本文最后更新于 702 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
使用Redis充当消息队列
一.生产者和消费者模型
1.传统的生产者和消费者解决方案存在的弊端
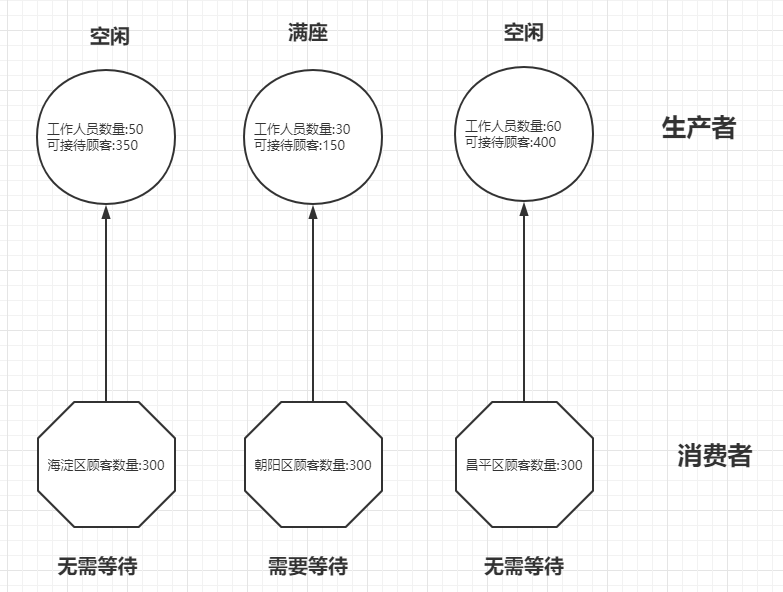
如下图所示,是传统的生产者和消费者解决方案,很明显的存在弊端。
对于生产者而言,有的生产者很繁忙,有的生产者却很闲。
对于消费者而言,有的消费者"吃"的很饱,而有的消费者却得"饿"着。
以上场景对于服务器资源而言,就是资源利用率不均衡,因此有关消息队列相关的中间件孕育而生。
2.使用中间件改进生产者消费者模型
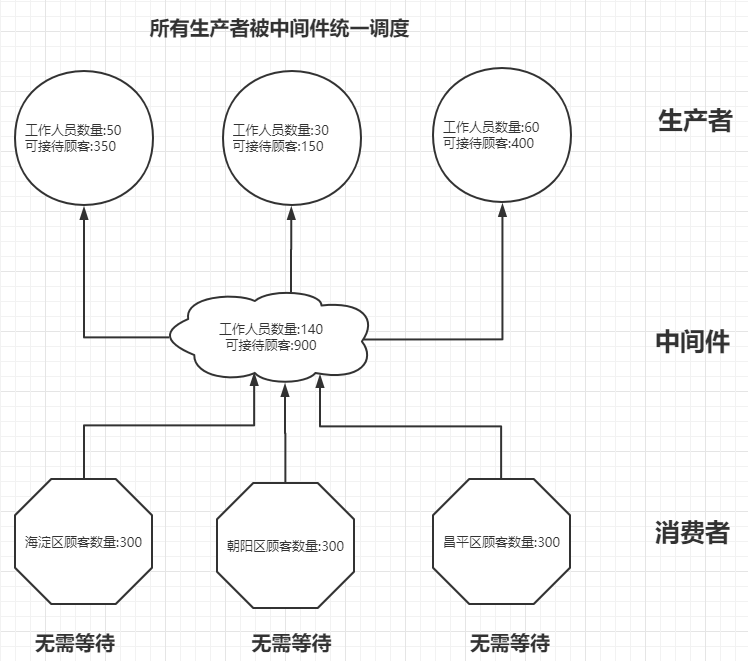
如下图所示,我们可以借助中间件来改进生产者和消费者的关系模型,解决了上述的弊端。
对于生产者而言,由于中间件软件层实现对生产者服务器的资源整合,从而提升了集群的利用率。
对于消费者而言,由于中间件软件层实现对消费者提供数据,从而保证某一个消费者都能拿到数据,并不会像之前那样有的消费者"吃"的很饱,而有的消费者却得"饿"着。
二.Redis支持的的消息模式
Java消息服务(Java Message Service,简称"JMS")应用程序接口是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
JMS规范目前支持两种消息模型:点对点(point to point, queue)和发布/订阅(publish/subscribe,topic)。 这两种模式主要区别或解决的问题就是发送到队列的消息能否重复消费(多订阅)。
Redis支持完全支持JMS的两种消息模式。
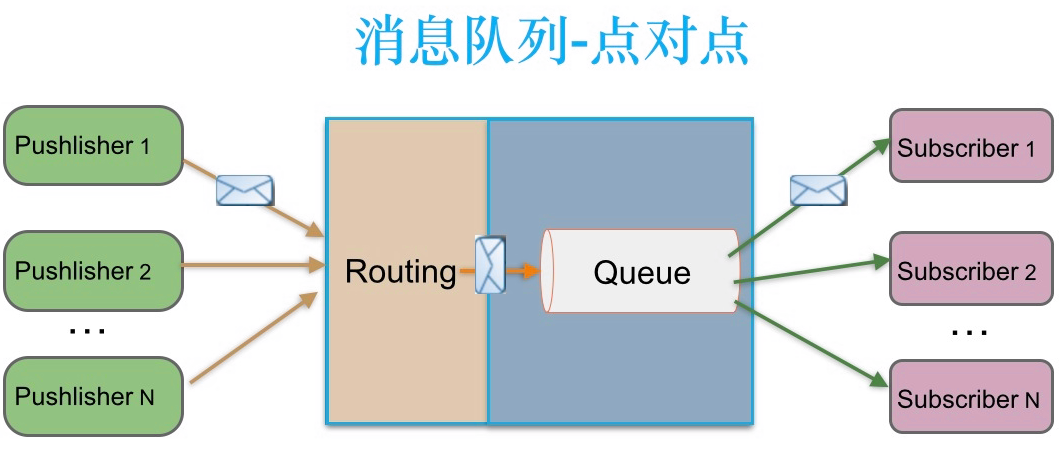
1.点对点模型
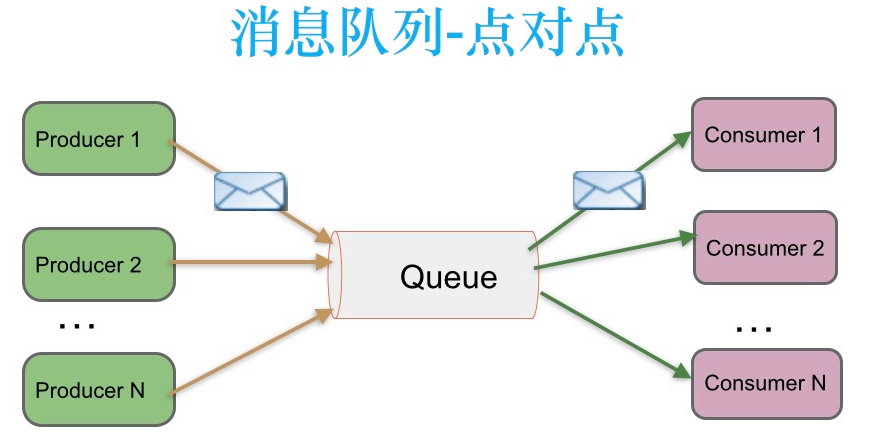
点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
温馨提示:
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
如下图所示,生产者发送一条消息到queue,只有一个消费者能收到。
2.发布/订阅模型
发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。
温馨提示:
和点对点方式不同,发布到topic的消息会被所有订阅者消费。
如下图所示,发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息。
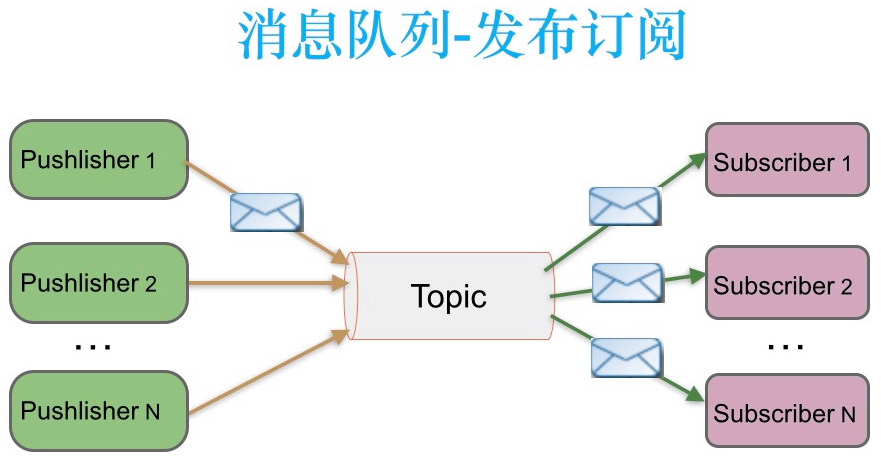
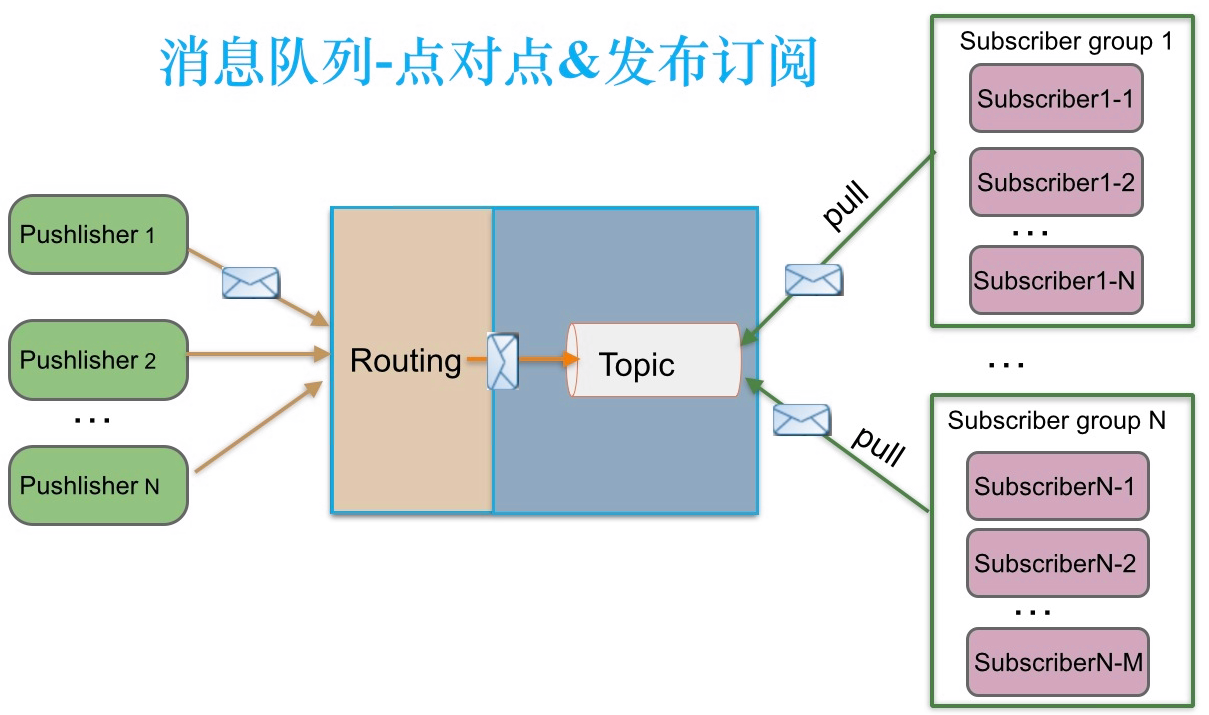
3.发布订阅模式下,实现订阅者负载均衡消费
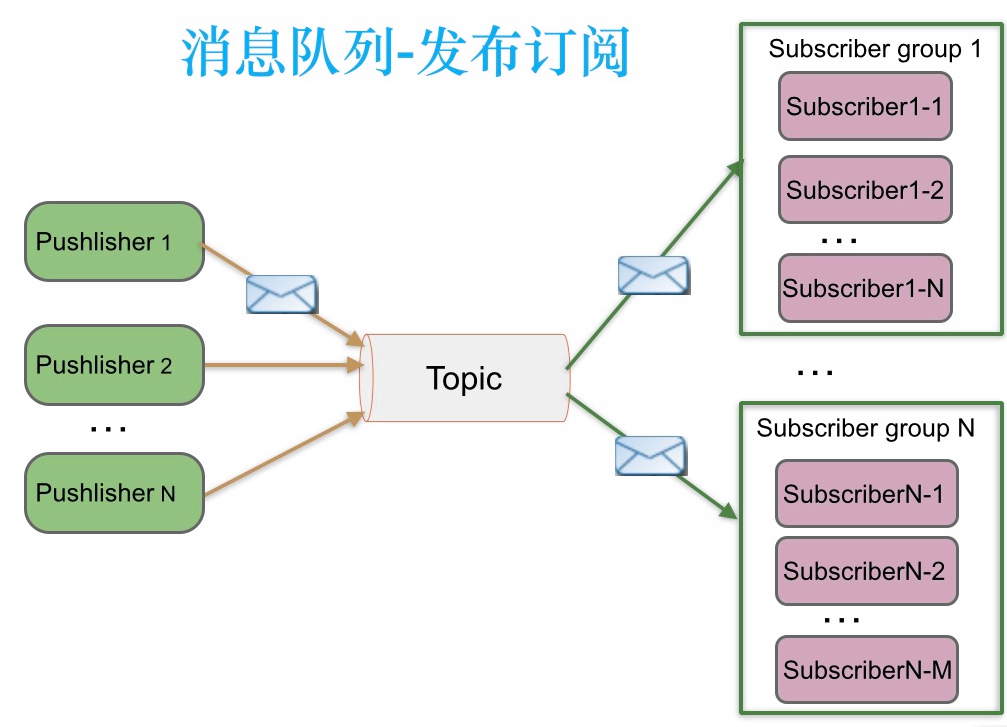
发布订阅模式下,能否实现订阅者负载均衡消费呢?当发布者消息量很大时,显然单个订阅者的处理能力是不足的。
如下图所示,实际上现实场景中是多个订阅者节点组成一个订阅组负载均衡消费topic消息即分组订阅, 这样订阅者很容易实现消费能力线性扩展。
三.流行消息队列的消息模型比较
传统企业型消息队列ActiveMQ遵循了JMS规范,实现了点对点和发布订阅模型,但其他流行的消息队列RabbitMQ、Kafka并没有遵循老态龙钟的JMS规范,是通过什么方式实现消费负载均衡、多订阅呢?
推荐阅读:
https://blog.csdn.net/lizhitao/article/details/47723105
1.RabbitMQ
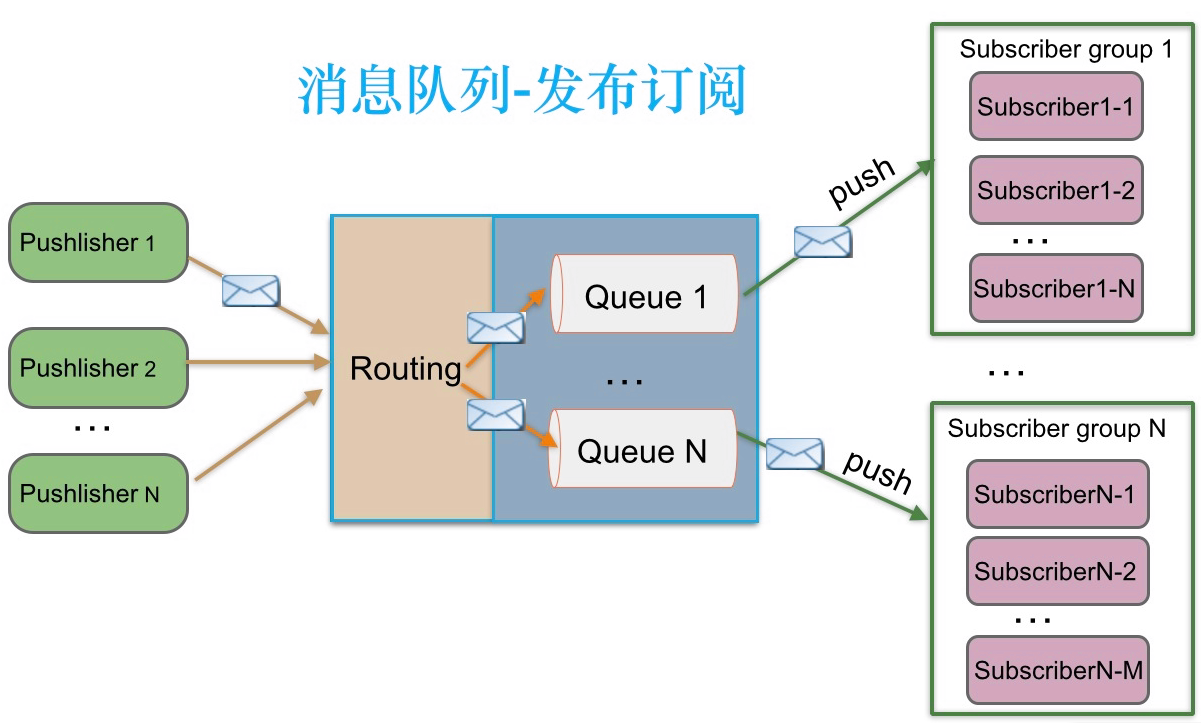
RabbitMQ实现了AQMP协议,AQMP协议定义了消息路由规则和方式。生产端通过路由规则发送消息到不同queue,消费端根据queue名称消费消息。此外RabbitMQ是向消费端推送消息,订阅关系和消费状态保存在服务端。
当RabbitMQ需要支持多订阅时,发布者发送的消息通过路由同时写到多个Queue,不同订阅组消费此消息。
RabbitMQ既支持内存队列也支持持久化队列,消费端为推模型,消费状态和订阅关系由服务端负责维护,消息消费完后立即删除,不保留历史消息。所以支持多订阅时,消息会多个拷贝。
2.Kafka
Kafka只支持消息持久化,消费端为拉模型,消费状态(基于"OFFSET")和订阅关系由客户端端负责维护,消息消费完后不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
同一个订阅组会消费topic所有消息,每条消息只会被同一个订阅组的一个消费节点消费,同一个订阅组内不同消费节点会消费不同消息
四.Redis消息模式实战案例
1.模拟点对点的数据读写
(1)写数据
[root@redis201.oldboyedu.com ~]# redis-cli -a oldboyedu2021 -n 13 --raw
127.0.0.1:6379[13]> KEYS *
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> LPUSH bigdata hadoop hive storm
3
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> LRANGE bigdata 0 -1
storm
hive
hadoop
127.0.0.1:6379[13]>
(2)取数据
[root@redis201.oldboyedu.com ~]# redis-cli -a oldboyedu2021 -n 13 --raw
127.0.0.1:6379[13]> KEYS *
bigdata
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> RPOP bigdata
hadoop
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> RPOP bigdata
hive
127.0.0.1:6379[13]>
(3)再次写入数据
[root@redis201.oldboyedu.com ~]# redis-cli -a oldboyedu2021 -n 13 --raw
127.0.0.1:6379[13]> KEYS *
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> LRANGE bigdata 0 -1
storm
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> LPUSH bigdata flink clickhouse
3
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> LRANGE bigdata 0 -1
clickhouse
flink
storm
127.0.0.1:6379[13]>
2.发布订阅模拟
发布订阅相关的指令:
PUBLISH channel msg
将信息 message 发送到指定的频道 channel
SUBSCRIBE channel [channel ...]
订阅频道,可以同时订阅多个频道
UNSUBSCRIBE [channel ...]
取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
PSUBSCRIBE pattern [pattern ...]
订阅一个或多个符合给定模式的频道,每个模式以"*"作为匹配符。
比如"it*"匹配所有以"it"开头的频道(it.news、it.blog 、it.tweets等等),"news.*"匹配所有以"news."开头的频道(news.it、news.global.today等等),诸如此类。
PUNSUBSCRIBE [pattern [pattern ...]]
退订指定的规则, 如果没有参数则会退订所有规则
PUBSUB subcommand [argument [argument ...]]
查看订阅与发布系统状态
(1)在两个终端提前开启消息订阅:
[root@redis201.oldboyedu.com ~]# redis-cli -a oldboyedu2021 -n 13 --raw
127.0.0.1:6379[13]> SUBSCRIBE fm1024 # 注意哈,我们可以使用"PSUBSCRIBE fm*"指令来模糊匹配要订阅的数据哟~
subscribe
fm1024
1
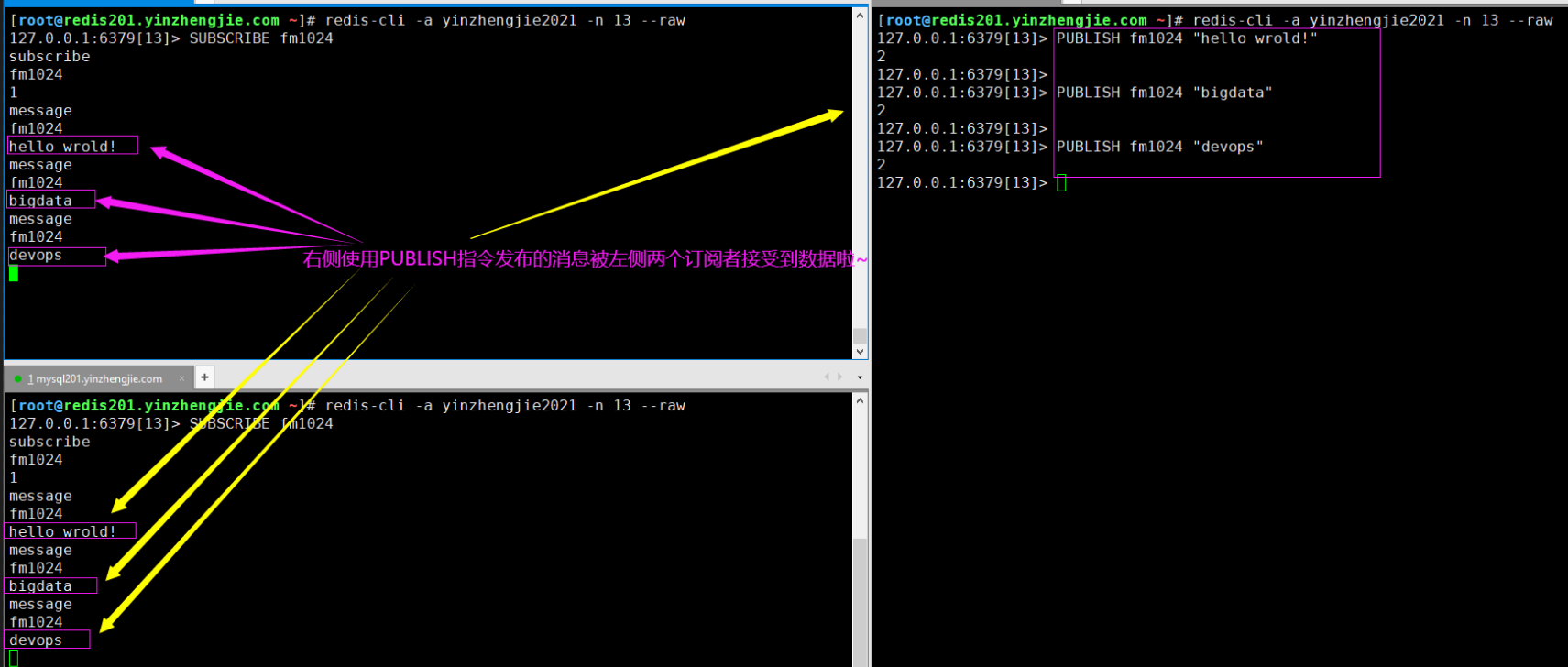
(2)在另一个终端发布消息,观察上面订阅的两个终端是否有内容输出:
[root@redis201.oldboyedu.com ~]# redis-cli -a oldboyedu2021 -n 13 --raw
127.0.0.1:6379[13]> PUBLISH fm1024 "hello wrold!"
2
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> PUBLISH fm1024 "bigdata"
2
127.0.0.1:6379[13]>
127.0.0.1:6379[13]> PUBLISH fm1024 "devops"
2
127.0.0.1:6379[13]>
如下图所示,Redis实现的消息的发布和订阅相对来说是比较简单的,其实大多数情况下是在搭建Redis的哨兵模式其内置的通信策略。
综上所述,Redis的消息发布订阅模式实现的比较捡漏,存在以下缺点:
(1)需要消费者提前订阅(SUBSCRIBE)消息,消费者不能拿到历史数据;
(2)使用"PUBLISH"指令发送数据并不会存储,如果没有订阅者则直接丢弃本次数据,该指令会记录返回有多少个SUBSCRIBE成功介绍到数据;
温馨提示:
(1)使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线。
(2)综上所述,如果要是用消息队列的订阅发布模式,我还是推荐大家使用RabbitMQ或者Kafka。尤其是大数据场景下,Kafka已经成为消息队列的事实标准。