本文最后更新于 704 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
部署logstash
一.数据格式分类
1.开场白
在互联网当中,我们查询的信息主要包括文章,音乐,视频,图片,网站信息等等。
传统意义上我们会将要查询的数据分为三大类,即结构化数据,非结构化数据和半结构化数据。
2.结构化数据
含义:
所谓的结构化数据我们一般会用特定的结构来组织和管理数据。
表现形式:
它一般表现为二维的表结构。
例如存储学生信息,它包括学生姓名,年龄,身份证号,家庭住址,监护人手机号信息等。
存储产品:
我们可以将结构化数据保存在关系型数据库中,比如MySQL,Oracle等数据库中,并通过SQL语句来进行查询。为了提高查询效率,我们可以基于索引的方式来优化查询。
3.非结构化数据
含义:
所谓的非结构化数据其实就是我们无法用二维表结构来表现数据的数据。
表现形式:
它一般表现为服务器日志,通信记录,工作文档,报表,视频,图片,音乐等。
这样的数据它的特点是维度广,数据量大,所以数据的存储和查询成本是非常大的,往往需要专业的人员和大量的统计模型来进行处理。
存储产品:
我们一般会将非结构化的数据保存在非关系型数据库中,比如MongoDB,Redis,HBase,Kudu等。
这样的数据都是基于Key-Value的结构进行保存数据的,通过Key来查询数据相对来说比较快。
4.半结构化数据
含义:
所谓的半结构化数据就是将数据的结构和内容混在一起没有明显的区分。
表现形式:
它一般表现为XML,HTML,JSON等文档,
存储产品:
我们通常也会把半结构化数据保存在非关系数据库中,比如MongoDB,Redis,HBase,Kudu等。
它的缺点就是查询在查询其内容不是很容易。
5.结束语
生活中很多场景下,我们搜索的对象并非都是关系型结构化的信息,我们无法像数据库模糊查询那样进行模糊匹配,更不可能遍历所有的内容做匹配,毕竟查询的目的是为了快速找到你想要的信息。所以对如何查询结构化数据以及非结构化数据当中的内容并且准确的查询是非常重要的,而我们已经学习过的ES的软件就是为了解决这样的场景所产生的软件。
随着5G时代的到来,海量数据充斥着我们生活中的方方面面,实时数据的采集,分析,存储,检索就是计算机数据处理技术未来发展的方向,而我们要学习的ES软件在这些方面表现的是非常抢眼的。所以我们要持续观察下去,看看它未来能给我们带来哪些惊喜。
二.logstash概述
1.为什么需要logstash
对于部分生产上的日志无法像nginx那样,可以直接将输出的日志转换为JSON格式。
但是可以借助logstash来将我们的"非结构化数据"转换为结构化数据。
前面我们通过filebeat读取了nginx的日志,如果是你写的python项目,比如自动化运维平台之类的,如果是类似这种自定义结构的日志,就需要读取处理后才能使用。
综上所述,这个时候就需要使用logstash了,因为logstash有着强大的处理能力,可以应用各种各样的场景。
2.什么是logstash
logstash是开源的服务端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的"存储库"(我们的存储库当然是"Elasticsearch")中。
Logstash管道具有两个必需元素input和output,以及一个可选元素filter。输入插件使用来自源的数据,过滤器插件根据您的指定修改数据,输出插件将数据写入目标。
推荐阅读:
https://www.elastic.co/cn/logstash
https://www.elastic.co/guide/en/logstash/current/introduction.html
3.logstash架构介绍
logstash的基础架构类似于pipeline流水线,如下所示:
input:
数据采集(常用插件"stdin","file","kafka","beat","http")。
filter:
数据解析/转换(常用插件: grok,data,geoip,mutate,useragent)
数据从源传输到存储的过程中,logstash和filter过滤器能够解析各个事件,识别已命名的字段结构,并将它们转换成通用的格式,以便更轻松,更快速地分析和实现商业价值。
(1)利用grok插件可以从非结构化数据中派生出结构化数据;
(2)利用geoip从IP地址分析出地理坐标;
(3)利用useragent从请求中分析操作系统,设备类型等;
output:
数据输出(常用插件:ElasticSearch)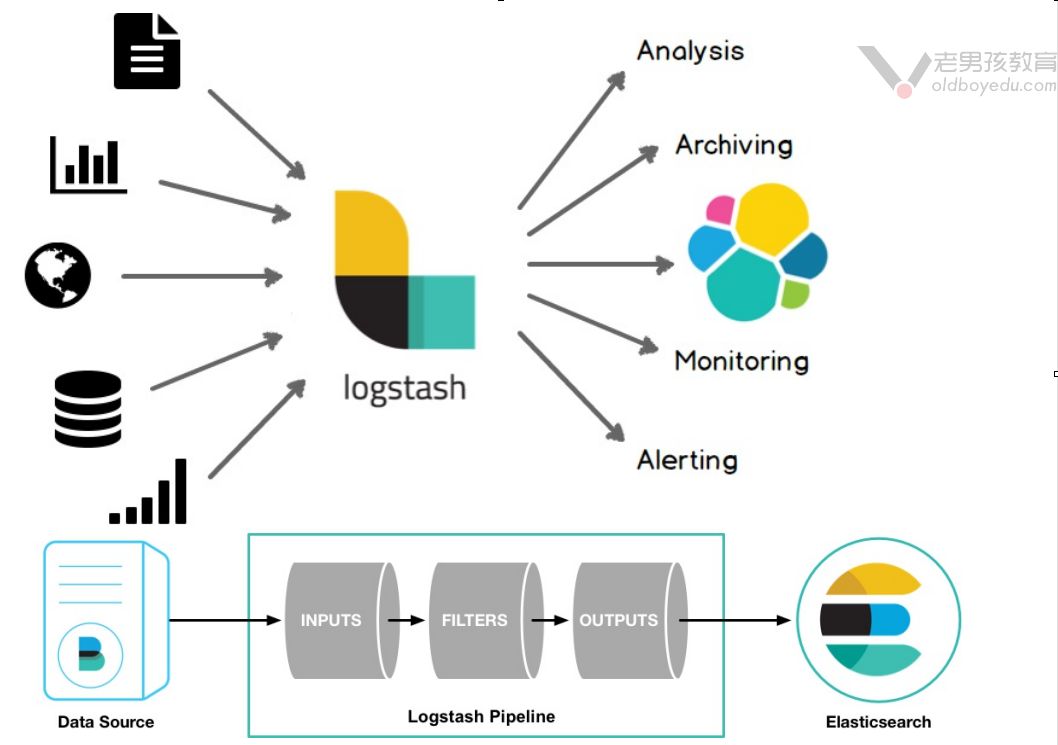
三.部署logstash
1.解压文件并创建符号链接
[root@elk101.oldboyedu.com ~]# tar zxf logstash-7.12.1-linux-x86_64.tar.gz -C /oldboy/softwares/
[root@elk101.oldboyedu.com ~]#
[root@elk101.oldboyedu.com ~]# cd /oldboy/softwares/
[root@elk101.oldboyedu.com /oldboy/softwares]#
[root@elk101.oldboyedu.com /oldboy/softwares]# ln -sv logstash-7.12.1 logstash
"logstash" -> "logstash-7.12.1"
[root@elk101.oldboyedu.com /oldboy/softwares]#
2.配置环境变量
[root@elk101.oldboyedu.com ~]# vim /etc/profile.d/logstash.sh
[root@elk101.oldboyedu.com ~]#
[root@elk101.oldboyedu.com ~]# cat /etc/profile.d/logstash.sh
#!/bin/bash
export LOGSTASH_HOME=/oldboy/softwares/logstash
export PATH=$PATH:$LOGSTASH_HOME/bin
[root@elk101.oldboyedu.com ~]#
[root@elk101.oldboyedu.com ~]# logstash -h # 验证环境变量是否配置成功。
3.logstash初体验
(1)使用官方默认的配置参数
logstash -e ""
(2)指定输出格式为JSON
logstash -e "input { stdin { } } output { stdout {codec => json} }"
温馨提示:
注意哈,我们运行的logstash并没有启用filter插件,因此输入端的数据是未经过处理直接传输给输出
端的。
四.logstash的配置文件结构说明
input { # 输入
stdin { ... } # 标准输入
}
filter { # 过滤,对数据进行切分,截取等处理
...
}
output { # 输出
stdout { ... } # 标准输出
}1.输入插件
采集各种样式,大小和来源的数据,数据往往以各种各样的形式,或分散或集中地存在于很多系统中。
logstash支持各种输入选择,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志,指标,Web应用,数据存储以及各种AWS服务采集数据。
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
2.过滤插件
过滤器会实时解析和转换数据,数据从源传输到存储库的过程中,logstash过滤器能够解析各种事件,识别已命名的字段以构建结构,并将它们转换或通过格式,以便更轻松,更快速地分析和实现商业价值。
过滤器可以将PII(Personal Identifiable Information,即个人可识别信息)数据匿名化,完全排除敏感字段。简化整体处理,不受数据源,格式或架构的影响。
我们可以利用包括但不限于以下组件来实现过滤:
GROK:
利用Grok组件从非结构化数据中派生出结构化数据。
GEO IP:
从IP地址中破译出地理坐标。
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
3.输出插件
选择您的存储库,导出您的数据,尽管Elasticsearch是我们首选的输出方向,能够为我们的索索和分析带来无限可能,但它并非唯一选择。
logstash提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
五.logstash的input组件案例
1.基于标准输入案例及常用的通用字段展示
(1)编写配置文件并测试语法
cat > oldboyedu_linux77/input/stdin/06-stdin-to-console.conf << EOF
input {
stdin {
add_field => {
"school" => "oldboyedu"
"class" => "linux77"
"address" => ["北京","上海","深圳"]
}
id => "oldboyedu_linux77"
codec => "json"
tags => [
{
"id" => 1
"name" => "oldboy"
},
{
"id" => 2
"name" => "linux"
},
{
"school" => "oldboyedu_linux"
}
]
type => "oldboyedu_linux77_stdin"
}
}
output {
stdout {
}
}
EOF
logstash -tf oldboyedu_linux77/input/stdin/06-stdin-to-console.conf
(2)启动logstash实例并交互式测试,可以测试多次哟~
logstash -f oldboyedu_linux77/input/stdin/06-stdin-to-console.conf
(3)当然,也可以非交互式测试,但只能测试一次!
echo "{\"linux_school\":\"老男孩教育\",\"linux_class\":\"linux77\"}" |logstash -f oldboyedu_linux77/input/stdin/06-stdin-to-console.conf
echo '{"linux_school":"老男孩教育","linux_class":"linux77"}' |logstash -f oldboyedu_linux77/input/stdin/06-stdin-to-console.conf
温馨提示:
(1)如果是交互式的案例,需要输入json格式,因为咱们使用了'codec => "json"',如果想要基于行的方式输入,则直接输入'codec => "line"'即可.
(2)本案例交互式测试的json为: {"linux_school":"老男孩教育","linux_class":"linux77"}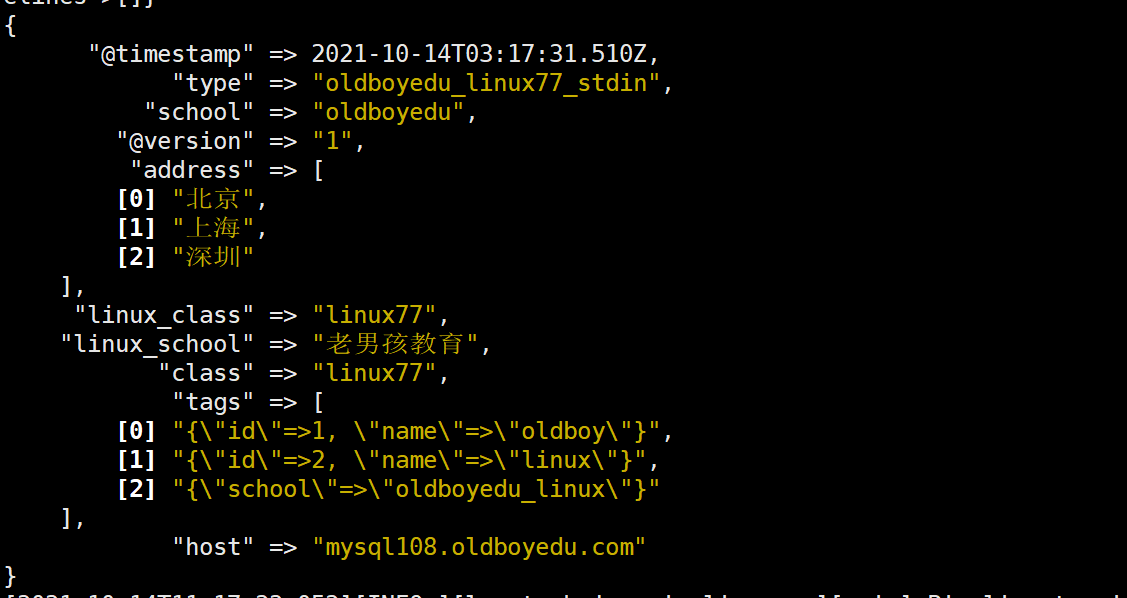
2.基于文件输入案例(忘记它吧,日志收集咱能用filebeat即可!)
cat > oldboyedu_linux77/input/file/04-file-to-console.conf <<EOF
input {
file {
path => [ "/oldboyedu/logs/linux77/*" ]
start_position => "beginning"
exclude => "*.log"
stat_interval => 10
}
}
output {
stdout {
}
}
EOF
logstash -f oldboyedu_linux77/input/file/04-file-to-console.conf3.基于beats输入案例
(1)logstash配置监听服务
cat > oldboyedu_linux77/input/beats/01-beats-to-console.conf <<EOF
input {
beats {
port => 15044
}
}
output {
stdout {
}
}
EOF
logstash -f oldboyedu_linux77/input/beats/01-beats-to-console.conf
(2)编写filebeat配置文件,将输出端写入到logstash
cat > conf/output/logstash/03-log-to-logstash.yml <<EOF
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/*.log
exclude_files: ['^error']
json.keys_under_root: true
fields:
school: "oldboyedu"
class: "linux77"
address: ["北京","上海","深圳"]
fields_under_root: true
output.logstash:
hosts: ["10.0.0.108:15044"]
EOF
./filebeat run -e -c conf/output/logstash/03-log-to-logstash.yml
温馨提示:
注意要先启动logstash的监听端口哟~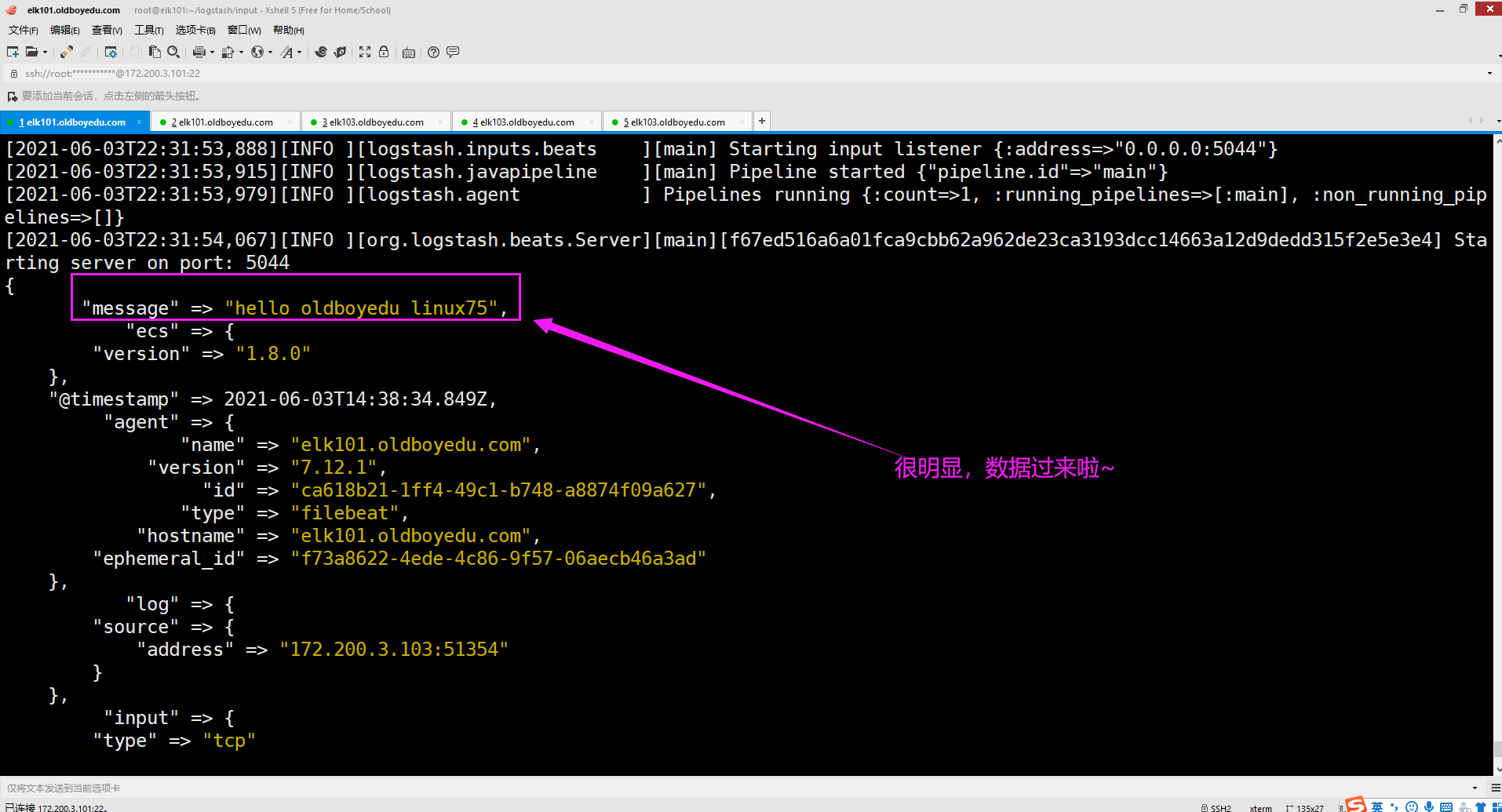
4.基于tcp案例
cat > oldboyedu_linux77/input/tcp/01-tcp-to-console.conf << EOF
input {tcp {port => 8000}}
output { stdout { }}
EOF
logstash -f oldboyedu_linux77/input/tcp/01-tcp-to-console.conf5.基于http案例
[root@elk101.oldboyedu.com ~/logstash/filter]# vim grok_demo.conf
[root@elk101.oldboyedu.com ~/logstash/filter]#
[root@elk101.oldboyedu.com ~/logstash/filter]# cat grok_demo.conf
input {
http {
port => 8888
}
}
output {
stdout {
codec => rubydebug
}
}
[root@elk101.oldboyedu.com ~/logstash/filter]#
[root@elk101.oldboyedu.com ~/logstash/filter]# logstash -f grok_demo.conf
发送测试数据:
172.200.1.19 - - [04/Jun/2021:10:28:29 +0800] "GET /favicon.ico HTTP/1.1" 404 555 "http://elk101.oldboyedu.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36" "-"
注意观察"messages"字段。
温馨提示:
监听的http是基于4层的TCP协议实现的7层协议哟,因此我们在访问的时候需要加上对应的http协议哟~访问效果如下图所示。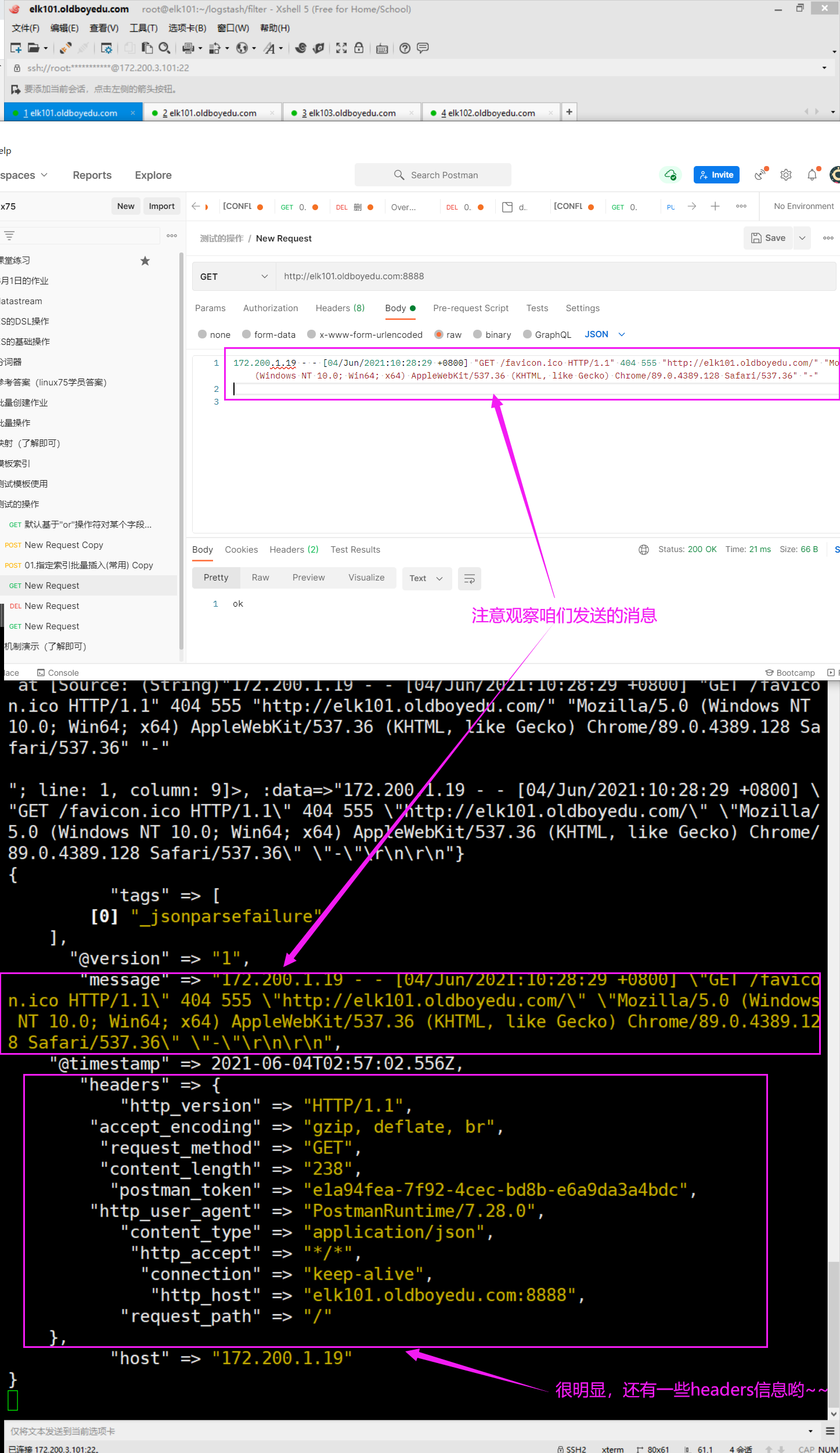
6.基于kafka的案例
(1)启动kafka集群
步骤略.
(2)编写配置文件并启动
cat > oldboyedu_linux77/input/kafka/02-kafka-to-console.conf << EOF
input {
kafka {
bootstrap_servers => "10.0.0.106:9092,10.0.0.107:9092,10.0.0.108:9092"
topics => ["oldboyedu_linux77_logstash"]
group_id => "oldboyedu_linux77_2021"
auto_offset_reset => "earliest"
}
}
output {
stdout {
codec => "rubydebug"
}
}
EOF
logstash -f oldboyedu_linux77/input/kafka/02-kafka-to-console.conf 五.logstash的output组件案例
1.基于stdout标准输出案例展示
cat > oldboyedu_linux77/output/stdout/01-http-to-console.conf << EOF
input {
http {
port => 9999
}
}
output {
stdout {
codec => rubydebug
# codec => json
}
}
EOF
logstash -f oldboyedu_linux77/output/stdout/01-http-to-console.conf
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-stdout.html2.基于file标准输出案例展示
cat > oldboyedu_linux77/output/file/01-http-to-file.conf << EOF
input {
http {
port => 9999
}
}
output {
file {
path => "/tmp/oldboyedu-linux77.log"
}
}
EOF
logstash -f oldboyedu_linux77/output/file/01-http-to-file.conf
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-file.html3.基于tcp标准输出案例展示
(1)使用nc启动监听端口
nc -l 10.0.0.106 7777
(2)编写配置文件
cat > oldboyedu_linux77/output/tcp/01-http-to-tcp.conf << EOF
input {
http {
port => 9999
}
}
output {
tcp {
host => "10.0.0.106"
port => 7777
}
}
EOF
logstash -f oldboyedu_linux77/output/tcp/01-http-to-tcp.conf
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-tcp.html4.基于redis标准输出案例展示
(1)启动redis实例
此步骤略.
(2)配置logstash文件并启动
cat > oldboyedu_linux77/output/redis/01-http-to-redis.conf << EOF
input {
http {
port => 9999
}
}
output {
redis {
host => ["10.0.0.108"]
port => 16379
db => 15
password => "oldboyedu_linux77"
key => "oldboyedu-linux77"
data_type => list
}
}
EOF
logstash -f oldboyedu_linux77/output/redis/01-http-to-redis.conf
(3)发送数据
cur -X POST http://10.0.0.108:9999
{
"linux_school": "老男孩教育",
"linux_class": "linux77",
"address": [
"北京",
"上海",
"深圳"
]
}
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-redis.html
5.基于kafka标准输出案例展示
(1)启动kafka集群
此步骤略.
(2)编写logstash的配置文件并启动
cat > oldboyedu_linux77/output/kafka/01-http-to-kafka.conf << EOF
input {
http {
port => 9999
}
}
output {
kafka {
codec => json
bootstrap_servers => "10.0.0.106:9092,10.0.0.107:9092,10.0.0.108:9092"
topic_id => "oldboyedu_linux77_logstash_2021"
}
}
EOF
logstash -f oldboyedu_linux77/output/kafka/01-http-to-kafka.conf
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-kafka.htm
6.基于ES标准输出案例展示
(1)编写logstash配置并启动
cat > oldboyedu_linux77/output/es/02-many-to-es.conf <<EOF
input {
beats {
type => "log"
port => 9991
}
tcp {
type => "tcp"
port => 9992
}
http {
type => "http"
port => 9993
}
}
output {
if [type] == "tcp" {
elasticsearch {
hosts => ["10.0.0.106:9200","10.0.0.107:9200","10.0.0.108:9200"]
index => "oldboyedu-linux77-tcp"
}
} else if [type] == "log" {
elasticsearch {
hosts => ["10.0.0.106:9200","10.0.0.107:9200","10.0.0.108:9200"]
index => "oldboyedu-linux77-log"
}
}else {
elasticsearch {
hosts => ["10.0.0.106:9200","10.0.0.107:9200","10.0.0.108:9200"]
index => "oldboyedu-linux77-other"
}
}
}
EOF
logstash -rf oldboyedu_linux77/output/es/02-many-to-es.conf
推荐阅读:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html