本文最后更新于 705 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
kubernetes集群的高可用实战案例
一.etcd高可用集群
1.环境准备
请将虚拟机还原到最初的状态,可以提前拍个快照哈。否则挨个卸载之前的服务可能会存在写在不干净的情况。
角色环境准备如下:
k8s101.oldboyedu.com:
master
k8s102.oldboyedu.com:
etcd,node
k8s103.oldboyedu.com:
etcd,node
k8s104.oldboyedu.com:
etcd,node
k8s105.oldboyedu.com:
master
温馨提示:
我们可以手动将之前的环境移除,比如删除etcd的数据(rm -rf /var/lib/etcd/),移除master和node节点相关软件包(包括网络插件)等。当然,如果你不想搞这么麻烦,很简单,只需要恢复快照到干净的集群环境即可。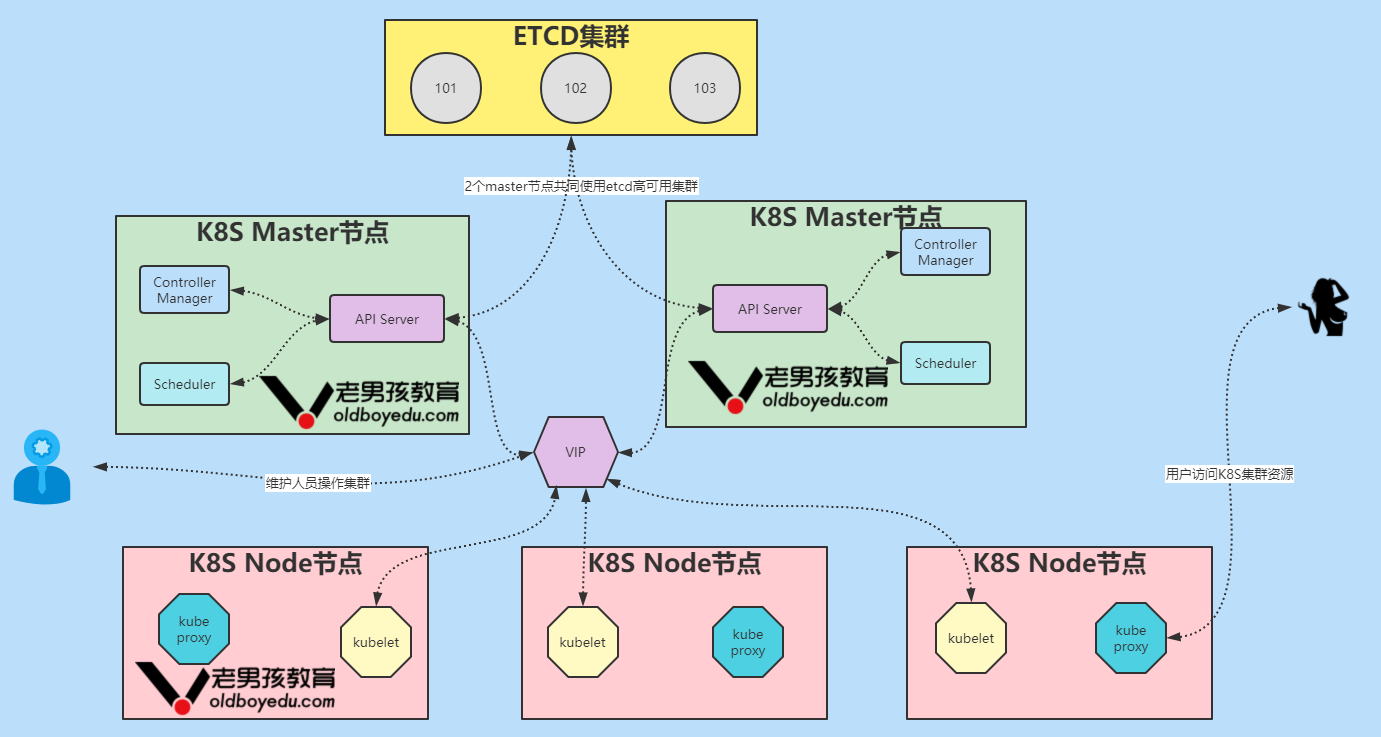
2.所有节点部署etcd服务
yum -y install etcd
温馨提示:
是集群的所有节点都部署etcd软件,以便于实现集群的高可用。3."k8s102.oldboyedu.com"节点修改etcd的配置文件
egrep -v "^#" /etc/etcd/etcd.conf
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="k8s102.oldboyedu.com"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.102:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.102:2379"
ETCD_INITIAL_CLUSTER="k8s102.oldboyedu.com=http://10.0.0.102:2380,k8s103.oldboyedu.com=http://10.0.0.103:2380,k8s104.oldboyedu.com=http://10.0.0.104:2380"
ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
相关参数说明如下:
ETCD_DATA_DIR:
指定ETCD数据库的数据存储目录。
ETCD_LISTEN_PEER_URLS:
和集群其它member之间通信的地址,用于监听其他etcd member的url,强烈建议配置IP地址。
ETCD_LISTEN_CLIENT_URLS:
对外提供服务的地址。
ETCD_NAME:
指定当前的member名称,该名称要求集群唯一。
ETCD_INITIAL_ADVERTISE_PEER_URLS:
该节点成员对等URL地址,且会通告群集的其余成员节点。
ETCD_ADVERTISE_CLIENT_URLS:
此member的客户端URL列表,用于通告群集的其余部分。这些URL可以包含域名。
ETCD_INITIAL_CLUSTER:
指定初始化集群时集群中所有节点的信息。后期我们可以在命令行添加相关的member节点哟。
ETCD_INITIAL_CLUSTER_TOKEN:
创建集群的 token,这个值每个集群保持唯一。
此配置可使重新创建集群,即使配置和之前一样,也会再次生成新的集群和节点uuid;
否则会导致多个集群之间的冲突,造成未知的错误。
ETCD_INITIAL_CLUSTER_STATE:
指定集群的初始状态,在第一次部署etcd集群时通常我们都会设置为"new"。
如果将此选项设置为"existing",则etcd将尝试加入现有群集。4.etcd集群其它节点修改配置
(1)k8s103.oldboyedu.com配置如下所示:
egrep -v "^#" /etc/etcd/etcd.conf
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="k8s103.oldboyedu.com"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.103:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.103:2379"
ETCD_INITIAL_CLUSTER="k8s102.oldboyedu.com=http://10.0.0.102:2380,k8s103.oldboyedu.com=http://10.0.0.103:2380,k8s104.oldboyedu.com=http://10.0.0.104:2380"
ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
(2)k8s104.oldboyedu.com配置如下所示:
egrep -v "^#" /etc/etcd/etcd.conf
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="k8s104.oldboyedu.com"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.104:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.104:2379"
ETCD_INITIAL_CLUSTER="k8s102.oldboyedu.com=http://10.0.0.102:2380,k8s103.oldboyedu.com=http://10.0.0.103:2380,k8s104.oldboyedu.com=http://10.0.0.104:2380"
ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
5.验证集群是否配置成功
如下图所示,只需只需以下的相关命令就可以检测集群是否正常,也可以查看集群谁是leader节点哟~
etcdctl cluster-health
etcdctl member list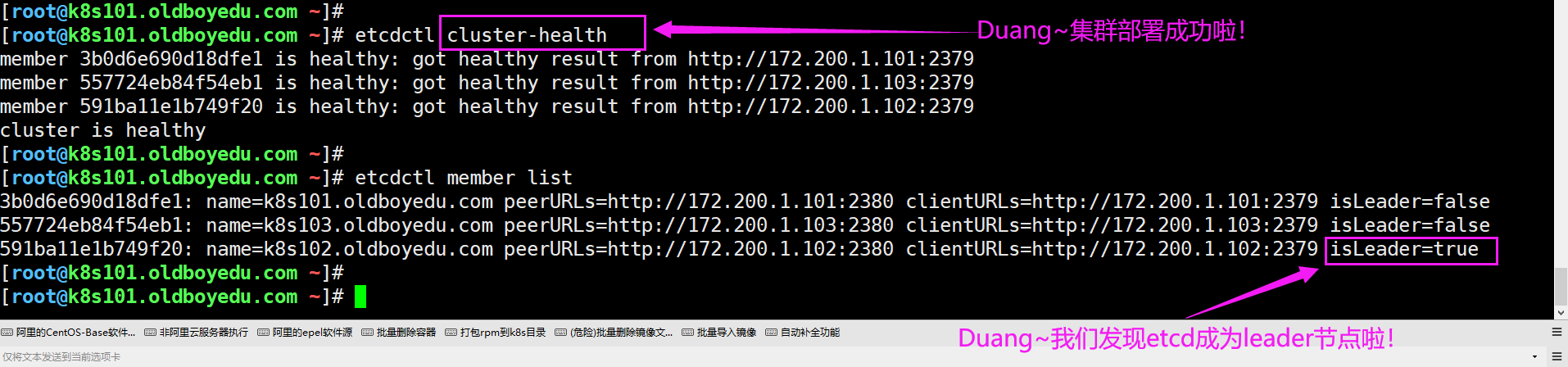
6.etcd故障处理
(1)任意选择一个节点手动制作故障,只需执行下面3条命令,则会导致服务无法正常启动
systemctl stop etcd.service
>/var/lib/etcd/default.etcd/member/wal/0000000000000000-0000000000000000.wal
systemctl start etcd.service
(2)尝试删除故障节点的数据进行恢复失败,只需执行下面2条命令
rm -rf /var/lib/etcd/default.etcd/*
systemctl start etcd.service
(3)将故障节点的member移除(该步骤前后请搭配"etcdctl member list"使用)
etcdctl member remove 3b0d6e690d18dfe1
(4)重新添加故障节点的member(该步骤前后请搭配"etcdctl member list"使用)
etcdctl member add k8s101.oldboyedu.com http://10.0.0.104:2380
(5)重新修改etcd的配置文件,只需修改一处并重启服务即可
[root@k8s101.oldboyedu.com ~]# grep ^ETCD_INITIAL_CLUSTER_STATE /etc/etcd/etcd.conf
ETCD_INITIAL_CLUSTER_STATE="existing"
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# systemctl start etcd
(6)观察集群状态
如下图所示,我们可以通过"etcdctl member list"查看集群的状态信息哟。
温馨提示:
上述出现问题时,可以在集群其它节点执行"etcdctl cluster-health"观察相关的输出信息。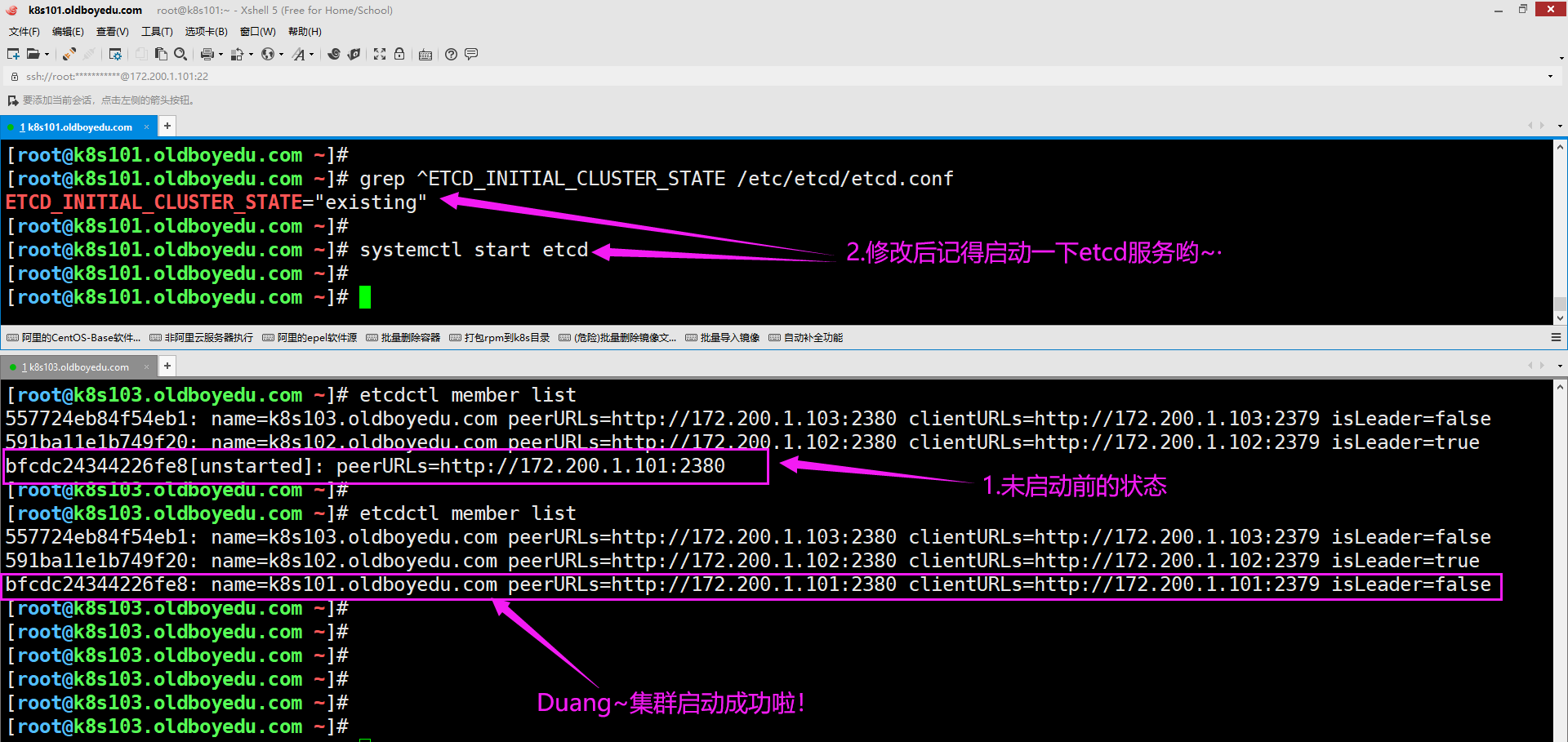
二.部署master节点的高可用
1.部署master节点
(1)开启缓存rpm包
[root@k8s101.oldboyedu.com ~]# sed -ri 's#(keepcache=)0#\11#' /etc/yum.conf
(2)安装k8s的master相关组件
[root@k8s101.oldboyedu.com ~]# yum -y install kubernetes-master
(3)打包软件包便于另一个节点部署
mkdir k8s-master
find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t k8s-master/
tar zcf oldboyedu-k8s-master.tar.gz k8s-master/
scp oldboyedu-k8s-master.tar.gz k8s102.oldboyedu.com:~
温馨提示,另一个节点部署操作步骤如下所示:
[root@k8s102.oldboyedu.com ~]# tar xf oldboyedu-k8s-master.tar.gz
[root@k8s102.oldboyedu.com ~]# cd k8s-master/
[root@k8s102.oldboyedu.com ~/k8s-master]# yum -y localinstall *.rpm2.修改master的配置文件
(1)修改apiserver的地址(值得注意的是,相比第一次安装主要是注意etcd集群的指定哟~)
[root@k8s101.oldboyedu.com ~]# vim /etc/kubernetes/apiserver
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# egrep -v "^#|^$" /etc/kubernetes/apiserver
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
KUBE_ETCD_SERVERS="--etcd-servers=http://k8s101.oldboyedu.com:2379,http://k8s102.oldboyedu.com:2379,http://k8s103.oldboyedu.com:2379"
...
[root@k8s101.oldboyedu.com ~]#
(2)无需修改config文件,因为默认的controller-manager, scheduler, 和proxy组件均为本地回环地址哟~
[root@k8s101.oldboyedu.com ~]# egrep -v "^#|^$" /etc/kubernetes/config
...
KUBE_MASTER="--master=http://127.0.0.1:8080"
[root@k8s101.oldboyedu.com ~]#
(3)将master节点的配置直接拷贝到另外一个节点即可
[root@k8s101.oldboyedu.com ~]# cd /etc/kubernetes/
[root@k8s101.oldboyedu.com /etc/kubernetes]#
[root@k8s101.oldboyedu.com /etc/kubernetes]# scp apiserver k8s102.oldboyedu.com:`pwd`
(4)所有master节点都需要重启相关服务
systemctl restart kube-controller-manager.service kube-scheduler.service kube-apiserver.service && systemctl enable kube-controller-manager.service kube-scheduler.service kube-apiserver.service
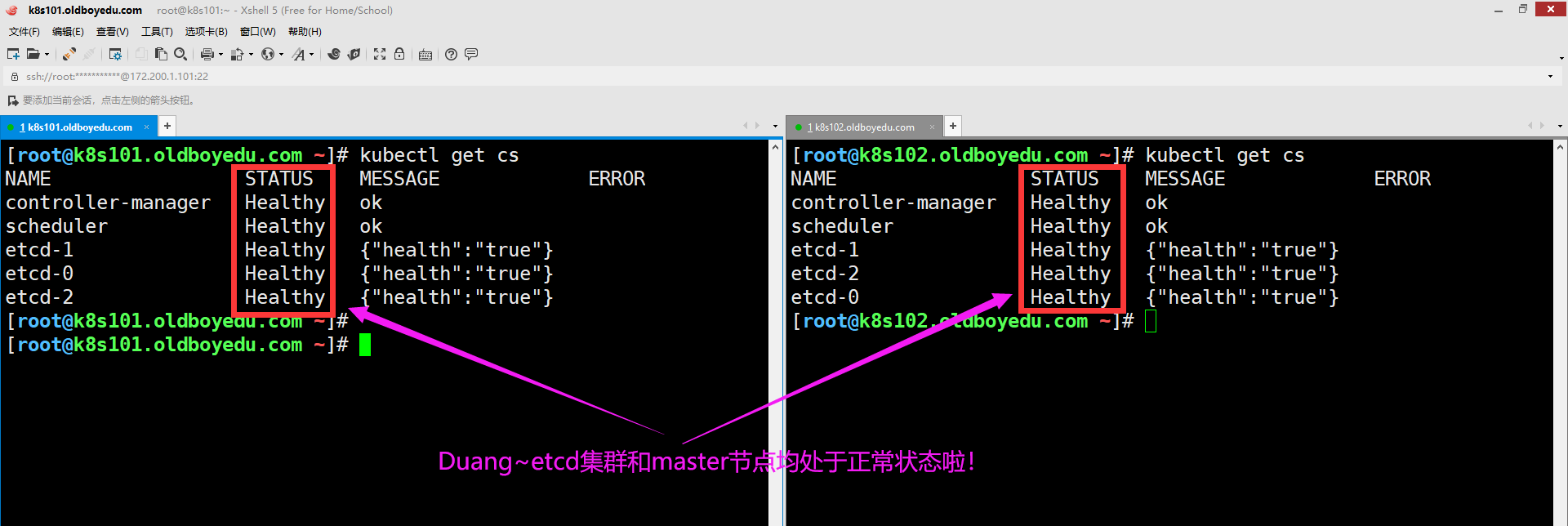
(5)验证master组件是否部署成功
kubectl get cs # 如下图所示,etcd集群和master节点均处于正常状态哟~
3.为两个master节点安装配置Keepalived并验证高可用
(1)为所有节点部署keepalived组件
yum -y install keepalived
(2)"k8s101.oldboyedu.com"节点修改配置文件如下(注意修改"interface"和"virtual_ipaddress")
[root@k8s101.oldboyedu.com ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL_11
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.250
}
}
[root@k8s101.oldboyedu.com ~]#
(3)"k8s103.oldboyedu.com"节点修改配置文件如下(注意修改"interface"和"virtual_ipaddress")
[root@k8s102.oldboyedu.com ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL_12
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.250
}
}
[root@k8s102.oldboyedu.com ~]#
(4)重启服务并设置开机自启动
systemctl enable keepalived && systemctl start keepalived
(5)将目前VIP所在节点停止keepalived服务,观察是否能实现VIP飘逸
systemctl stop keepalived # 如下图所示,我成功的实现了节点飘逸哟
systemctl start keepalived # 在101节点重新启动后,不难发现节点又会重新夺回主动权啦!
温馨提示:
我们可以使用"ip address show dev bond0"查看bond0这块网卡的绑定信息哟。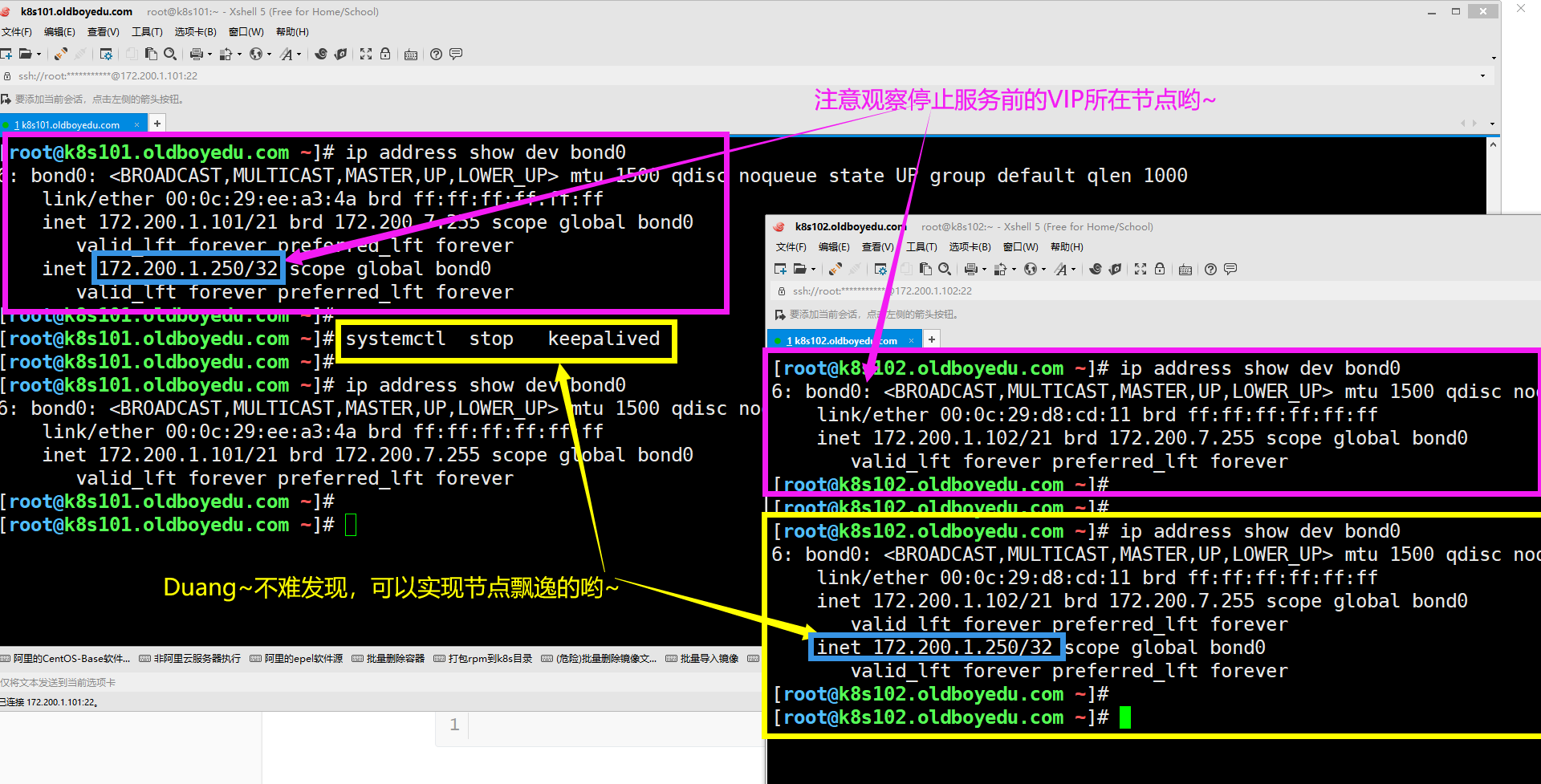
三. 部署node节点并制定keepalived的VIP地址为master节点
1.部署node组件
sed -ri 's#(keepcache=)0#\11#' /etc/yum.conf
yum -y install kubernetes-node
mkdir k8s-node
find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t k8s-node/
tar zcf oldboyedu-k8s-node.tar.gz k8s-node
温馨提示:
将打好的软件包发送到其它2个节点进行部署安装。2.修改node节点的配置文件
(1)修改kubelet组件的配置文件,尤其注意apiserver的地址是keepalive的VIP地址哟
[root@k8s103.oldboyedu.com ~]# vim /etc/kubernetes/kubelet
[root@k8s103.oldboyedu.com ~]#
[root@k8s103.oldboyedu.com ~]# egrep -v "^#|^$" /etc/kubernetes/kubelet
KUBELET_ADDRESS="--address=0.0.0.0"
KUBELET_HOSTNAME="--hostname-override=k8s103.oldboyedu.com"
KUBELET_API_SERVER="--api-servers=http://172.200.1.250:8080"
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=k8s101.oldboyedu.com:5000/pod-infrastructure:latest"
KUBELET_ARGS=""
[root@k8s103.oldboyedu.com ~]#
(2)修改config文件,将controller-manager, scheduler, 和proxy组件指定apiserver的VIP地址即可!
[root@k8s103.oldboyedu.com ~]# vim /etc/kubernetes/config
[root@k8s103.oldboyedu.com ~]#
[root@k8s103.oldboyedu.com ~]# grep ^KUBE_MASTER /etc/kubernetes/config
KUBE_MASTER="--master=http://172.200.1.250:8080"
[root@k8s103.oldboyedu.com ~]#
(3)重启NODE组件相关的服务,使之生效。
systemctl restart kubelet.service kube-proxy.service && systemctl enable kubelet.service kube-proxy.service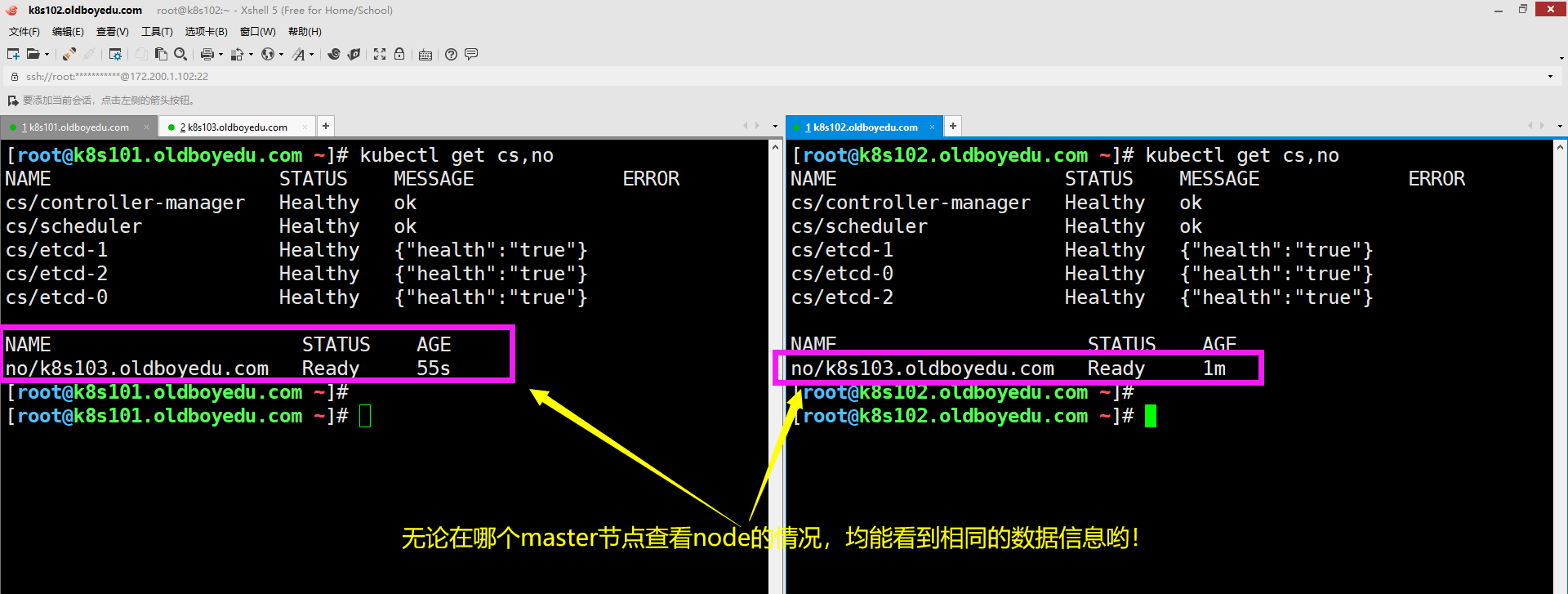
3.其它节点重复上述操作
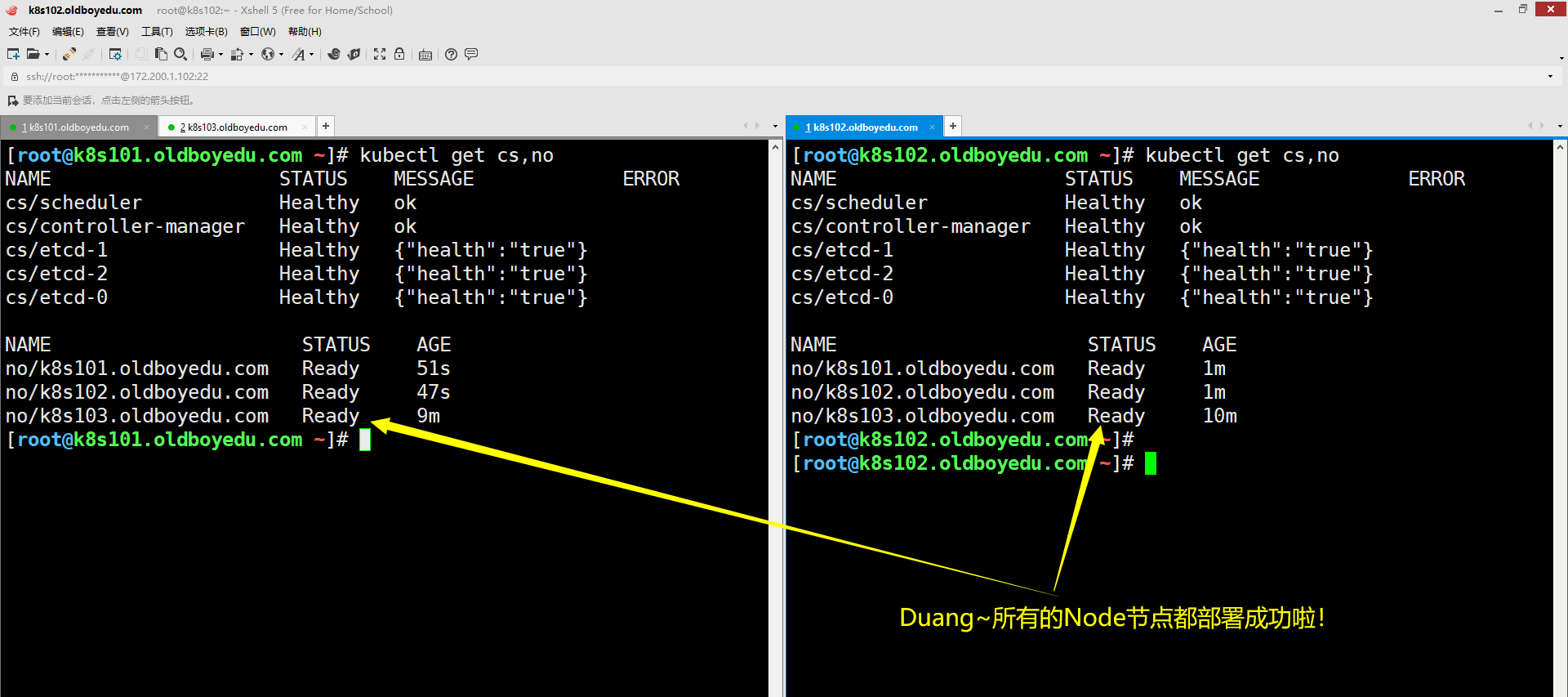
如上图所示,将已安装node节点的软件包拷贝到其它两个节点,并按需修改相关的配置参数即可。
如下图所示,我们在一个node节点也可以访问APISERVER地址哟,只需要指定相关的VIP地址即可!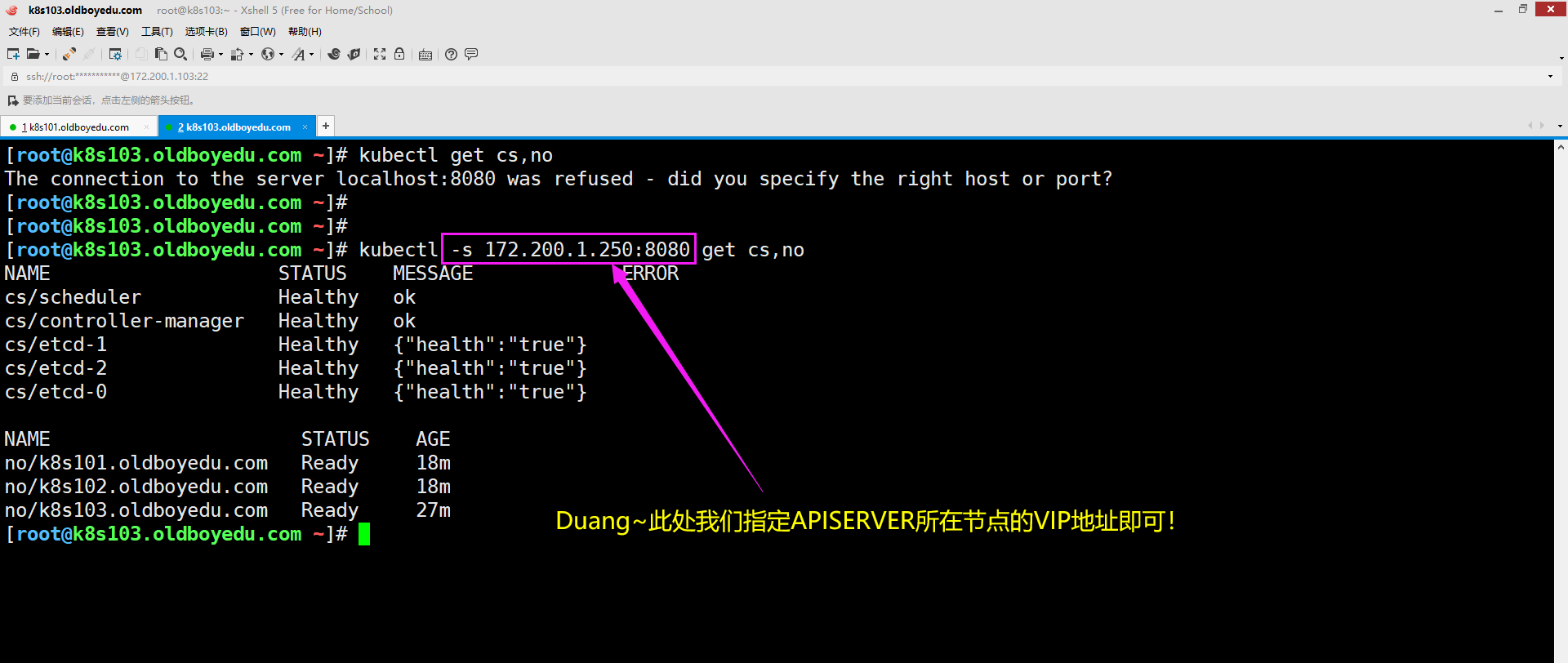
四.所有节点配置flannel网络
1.所有节点配置flannel组件
yum -y install flannel2.修改etcd数据库的初始化数据,以便于flannel组件使用
etcdctl mk /atomic.io/network/config '{"Network":"172.18.0.0/16","Backend": {"Type": "vxlan"}}'3.修改flannel组件的配置文件,指定etcd集群
[root@k8s101.oldboyedu.com ~]# grep ^FLANNEL_ETCD_ENDPOINTS /etc/sysconfig/flanneld
FLANNEL_ETCD_ENDPOINTS="http://k8s101.oldboyedu.com:2379,http://k8s102.oldboyedu.com:2379,http://k8s103.oldboyedu.com:2379"
[root@k8s101.oldboyedu.com ~]# 4.重启服务使得配置生效
systemctl enable flanneld.service docker && systemctl restart flanneld.service docker
温馨提示:
可以在两个不同的节点上启动容器,进行测试集群的可用性。5.可能会遇到的坑
(1)可能会防火墙的FORWARD链规则会变成DROP,因此我们可以在docker的启动脚本中进行修改
vim /usr/lib/systemd/system/docker.service
#在[Service]区域下增加一行
ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT
systemctl daemon-reload
systemctl restart docker
(2)可能会遇到falana1.1网络和docker0网络的网段不在同一个地址段的情况
这个时候就只能重启容器啦。五.验证集群的高可用性
1.停止master节点的keepalived组件,使得VIP进行飘逸
systemctl stop keepalived.service
温馨提示:
可以使用"ip a show dev ens33"名称查看帮助信息哈!2.集群真的是高可用吗?
如下图所示,我们上面做的操作并没有真正意义上实现的高可用性,其是存在BUG的,因此需要我们进一步优化!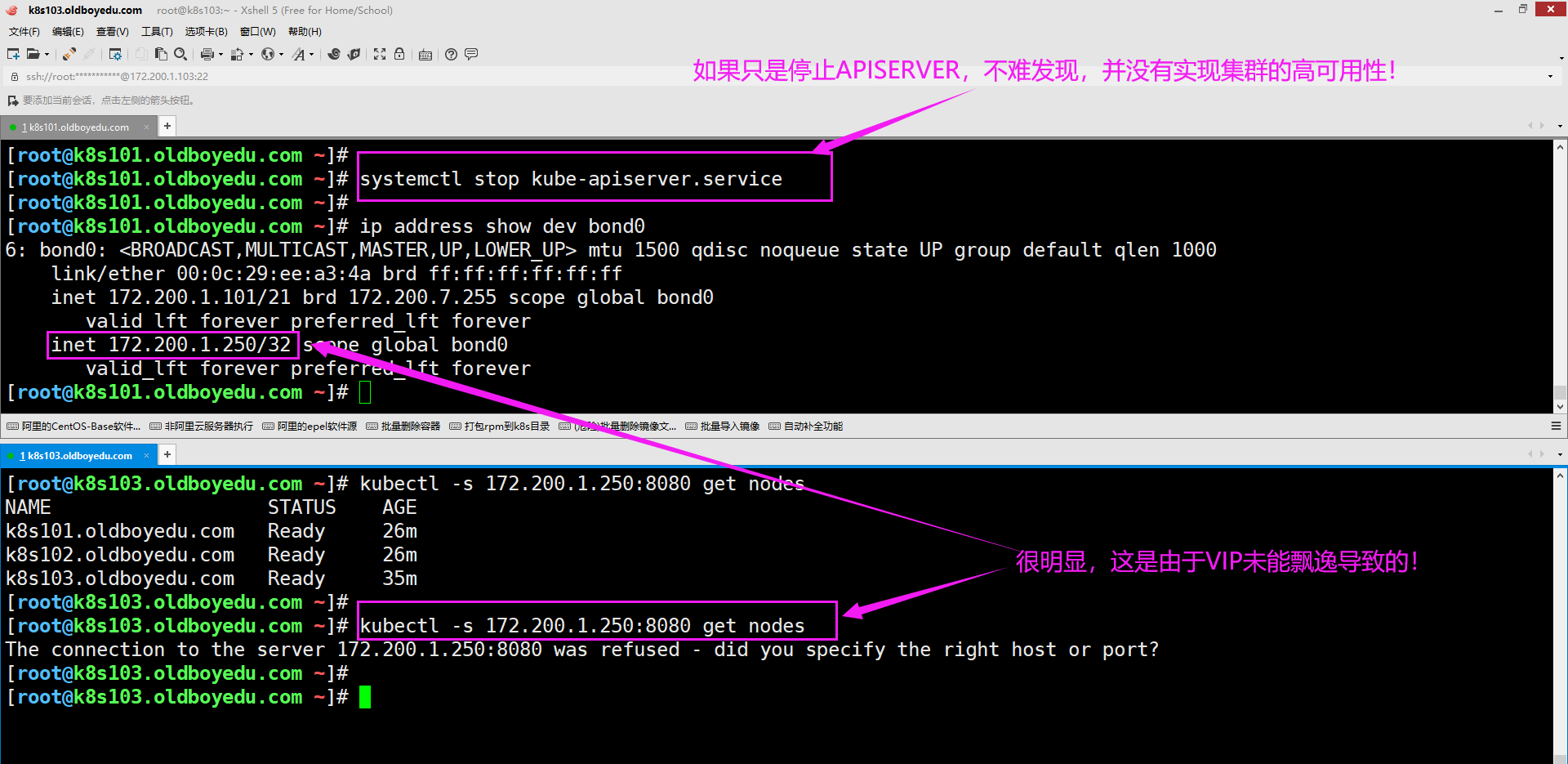
3.优化集群的高可用性
我们需要手动写一个脚本,当APISERVER进程挂掉后,就立刻杀死keepalived进程,使得集群进行飘逸。
解决方案堕入牛毛,比如:
(1)手写一个监控脚本,周期性检查APISERVER服务是否正常工作,如果服务不正常工作则停止keepalived服务;
(2)也可以借助zabbix实现APISERVER的进程监控,如果出问题了自动切换VIP并修复服务,处理后要立刻邮件告知运维人员;
温馨提示:(以下脚本仅供参考...)
[root@k8s111 ~]# vi /usr/local/bin/check-master.sh
[root@k8s111 ~]#
[root@k8s111 ~]# cat /usr/local/bin/check-master.sh
#!/bin/bash
check_apiserver=`ps -ef | grep apiserver | grep -v grep | wc -l`
echo ${check_apiserver}
if [ ${check_apiserver} -eq 0 ]; then
systemctl restart kube-apiserver.service
if [ $? -eq 0 ];then
exit
else
systemctl stop keepalived.service
fi
fi
[root@k8s111 ~]#