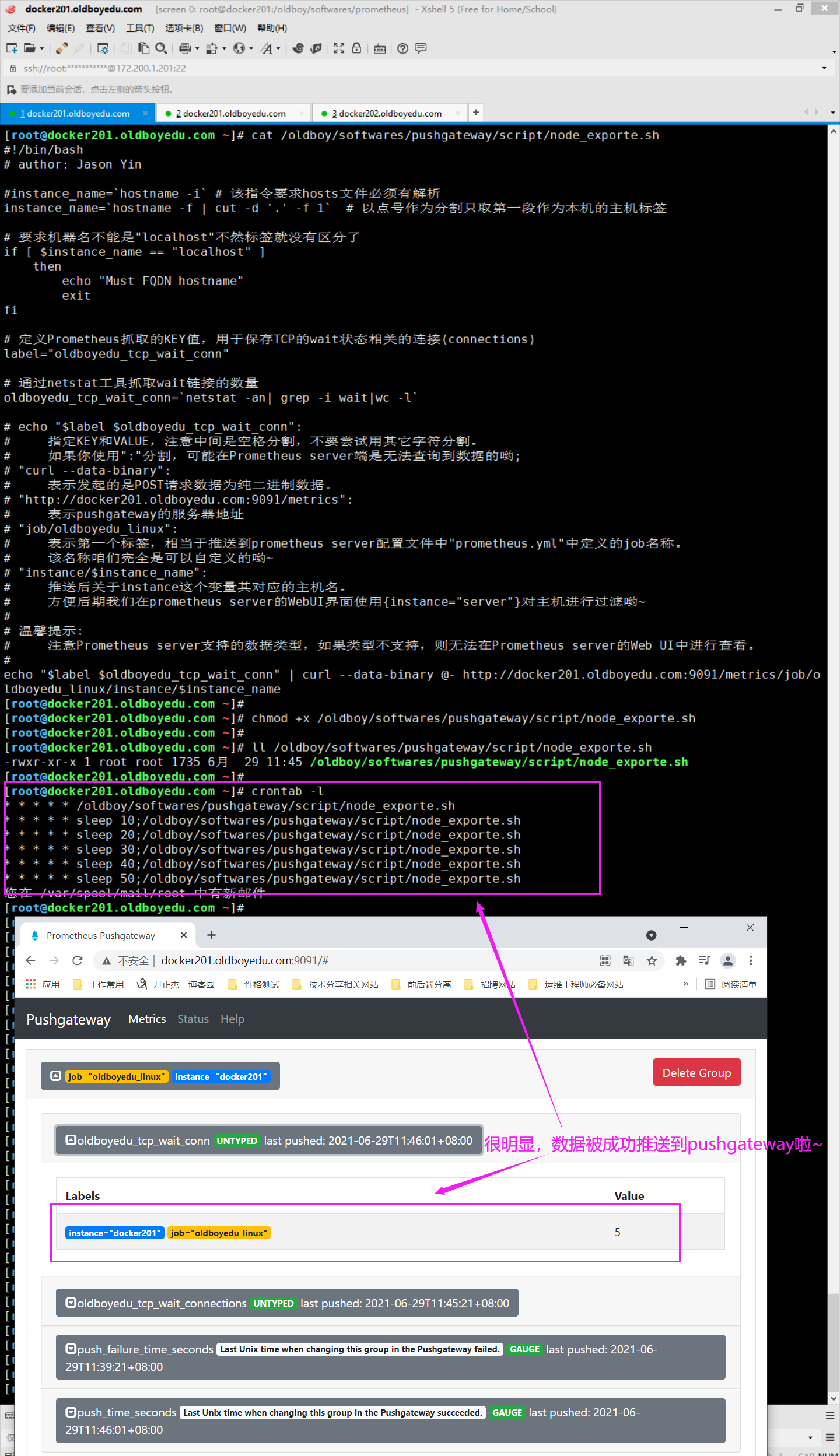
2.在promethues server的WebUI查看数据
如下图所示,我们可以直接基于自定义"oldboyedu_tcp_wait_conn"这个KEY进行数据的查看哟。
3.课堂练习
(1)请完成其它TCP状态的监控。
(2)监控老男孩教育内外网的丢包率;十四.监控容器运行时间脚本案例
1.编写监控脚本
[root@docker201.oldboyedu.com ~]# vim /oldboy/softwares/pushgateway/script/docker.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# cat /oldboy/softwares/pushgateway/script/docker.sh
#!/bin/bash
# author: Jason Yin
instance_name=`hostname -f | cut -d '.' -f 1` # 以点号作为分割只取第一段作为本机的主机标签
# 要求机器名不能是"localhost"不然标签就没有区分了
if [ $instance_name == "localhost" ]
then
echo "Must FQDN hostname"
exit
fi
# 获取所有运行的容器名称
allname=`docker ps --format "{{.Names}}"`
function dockerruntime(){
# 获取各个容器的启动时间
t=`docker inspect -f '{{.State.StartedAt}}' $1`
# 将时间转成时间戳
t1=`date +%s -d "$t"`
# 获取当前时间的时间戳
t2=`date +%s`
# 计算运行时间
let tt=$t2-$t1
echo $tt
return $tt
}
# 将需要往pushgateway上传的数据写入"oldboyedu_temp.log"文件
echo """# TYPE docker_runtime gauge
# HELP docker_runtime time sec""" > oldboyedu_temp.log
for i in ${allname}
do
t=`dockerruntime $i`
echo "oldboyedu_docker_runtime{name=\"$i\"} $t" >> oldboyedu_temp.log # 格式化写入数据
done
# 修改地址和参数名向特定的url上传数据,数据在oldboyedu_temp.log文件中
curl --data-binary "@oldboyedu_temp.log" http://docker201.oldboyedu.com:9091/metrics/job/docker_runtime/instance/$instance_name
# 清空临时文件
rm -f oldboyedu_temp.log
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# chmod +x /oldboy/softwares/pushgateway/script/docker.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# ll /oldboy/softwares/pushgateway/script/docker.sh
-rwxr-xr-x 1 root root 1286 6月 29 14:13 /oldboy/softwares/pushgateway/script/docker.sh
[root@docker201.oldboyedu.com ~]#
推荐阅读:
https://docs.docker.com/engine/reference/commandline/ps/#formatting
温馨提示:
注意给脚本添加相应的执行权限哟~2.添加计划任务
root@docker201.oldboyedu.com ~]# crontab -e
crontab: installing new crontab
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# crontab -l
...
* * * * * /oldboy/softwares/pushgateway/script/docker.sh
* * * * * sleep 10;/oldboy/softwares/pushgateway/script/docker.sh
* * * * * sleep 20;/oldboy/softwares/pushgateway/script/docker.sh
* * * * * sleep 30;/oldboy/softwares/pushgateway/script/docker.sh
* * * * * sleep 40;/oldboy/softwares/pushgateway/script/docker.sh
* * * * * sleep 50;/oldboy/softwares/pushgateway/script/docker.sh
[root@docker201.oldboyedu.com ~]# 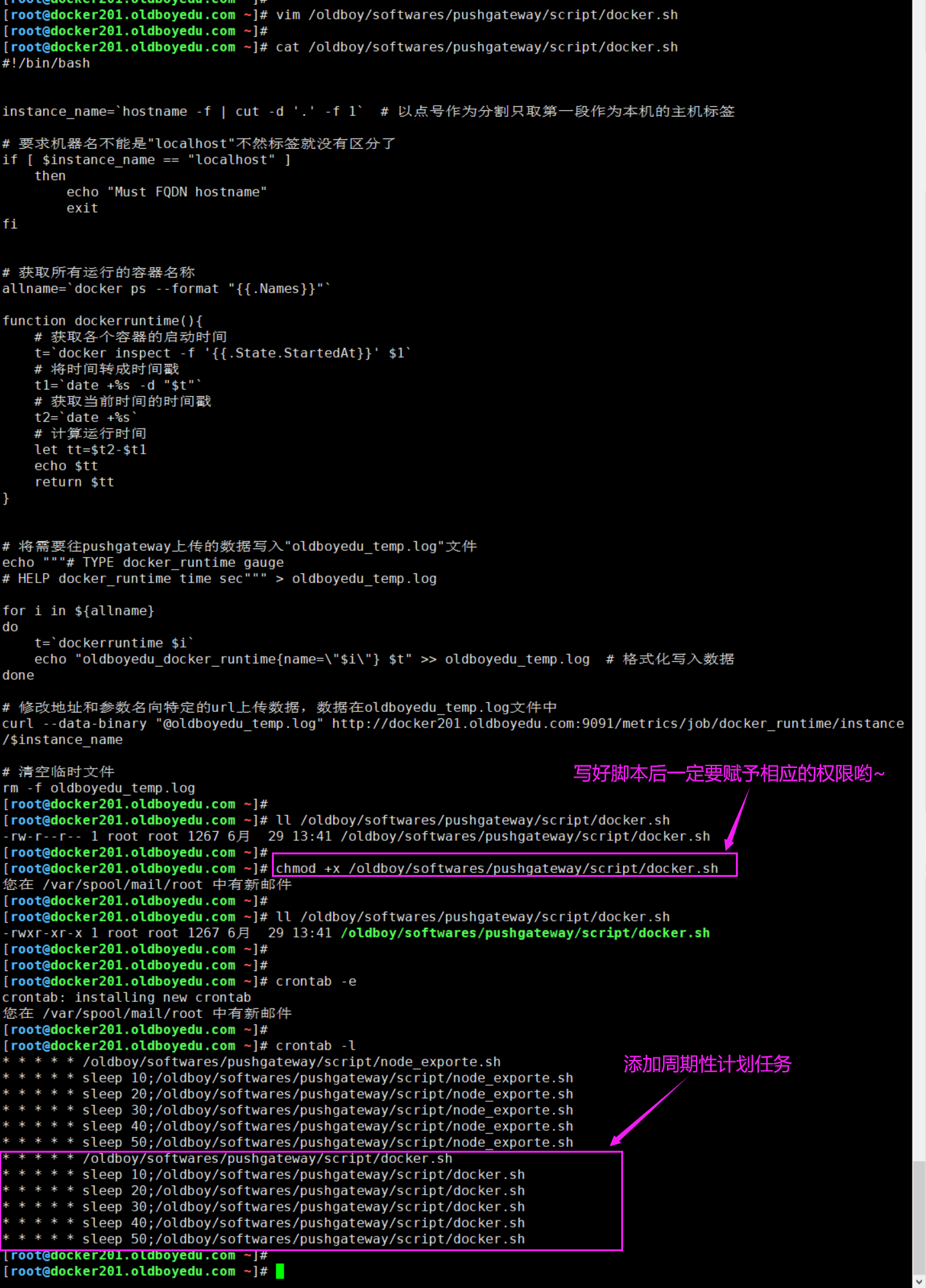
3.在Prometheus server的WebUI查看数据
如下图所示,直接输入"oldboyedu_docker_runtime"就能查看到咱们监控的数据啦!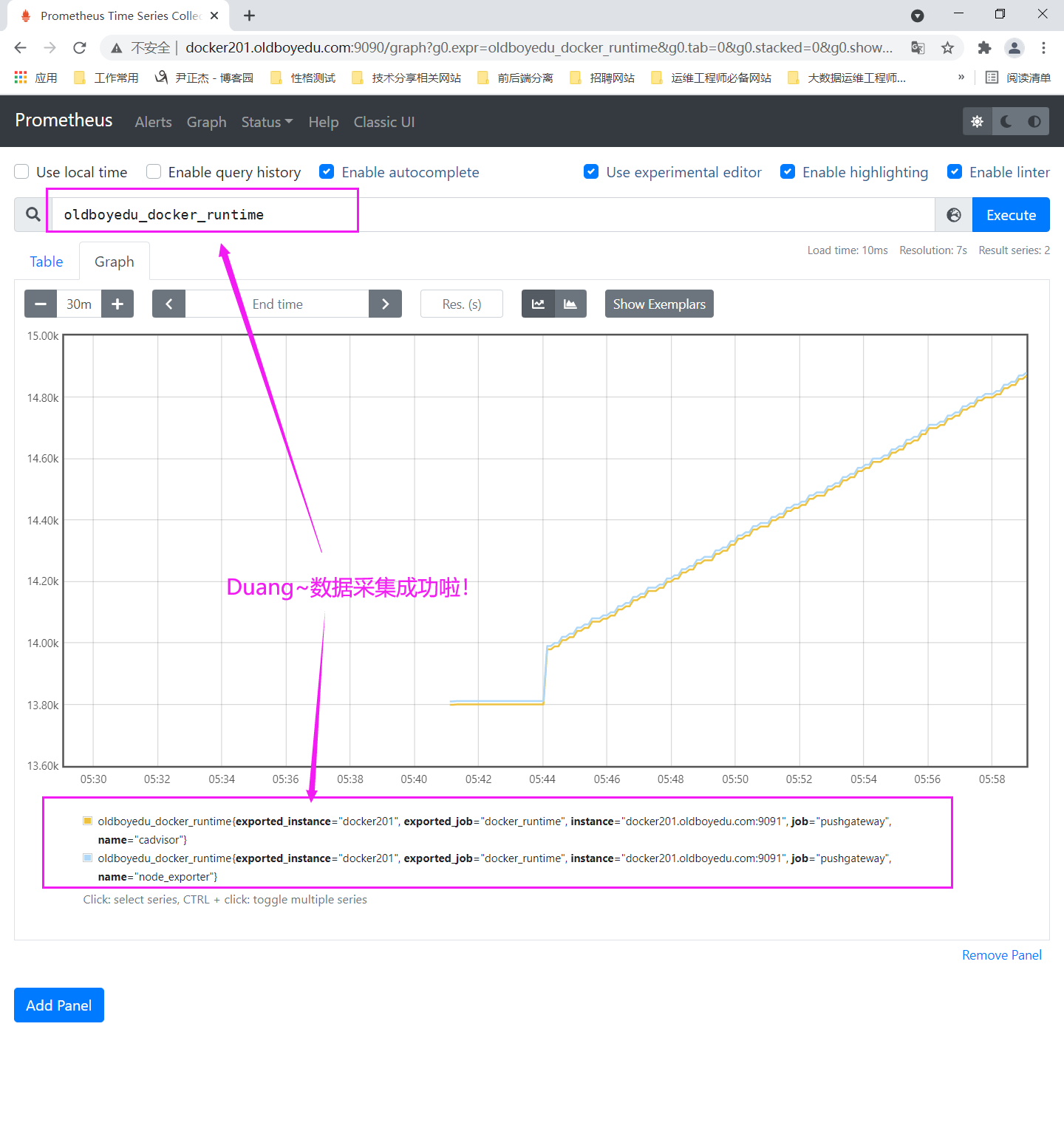
十五.prometheus微观架构(了解即可)
1.prometheus的存储细节刨析
(1)prometheus采用的是时间序列(time-series,简称TS)的方式以一种自定义的格式存储在本地硬盘上;
(2)prometheus的TS数据库以没两个小时为间隔来分block(块)存储,每一个块中又分为多个chunk文件,chunk文件是用来存储采集过来的数据的TS数据,metadata和索引文件(index);
(3)index文件是对metrics(prometheus中一次K/V采集数据叫做一个metrics)和labels(标签)进行索引之后存储在chunk中,chunk是作为存储的基本单位,index and metadata是作为子集;
(4)prometheus平时是采集过来的数据,先都存放在内存之中(Prometheus对内存的消耗还是不小的),以类似缓存的方式用于加快搜索和访问;
(5)当出现宕机时,prothmetheus有一种保护机制叫做WAL,可以将数据定期存储硬盘中以chrunk来表示,并在重新启动时用以恢复进入内存;2.有待更新....
推荐阅读:
https://www.yuque.com/ssebank/eoudn8/oysk2g#jB0sa十六.企业级监控案例
1.监控CPU
参考上面的课堂练习,笔记略,请配合Grafana结合使用。2.监控内存的使用率
参考案例:
(1 - (node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes) / node_memory_MemTotal_bytes) * 100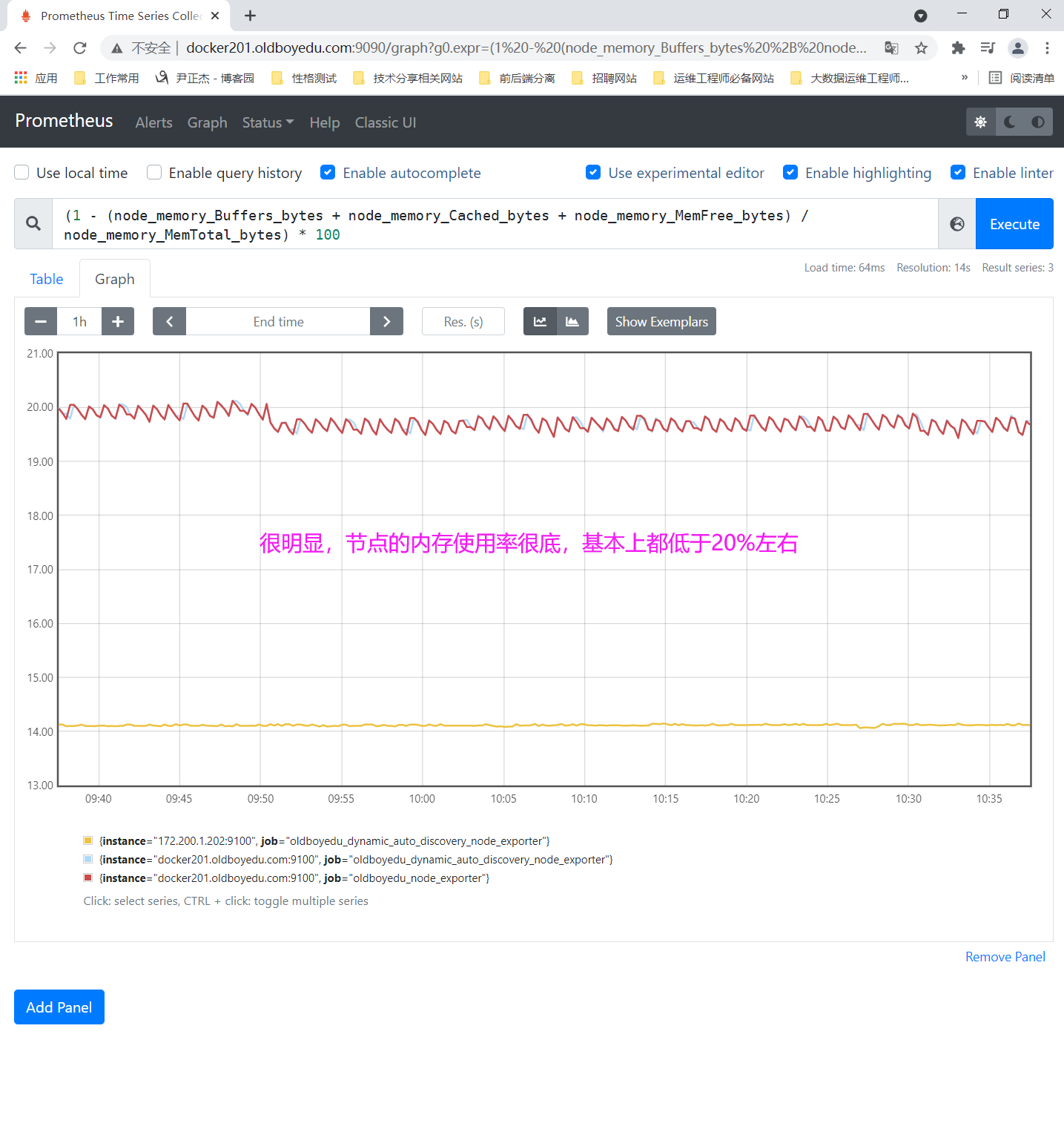
3.监控硬盘的使用情况
参考案例:
(node_filesystem_free_bytes / node_filesystem_size_bytes) < 0.95
温馨提示:
(1)生产环境中建议大家将0.95改为0.20,表示当空闲硬盘小于20%的时候就显示在图上;
(2)我之所以些0.95是因为我的空闲硬盘挺大的,为了让大家看到出图的效果而已。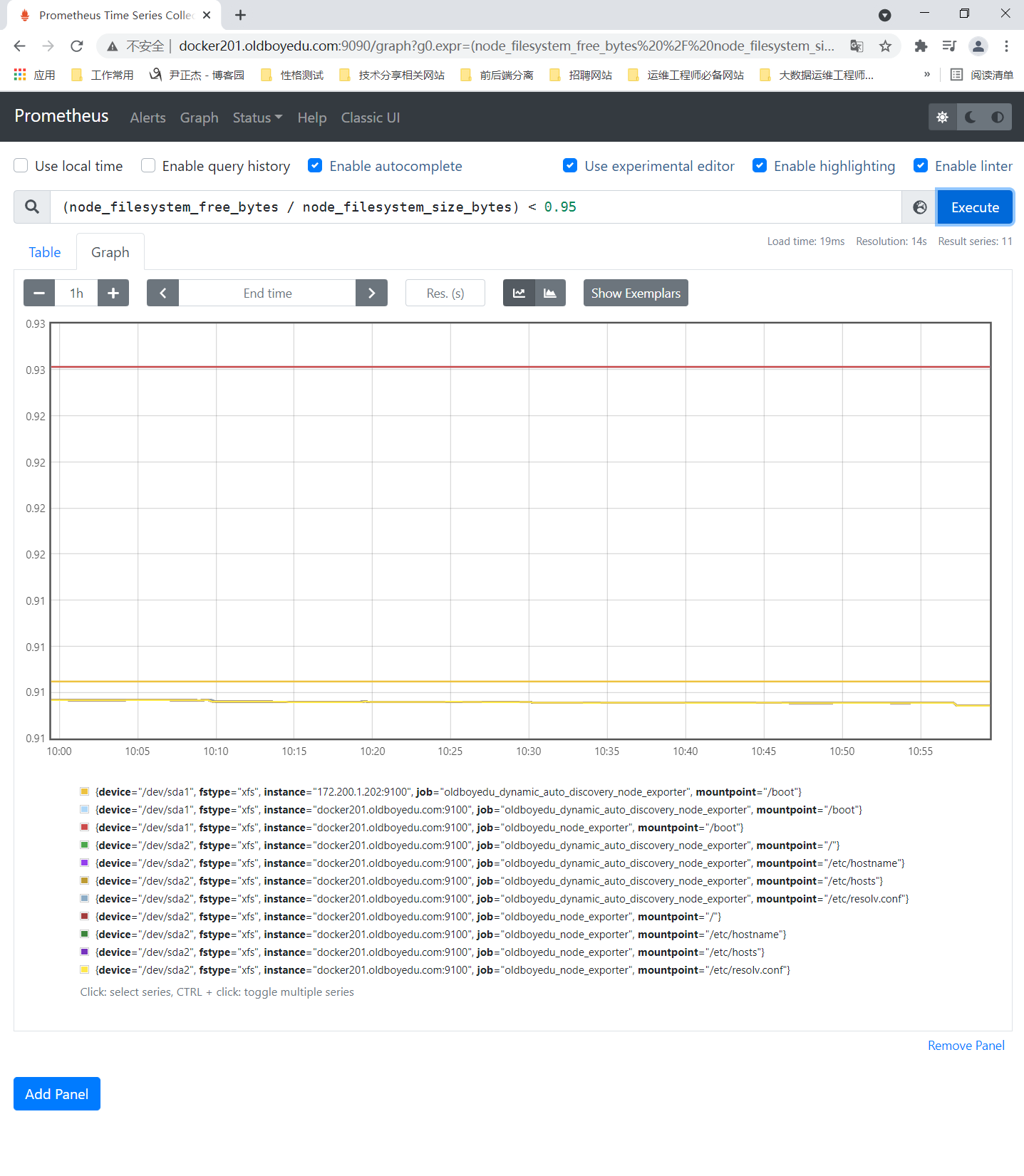
4.监控硬盘I/O使用情况
参考案例:
((rate(node_disk_read_bytes_total[1m]) + rate(node_disk_written_bytes_total[1m]))/1024/1024) > 0
温馨提示:
对于硬盘I/O是监控硬盘读写量的监控。上面的公式将默认的Bytes单位转换成MB单位啦。
如果磁盘I/O飙高,这意味着CPU的iowait也会飙高,这可能会触发大批量的报警,因此我们要实现一个"真实链路报警",从根源切断无效的报警。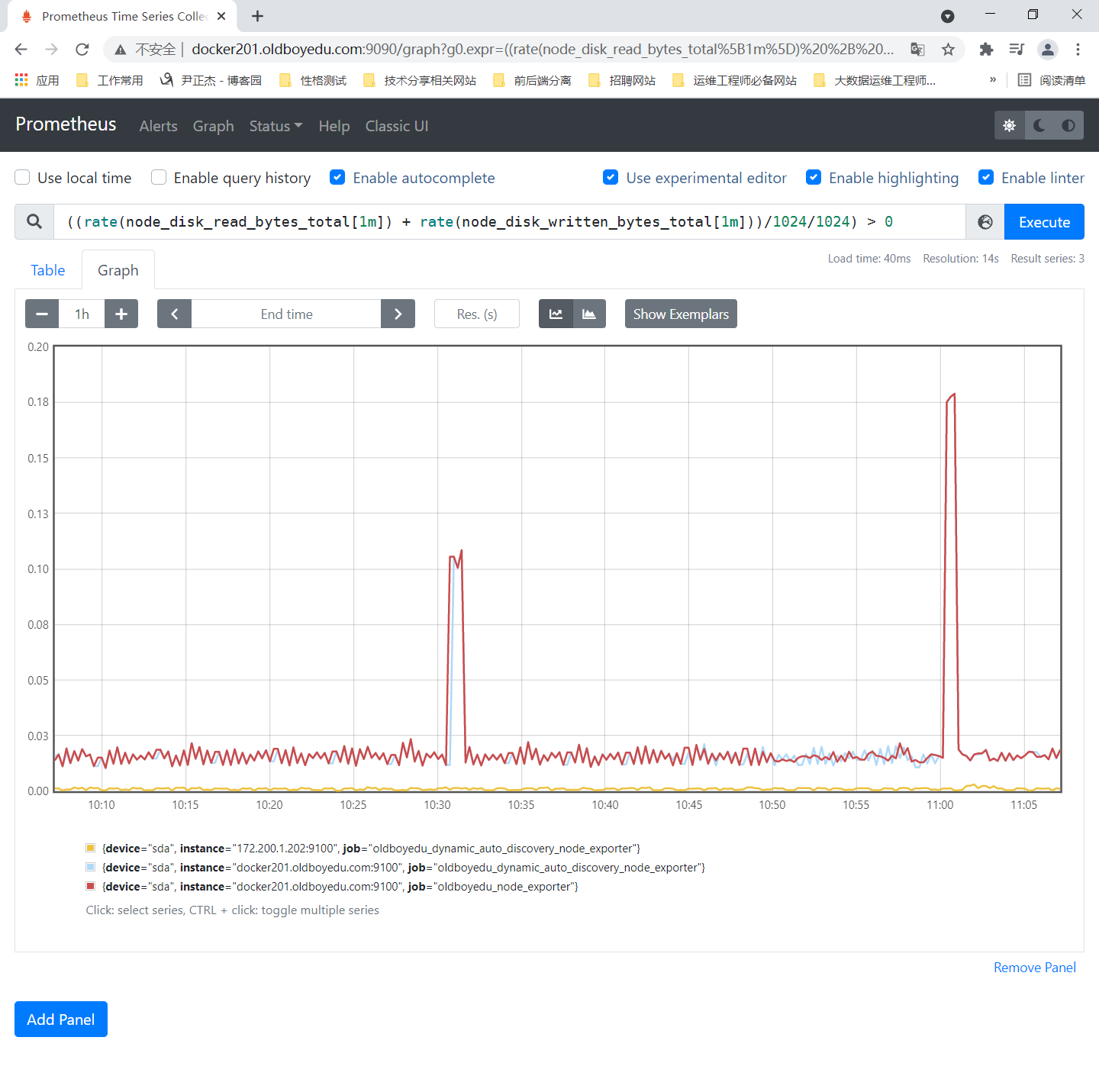
5.监控网络I/O
参考案例:
rate(node_network_transmit_bytes_total[1m]) / 1024 / 1024
node_network_transmit_bytes_total:
网络传输字节数。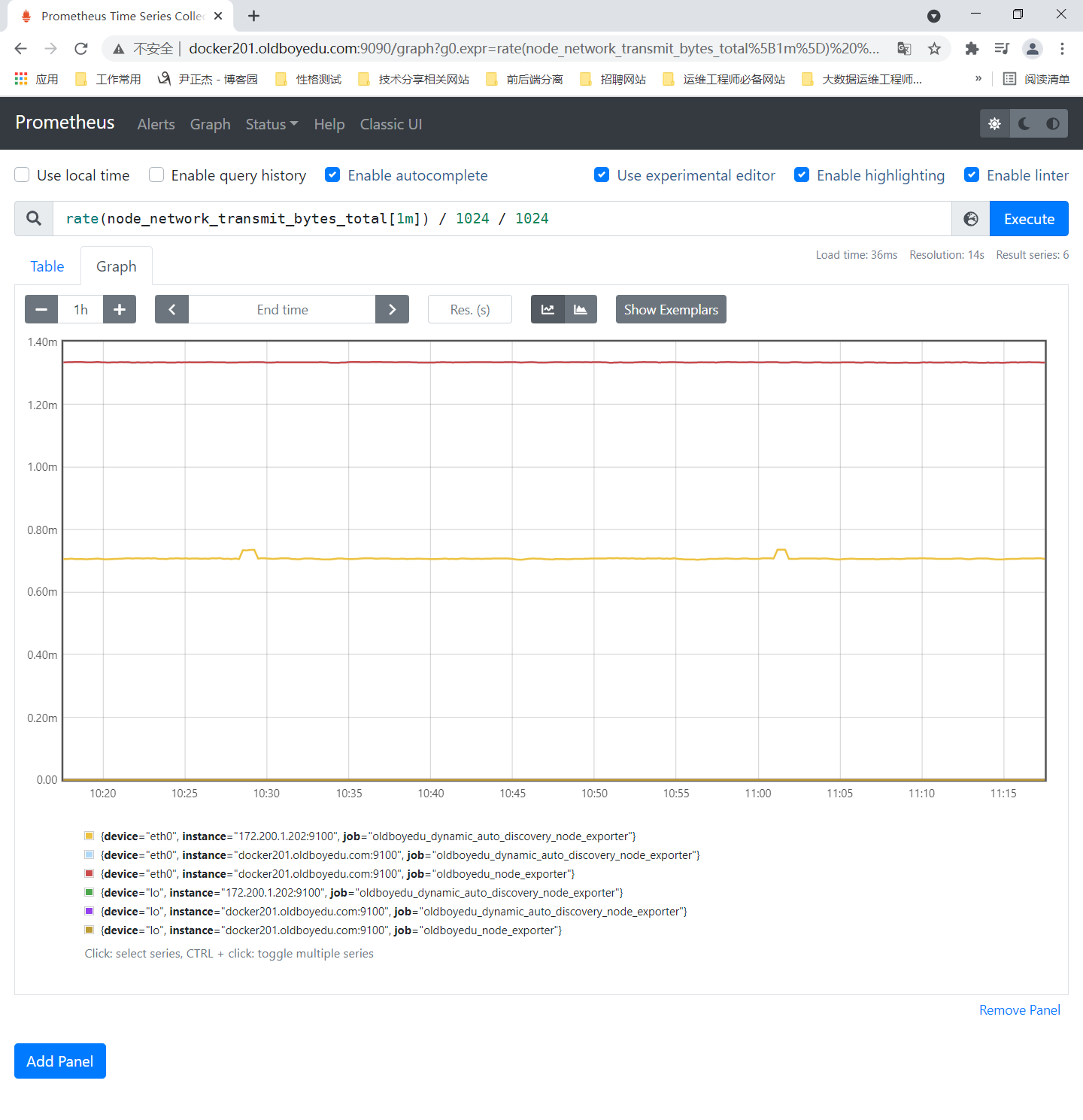
6.监控文件描述符
参考案例:
(node_filefd_allocated / node_filefd_maximum) * 100
node_filefd_allocated:
已分配的文件描述符。
node_filefd_maximum:
一个进程运行最大打开文件描述符的总量。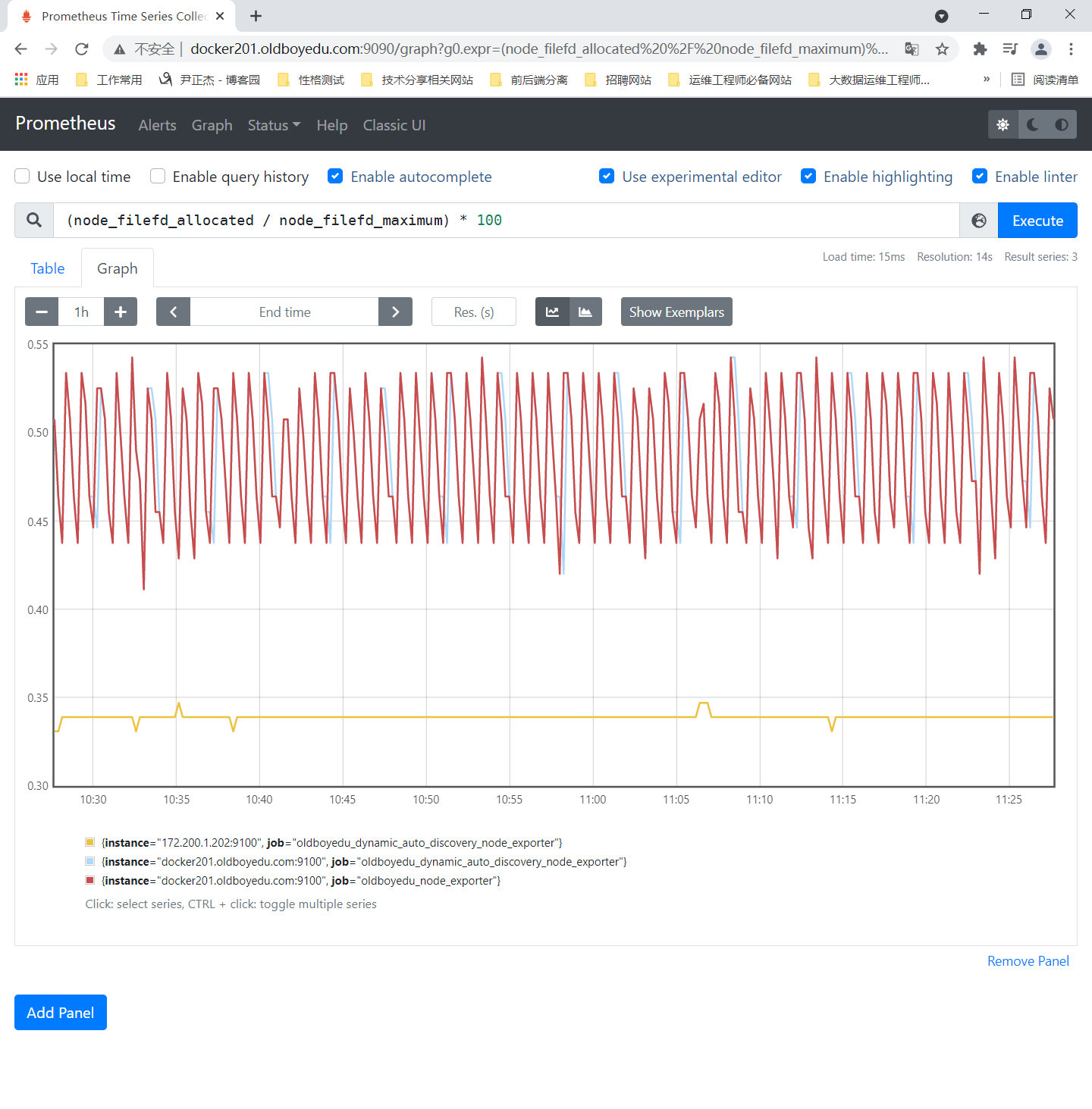
7.网络延迟及丢包率监控
(1)编写脚本
[root@docker201.oldboyedu.com ~]# cat /oldboy/softwares/pushgateway/script/network_delay.sh
#!/bin/bash
# author: Jason Yin
#instance_name=`hostname -i` # 该指令要求hosts文件必须有解析
instance_name=`hostname -f | cut -d '.' -f 1` # 以点号作为分割只取第一段作为本机的主机标签
# 要求机器名不能是"localhost"不然标签就没有区分了
if [ $instance_name == "localhost" ]
then
echo "Must FQDN hostname"
exit
fi
# 指定需要ping的主机
monitoring_site="www.oldboyedu.com"
# 获取丢包率相关字段
# -q:
# 安静模式ping,即不输出每次ping的返回的中间结果,仅返回最终的结果。
# -A:
# 启用并行的ping效果,可以加快ping的处理过程。
# -s:
# 一个ping包的大小。
# -W:
# 执行ping命令最大的延迟等待时间(timeout),以ms为单位。
# -c:
# 发送多少个数据包。
package_loss_rate=`timeout 5 ping -q -A -s 500 -W 1000 -c 100 $monitoring_site | grep transmitted | awk '{print $6}'`
# 获取延迟情况的相关字段(本质上是执行ping命令所耗费的时间哟~)
delay_time=`timeout 5 ping -q -A -s 500 -W 1000 -c 100 $monitoring_site | grep transmitted | awk '{print $10}'`
# 获取数字类型
package_loss_rate_number=`echo $package_loss_rate | sed "s/%//g"`
delay_time_number=`echo $delay_time | sed "s/ms//g"`
# 将数据上传到pushgateway
echo "oldboyedu_linux_package_loss_rate_$instance_name $package_loss_rate_number" | curl --data-binary @- http://docker201.oldboyedu.com:9091/metrics/job/oldboyedu_linux_package_loss_rate/instance/localhost:9092
echo "oldboyedu_linux_delay_time_$instance_name $delay_time_number" | curl --data-binary @- http://docker201.oldboyedu.com:9091/metrics/job/oldboyedu_linux_package_loss_rate/instance/localhost:9092
[root@docker201.oldboyedu.com ~]#
(2)编写周期性任务
[root@docker201.oldboyedu.com ~]# crontab -l
...
* * * * * /oldboy/softwares/pushgateway/script/network_delay.sh
* * * * * sleep 10;/oldboy/softwares/pushgateway/script/network_delay.sh
* * * * * sleep 20;/oldboy/softwares/pushgateway/script/network_delay.sh
* * * * * sleep 30;/oldboy/softwares/pushgateway/script/network_delay.sh
* * * * * sleep 40;/oldboy/softwares/pushgateway/script/network_delay.sh
* * * * * sleep 50;/oldboy/softwares/pushgateway/script/network_delay.sh
[root@docker201.oldboyedu.com ~]#
(3)在Prometheus server中查看KEY
oldboyedu_linux_package_loss_rate_docker201
oldboyedu_linux_delay_time_docker201
温馨提示:
(1)对于较多的网络监控我建议还是使用专业的smokeping监控系统,尤其是在IDC公司,smokeping基本上是必用软件哟。
(2)我这里是为了让大家练习Prometheus而出的练习题;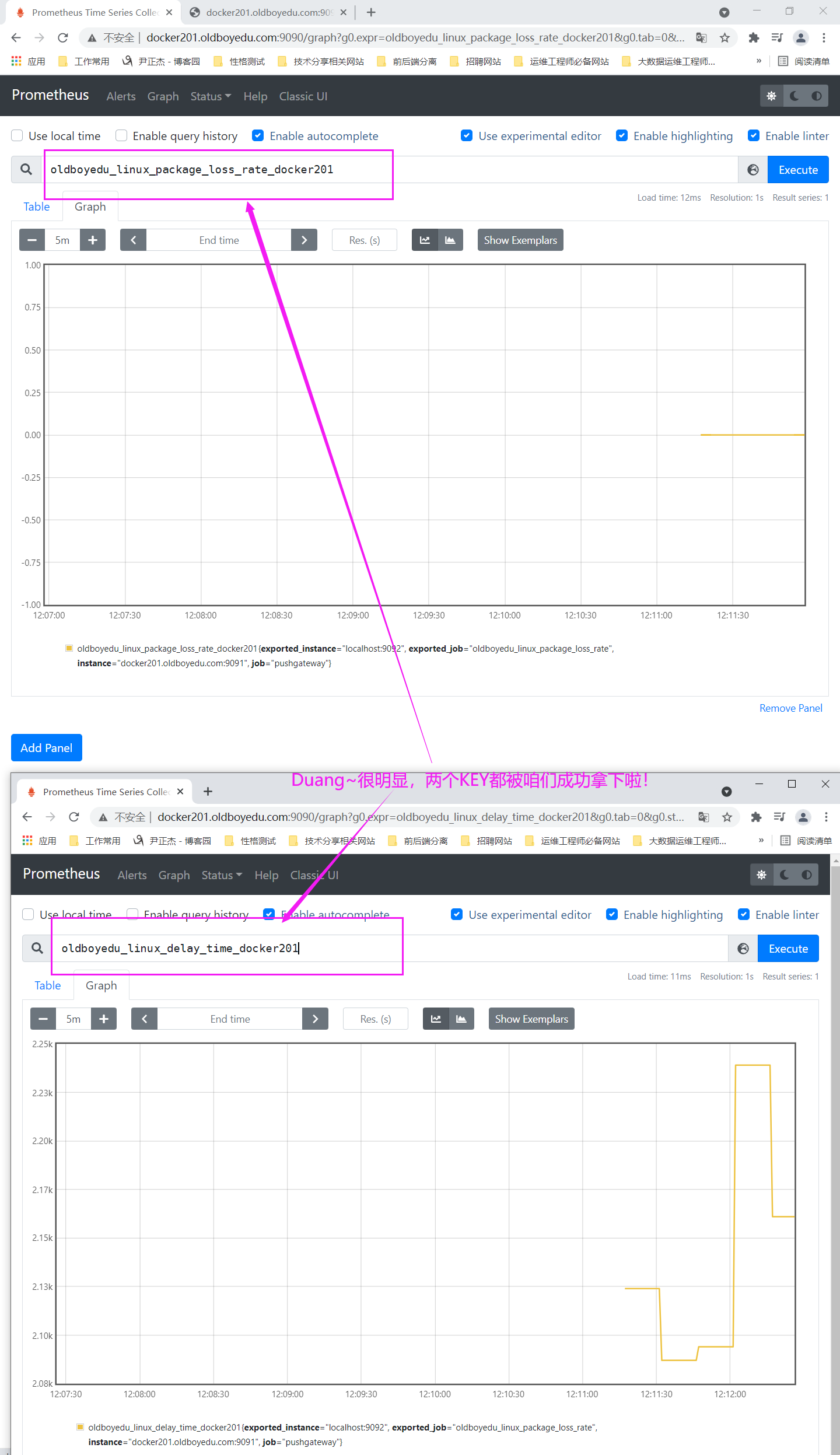
十七.alertmanager实战案例
1.alertmanager概述
alertmanager是Prometheus用于触发报警的组件。
下载地址:
https://prometheus.io/download/#alertmanager
温馨提示:
alertmanager的下载地址如下图所示。
2.解压软件包并创建符号连接
[root@docker201.oldboyedu.com ~]# tar xf alertmanager-0.22.2.linux-amd64.tar.gz -C /oldboy/softwares/
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# cd /oldboy/softwares/
[root@docker201.oldboyedu.com /oldboy/softwares]#
[root@docker201.oldboyedu.com /oldboy/softwares]# ln -sv alertmanager-0.22.2.linux-amd64 alertmanager
"alertmanager" -> "alertmanager-0.22.2.linux-amd64"
[root@docker201.oldboyedu.com /oldboy/softwares]#
3.修改alertmanager的配置文件
global:
resolve_timeout: 5m
smtp_from: 'xxxxxxxx@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: 'xxxxxxxx@qq.com'
smtp_auth_password: 'xxxxxxxxxxxxxxx'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxxxx@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
相关参数说明:
global:
resolve_timeout:
解析超时时间。
smtp_from:
发件人邮箱地址。
smtp_smarthost:
邮箱的服务器的地址及端口,例如: 'smtp.qq.com:465'。
smtp_auth_username:
发送人的邮箱用户名。
smtp_auth_password:
发送人的邮箱密码。
smtp_require_tls:
是否基于tls加密。
smtp_hello:
邮箱服务器,例如: 'qq.com'。
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval:
重复报警的间隔时间,如果没有解即报警问题,则会间隔指定时间一直触发报警,比如:5m。
receiver:
采用什么方式接收报警,例如'email'。
receivers:
- name:
定义接收者的名称,注意这里的name要和上面的route对应,例如: 'email'
email_configs:
- to:
邮箱发给谁。
send_resolved: true
inhibit_rules:
- source_match:
severity:
匹配报警级别,例如: 'critical'。
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
温馨提示:
163邮箱修改授权码步骤很简单,依次点击"设置" ---> "POP3/SMTP/IMAP" ---> "新增授权密码"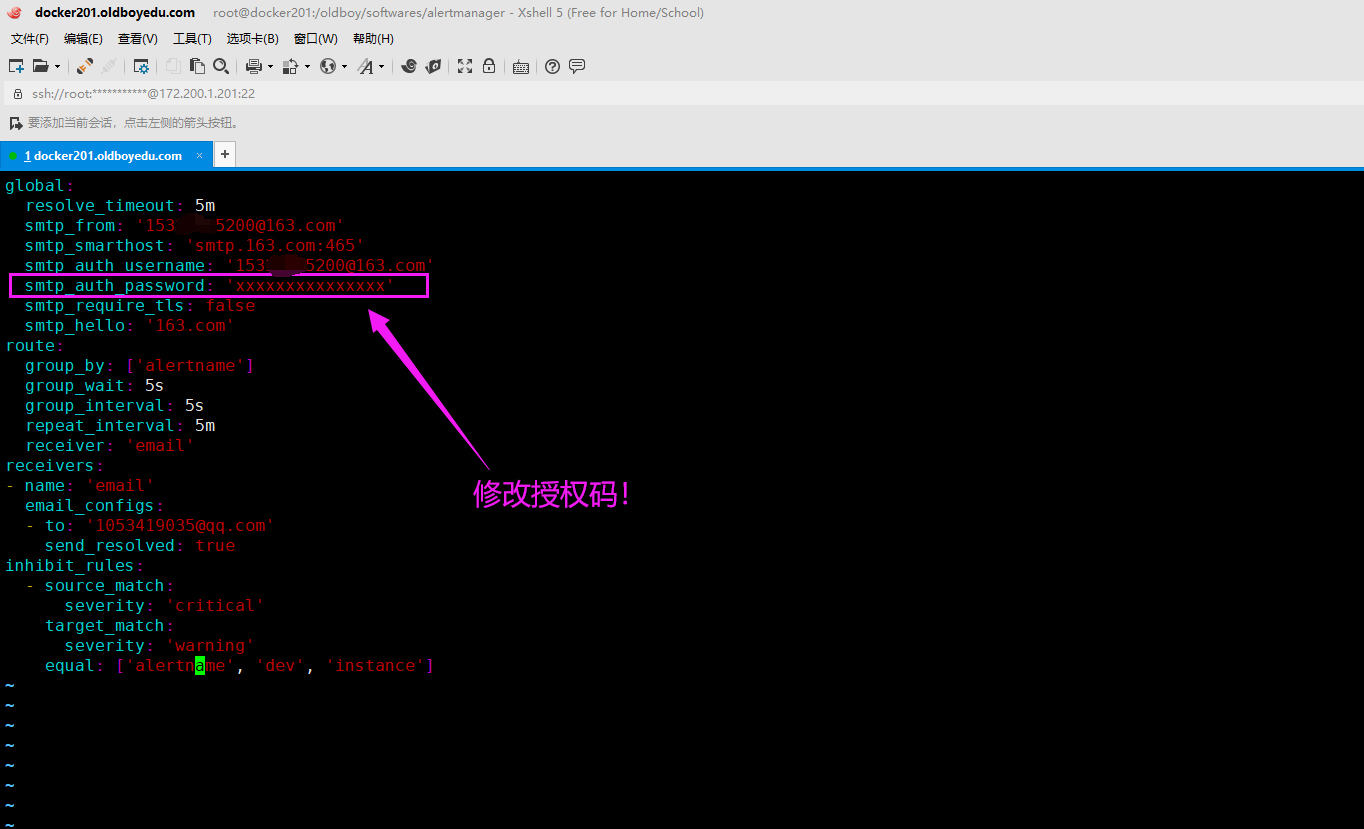
4.修改环境变量并后台启动alertmanager服务
[root@docker201.oldboyedu.com ~]# vim /etc/profile.d/prometheus.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# cat /etc/profile.d/prometheus.sh
#!/bin/bash
...
# Add by Jason Yin for alertmanager
ALERTMANAGER=/oldboy/softwares/alertmanager
PATH=$PATH:$ALERTMANAGER
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# source /etc/profile.d/prometheus.sh
[root@docker201.oldboyedu.com ~]#
[root@docker201.oldboyedu.com ~]# nohup alertmanager --config.file="$ALERTMANAGER/alertmanager.yml" &>/var/log/oldboyedu_alertmanager.log &
[1] 1850
[root@docker201.oldboyedu.com ~]#
温馨提示:
alertmanager可能会监听9093和9094端口哟~5.修改Prometheus server的服务并重启服务

(1)修改prometheus server的配置文件,主要配置alerting和rule_files这两个部分。
[root@docker201.oldboyedu.com ~]# vim /oldboy/softwares/prometheus/prometheus.yml
...
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
- docker201.oldboyedu.com:9093
rule_files:
- "oldboyedu_rules.yml"
...
(2)修改配置文件
[root@docker201.oldboyedu.com /oldboy/softwares/prometheus]# cat oldboyedu_rules.yml
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="oldboyedu_node_exporter"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"
[root@docker201.oldboyedu.com /oldboy/softwares/prometheus]#
温馨提示:
(1)Prometheus server配置完毕千万记得要重启哈,否则配置可能不生效哟~
(2)如下图所示,请验证altermanager是否正常工作;
(3)"up{job="oldboyedu_node_exporter"} == 1"表示正常现象;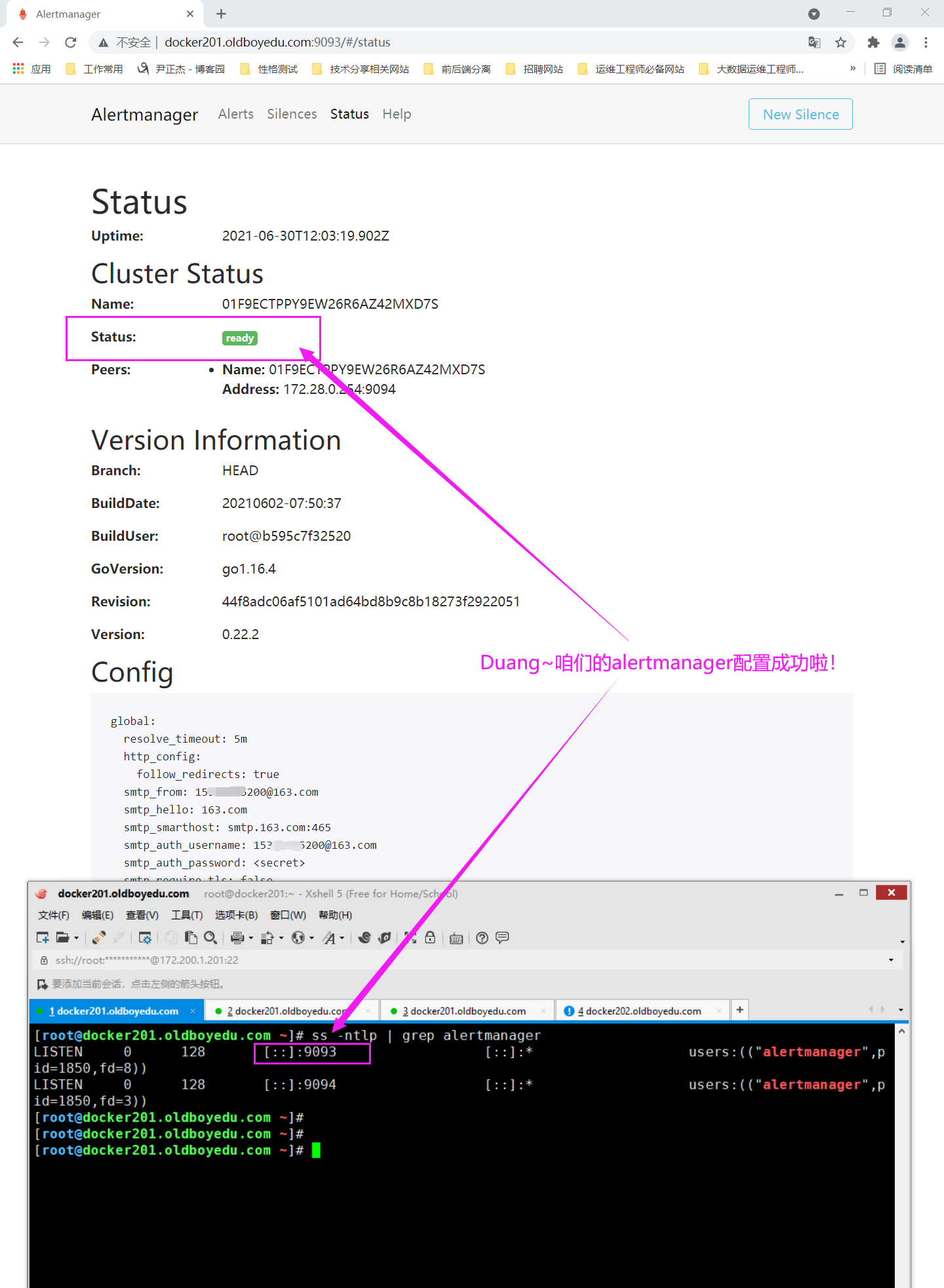
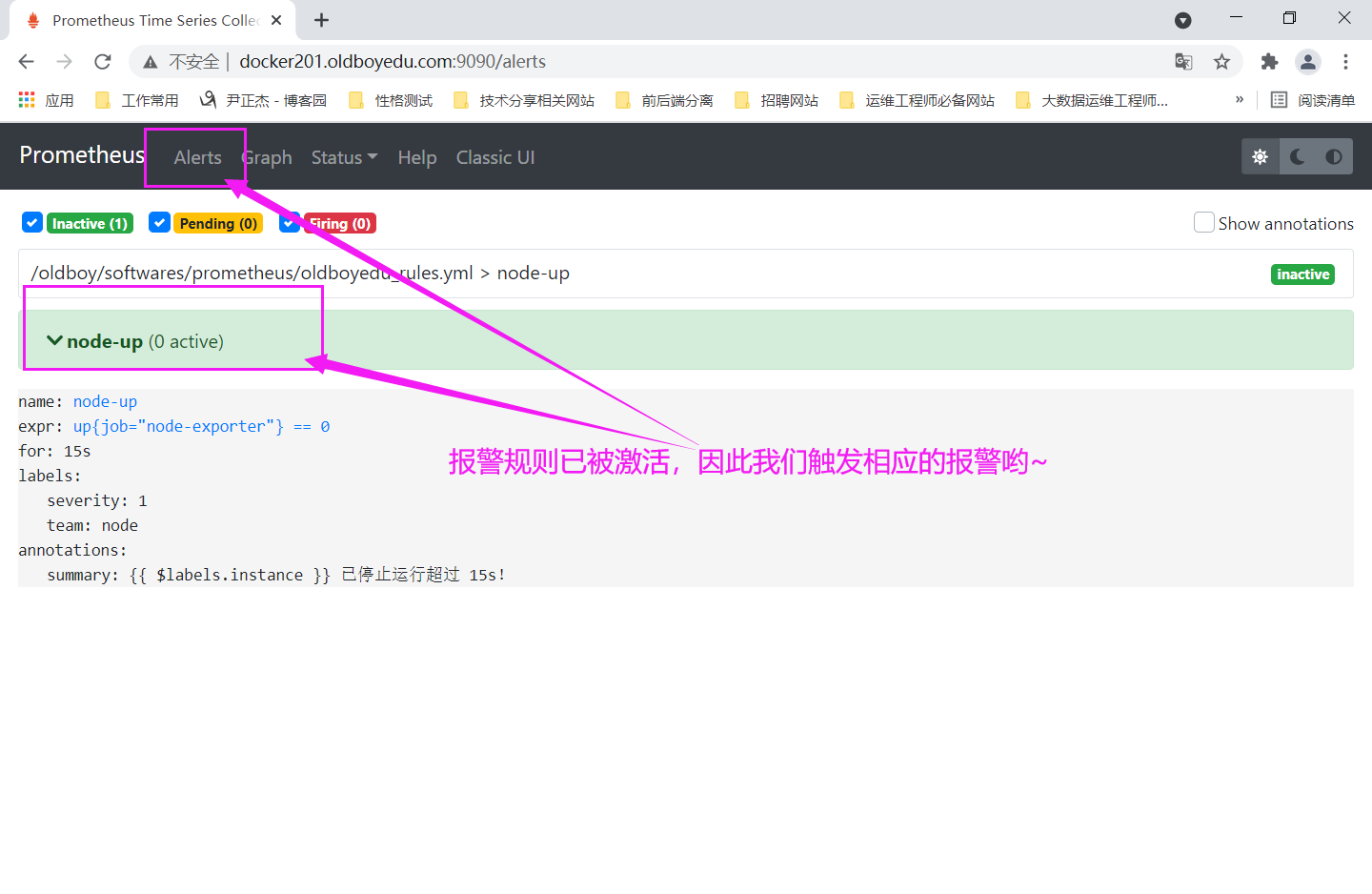
6.触发报警规则
[root@docker201.oldboyedu.com ~]# docker container stop node_exporter
温馨提示:
如下图所示,会成功出发报警哟~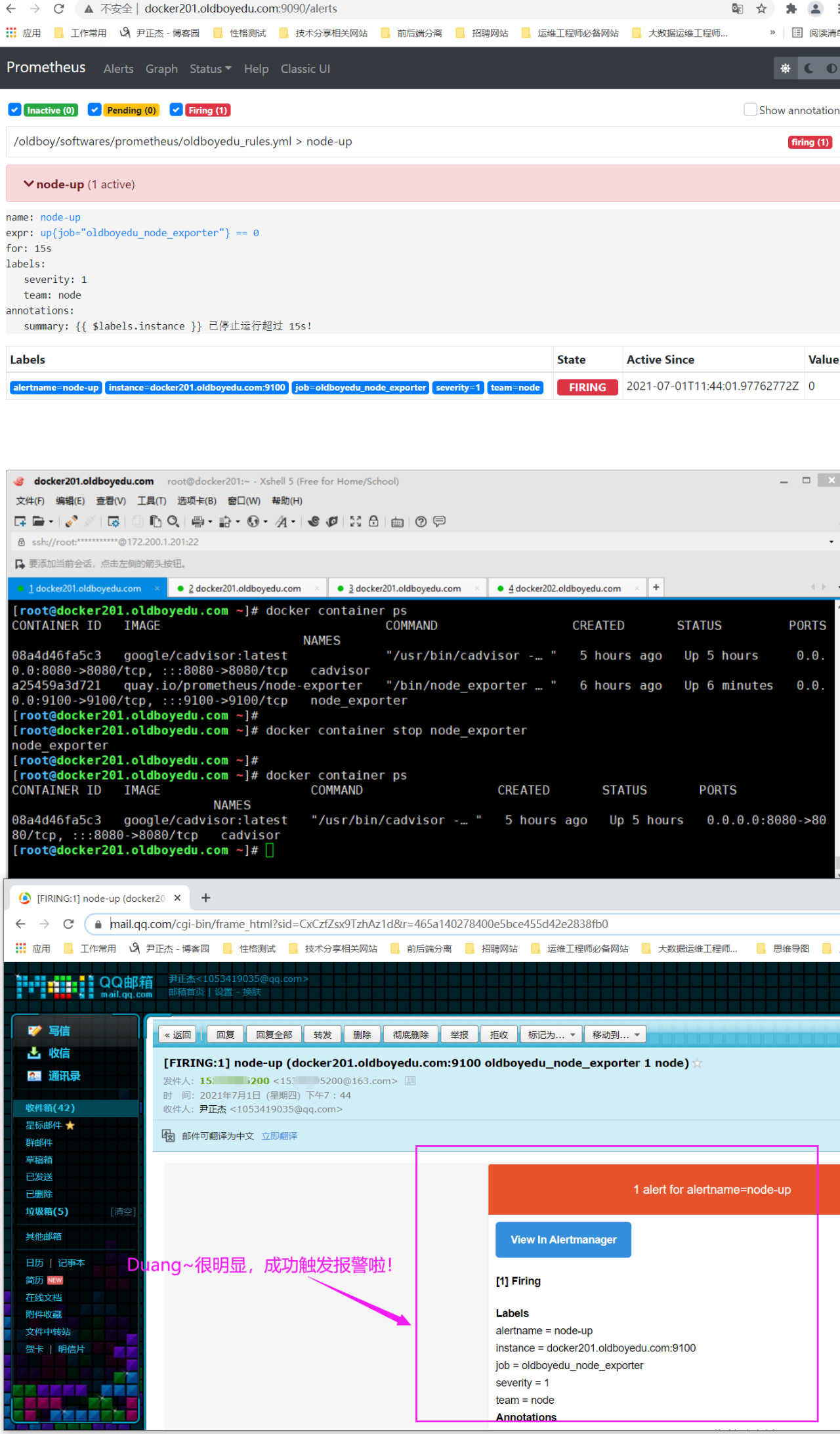
7.恢复报警
[root@docker201.oldboyedu.com ~]# docker container start node_exporter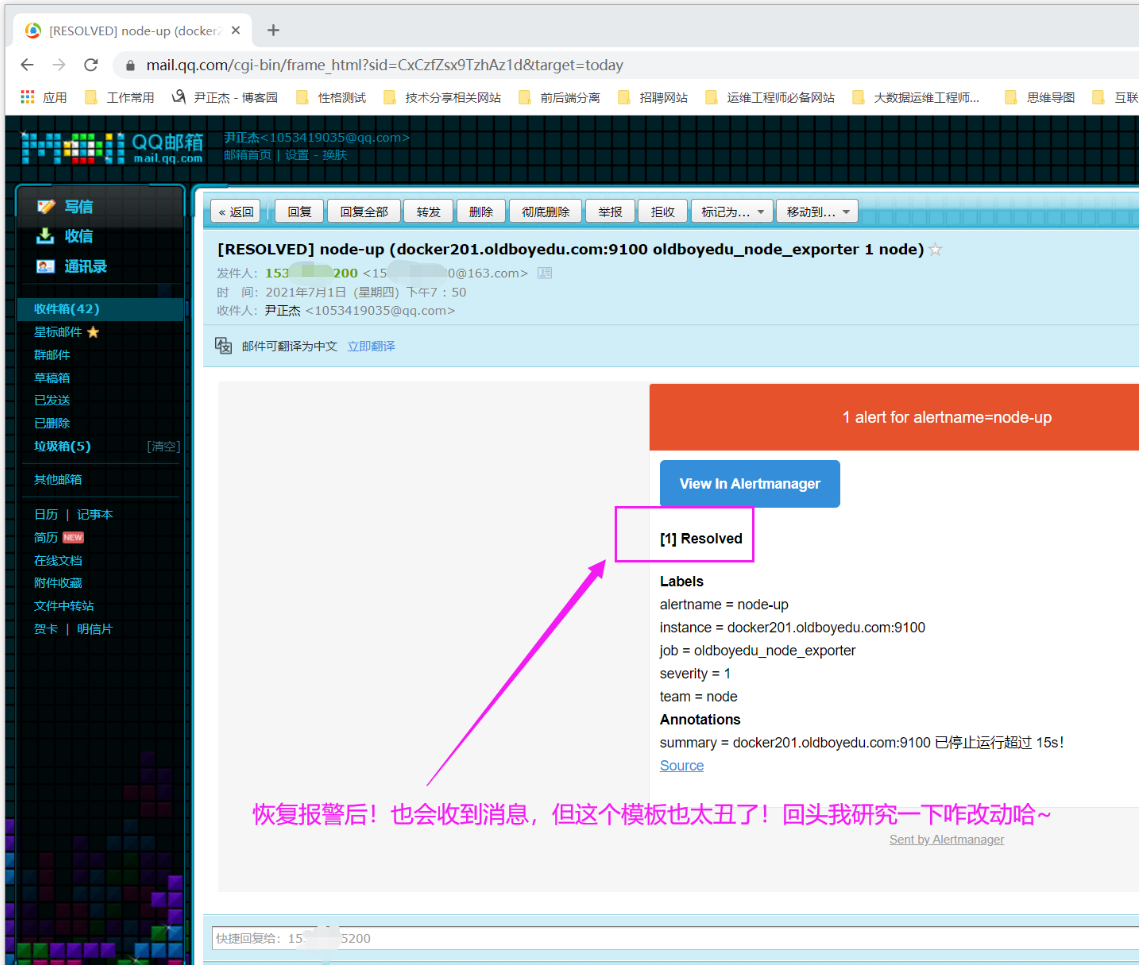
十八.可能会遇到的问题
1.oldboyedu_tcp_wait_connections: untyped
故障原因:
上传的数据类型不识别。
如下图所示,你可能会以为,自定义监控项类型不能是untype类型。那如果你真的这样想就错了。untype仅表示非内置的类型而已。
我之所以在Prometheus server的WebUI中查不到数据是因为数据上传的格式写错了。
解决方案:
我自习对比了我上传K-V数据的是的格式如下:
oldboyedu_tcp_wait_connections:2
实际的官方要求的格式K-V格式如下:
oldboyedu_tcp_wait_connections 2
综上所述,我们在上传数据是应该使用空格来区分K,V键值对哟。

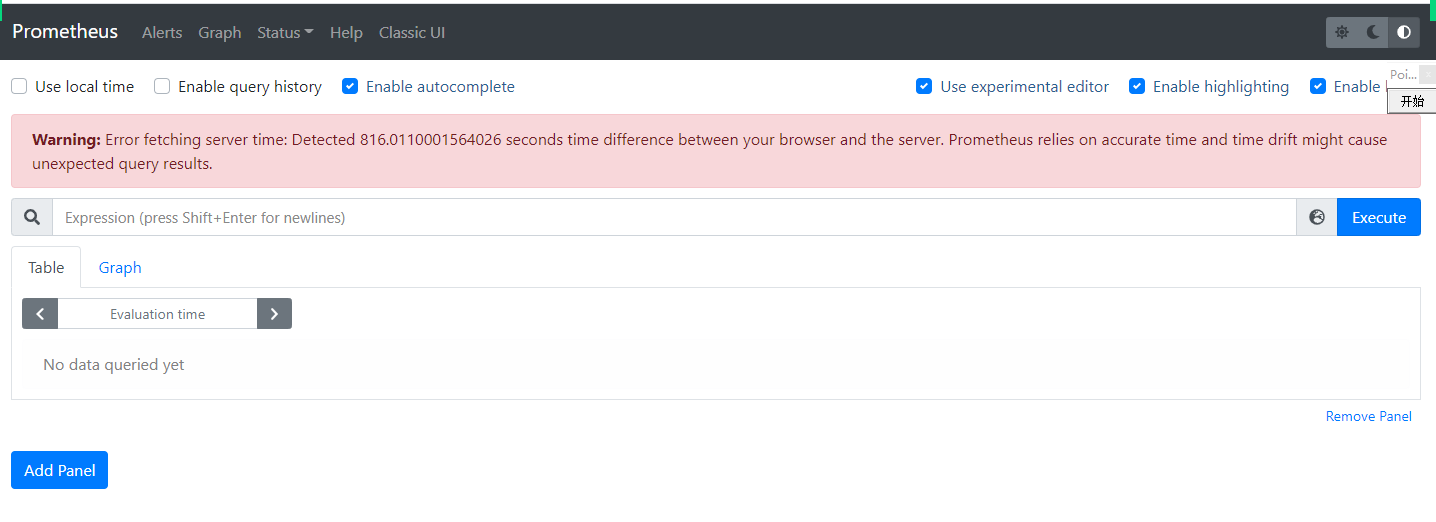
2.Warning: Error fetching server time: Detected 816.0110001564026 seconds time difference between your browser and the server. Prometheus relies on accurate time and time drift might cause unexpected query results.
报错原因:
prometheus server服务器在时间肯windows的时间不同步.
解决方案:
yum -y install ntpdate && ntpdate ntp1.aliyun.com