本文最后更新于 713 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
Theano 实例:线性回归
基本模型
在用 theano 进行线性回归之前,先回顾一下 theano 的运行模式。
theano 是一个符号计算的数学库,一个基本的 theano 结构大致如下:
- 定义符号变量
- 编译用符号变量定义的函数,使它能够用这些符号进行数值计算。
- 将函数应用到数据上去
%matplotlib inline
from matplotlib import pyplot as plt
import numpy as np
import theano
from theano import tensor as TUsing gpu device 0: GeForce GTX 850M简单的例子:$y = a \times b, a, b \in \mathbb{R}$
定义 $a, b, y$:
a = T.scalar()
b = T.scalar()
y = a * b编译函数:
multiply = theano.function(inputs=[a, b], outputs=y)将函数运用到数据上:
print multiply(3, 2) # 6
print multiply(4, 5) # 206.0
20.0线性回归
回到线性回归的模型,假设我们有这样的一组数据:
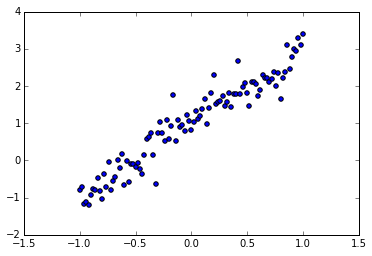
train_X = np.linspace(-1, 1, 101)
train_Y = 2 * train_X + 1 + np.random.randn(train_X.size) * 0.33分布如图:
plt.scatter(train_X, train_Y)
plt.show()
定义符号变量
我们使用线性回归的模型对其进行模拟:
$$\bar{y} = wx + b$$
首先我们定义 $x, y$:
X = T.scalar()
Y = T.scalar()可以在定义时候直接给变量命名,也可以之后修改变量的名字:
X.name = 'x'
Y.name = 'y'我们的模型为:
def model(X, w, b):
return X * w + b在这里我们希望模型得到 $\bar{y}$ 与真实的 $y$ 越接近越好,常用的平方损失函数如下:
$$C = |\bar{y}-y|^2$$
有了损失函数,我们就可以使用梯度下降法来迭代参数 $w, b$ 的值,为此,我们将 $w$ 和 $b$ 设成共享变量:
w = theano.shared(np.asarray(0., dtype=theano.config.floatX))
w.name = 'w'
b = theano.shared(np.asarray(0., dtype=theano.config.floatX))
b.name = 'b'定义 $\bar y$:
Y_bar = model(X, w, b)
theano.pp(Y_bar)'((x * HostFromGpu(w)) + HostFromGpu(b))'损失函数及其梯度:
cost = T.mean(T.sqr(Y_bar - Y))
grads = T.grad(cost=cost, wrt=[w, b])定义梯度下降规则:
lr = 0.01
updates = [[w, w - grads[0] * lr],
[b, b - grads[1] * lr]]编译训练模型
每运行一次,参数 $w, b$ 的值就更新一次:
train_model = theano.function(inputs=[X,Y],
outputs=cost,
updates=updates,
allow_input_downcast=True)将训练函数应用到数据上
训练模型,迭代 100 次:
for i in xrange(100):
for x, y in zip(train_X, train_Y):
train_model(x, y)显示结果:
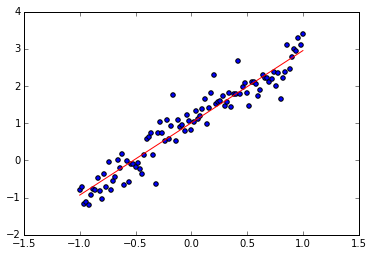
print w.get_value() # 接近 2
print b.get_value() # 接近 1
plt.scatter(train_X, train_Y)
plt.plot(train_X, w.get_value() * train_X + b.get_value(), 'r')
plt.show()1.94257426262
1.00938093662