本文最后更新于 705 天前,其中的信息可能已经过时,如有错误请发送邮件到wuxianglongblog@163.com
Kubernetes使用ceph分布式集群存储实战篇
一.分布式存储概述
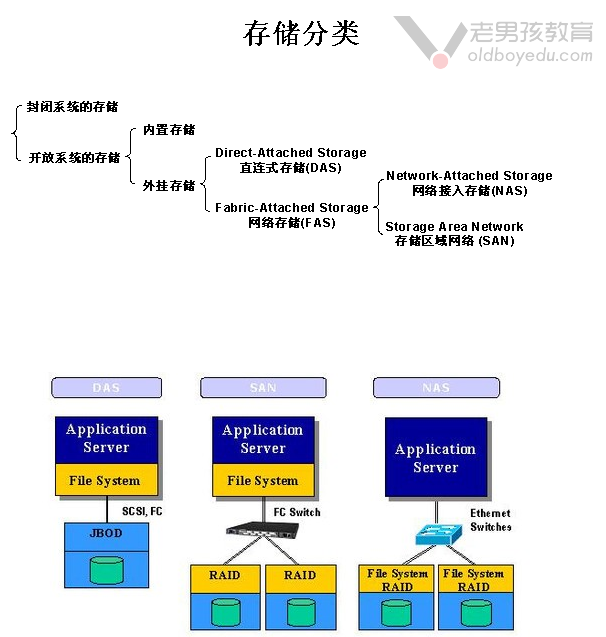
1.存储分类
存储分为封闭系统的存储和开放系统的存储,而对于开放系统的存储又被分为内置存储和外挂存储。
外挂存储又被细分为直连式存储(DAS)和网络存储(FAS),而网络存储又被细分网络接入存储(NAS)和存储区域网络(SAN)等。
DAS(Direct-attached Storage):
直连存储,即直接连接到主板的总线上去的,我们可以对这些设备进行格式化操作。典型代表有:IDE,SATA,SCSI,SAS,USB等。
SAN(Storage Area Network):
存储区域网络,是一个网络上的磁盘。它提供的是块存储而非文件系统。
早期是通过SCSI协议传输数据,后来设计通过光纤通道交换机连接存储阵列和服务器主机,也称为FC SAN,当然也可以基于以太网传输,我们称之为ISCSI协议。
NAS(Network Attached Storage):
网络附加存储,是一个网络上的文件系统,我们无法进行格式化操作。典型代表有:NFS,CIFS等。
专门的存储厂商可以通过RAID技术来实现数据的高效存储,国内外很多企业都有自己的存储设备,例如EMC,NetApp,IBM,惠普,Dell,爱数等。
但是这些专业的存储设备不仅价格是非常昂贵的,而且是非常重的,大多数都是基于FC SAN,ISCSI或者NAS访问接口,所以在某种意义上将他们的存储能力和扩展能力是非常有限的,这个时候我们就需要一个能够实现横向存储的分布式存储。
2.存储系统的分类
块存储系统:
通常对应的是一个裸设备,比如一块磁盘,我们需要格式化后进行挂载方能使用。
代表产品:
lvm,cinder。
文件系统存储系统:
文件系统只是数据组织存放的接口。文件系统通常是构建在一个块存储级别之上。
文件系统被分为元数据区域和数据区域,对于用户而言,它呈现为一个树形结构(实际上提供的是一个目录)。
代表产品:
NFS,glusterfs。
对象存储系统:
对象存储并没有向文件系统那样划分为元数据区域和数据区域,而是按照不同的对象进行存储,而且每个对象内部维护着元数据和数据区域。因此每个对象都有自己独立的管理格式。
代表产品:
Fastdfs,swift。
温馨提示:
上述存储系统的分类中,大家可能不太理解的是"对象存储系统",其实我们实际工作中经常使用,比如百度网盘,QQ离线传送文件等等。
那对象存储到底是如何存储的呢?此处我们以网盘业务为例进行分析:
Q1: 为啥网盘业务通常不会选择文件系统进行存储呢?
答: 基于文件系统进行存储会造成大量的数据冗余,以Linux用户为例,oldboy用户和root用户的家目录并不相同,如果这两个用户都有10TB的"小视频"资源,则2个用户会单独占用2份存储空间,当用户的并发量到达上百万,千万甚至上亿级别就非常浪费存储空间,对公司来说是一笔不小的开销哟。
Q2: 为啥网盘业务通常会使用对象存储呢?
答: 基于对象的一个好处是对于同一个文件始终只存储一份,尽管有上千个用户上传了同一个文件,无论该文件名称是否一致,但只要内容是同一个文件,则始终会上传一个文件哟。这也是为什么我们在上传一个文件时能达到秒传的目的。如何校验不同文件名称其存储的数据相同呢?方法有很多种,比如Linux的"md5sum"命令。
Q3: 基于对象存储的原理是如何的呢?
答: 我们假设网盘有文件的哈希值数据库,有用户表,文件和用户关系表,用户的存储容量表,用户的好友表,用户的分享资源表等等。其工作原理分析如下:
(1)客户端读取本地文件并校验值并发送服务端
当我们上传文件时,客户端程序会读取本地文件内容并计算该文件的哈希值或者是MD5值,并将该值发送给服务端;
(2)服务端校验文件是否上传
1)服务端接收到该哈希值或者是MD5值后,会去查询哈希值数据库,如果数据库有记录,说明该文件已存在,直接返回给客户端数据上传完毕,也就是我们常见的秒上传效果;
2)如果服务端发现客户端发送的哈希值不存在,才会开始上传文件,这意味着是第一次上传该对象资源哟,因此等待的时间比较长。
(3)更新用户信息的元数据
如果用户上传文件后,系统会自动更新用户的存储目录的文件名称哟,也就是元数据的更新。
某影视公司实际案例分享:(我有幸在一家影视类互联网公司工作过)
以上对于对象存储分析看似过于简单,但有助于我们理解对象存储,实际生产环境中比这个要复杂,尤其是第一次上传文件时,通常会对视频数据进行验证,比如"黄","赌","毒"相关视频禁止上传,否则国家会大力整顿。二.Ceph概述
1.Ceph分布式存储系统概述
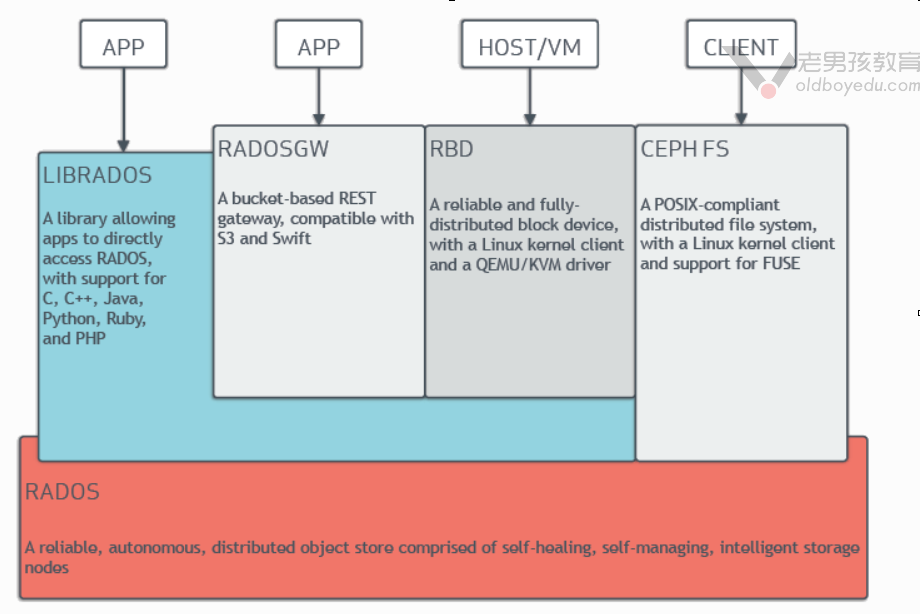
Ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取。
对象数据的底层存储服务是由多个主机(host)组成的存储系统,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠,自动化,分布式对象存储系统。
如上图所示,librados是RADOS存储集群的API,它支持C,C++,Java,Python,Ruby和PHP等编程语言。
由于直接基于librados这个API才能使用Ceph集群的话对使用者是有一定门槛的。当然,这一点Ceph官方也意识到了,于是他们还对Ceph做出了三个抽象资源,分别为RADOSGW,RBD,CEPHFS等。
RadosGw,RBD和CephFS都是RADOS存储服务的客户端,他们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用不同的应用场景,如下所示:
RadosGw:
它是一个更抽象的能够跨互联网的云存储对象,它是基于RESTful风格提供的服务。每一个文件都是一个对象,而文件大小是各不相同的。
他和Ceph集群的内部的对象(object,它是固定大小的存储块,只能在Ceph集群内部使用,基于RPC协议工作的)并不相同。
值得注意的是,RadosGw依赖于librados哟,访问他可以基于http/https协议来进行访问。
RBD:
将ceph集群提供的存储空间模拟成一个又一个独立的块设备。每个块设备都相当于一个传统磁(硬)盘一样,你可以对它做格式化,分区,挂载等处理。
值得注意的是,RBD依赖于librados哟,访问需要Linux内核支持librdb相关模块哟。
CephFS:
很明显,这是Ceph集群的文件系统,我们可以很轻松的像NFS那样使用,但它的性能瓶颈相比NFS来说是很难遇到的。
值得注意的是,CephFS并不依赖于librados哟,它和librados是两个不同的组件。但该组件使用的热度相比RadosGw和RBD要低。
推荐阅读:
查看ceph的官方文档:
https://docs.ceph.com/en/latest/
中文社区文档:
http://docs.ceph.org.cn
温馨提示:
(1)CRUSH算法是Ceph内部数据对象存储路由的算法。它没有中心节点,即没有元数据中心服务器。
(2)无论使用librados,RadosGw,RBD,CephFS哪个客户端来存储数据,最终的数据都会被写入到Rados Cluster,值得注意的是这些客户端和Rados Cluster之间应该有多个存储池(pool),每个客户端类型都有自己的存储池资源。
2.Ceph架构(Architecture)的存储流程:star:
如果我们想要将数据存储到ceph集群,那么大致步骤如下所示:
(1)Rados Cluster集群固定大小的object可能不符合我们要存储某个大文件,因此一个大文件想要存储到ceph集群,它可能会被拆分成多个data object对象进行存储;
(2)通常情况下data object请求向某个pool存储数据时,通过CRUSH算法会先对data object进行一致性哈希计算,而后将存储任务映射到到该pool中的某个PG上;
(3)紧接着,CRUSH算法(是用来完成object存储路由的一个算法)会根据pool的冗余副本数量和data object的存储类型找到足量的OSD进行存储,当然对应的PG是有active PG和standby PG角色之分的,通常副本数我们会设置为3;
相关术语如下所示:
Rados Cluster:
由多台服务器组成。
OSD:(类似于HDFS集群的datanode节点)
英文全称为"Object Storage Device",即对象存储设备,通常指的是磁盘设备,它是真正负责存储数据的设备。一台服务器上可能有多块磁盘存储设备,这属于正常现象。
通常我们需要关心以下几点:
(1)ceph OSD(object storage daemon,进程名称为"ceph-osd")存储数据、处理数据复制、恢复、重新平衡,并通过检查其他ceph OSD守护进程的心跳向ceph监控器和管理器提供一些监视信息;
(2)为了实现冗余和高可用性,通常至少需要三个Ceph osd,因为默认数据副本是3个。
mon:
全称为"monitor",即监视器,也就是我们所说的集群元数据节点(而非文件元数据)。它是用来管理整个ceph集群的运行状态(比如集群有多少台服务器,每个服务器有多少OSD及其状态信息等等)。
它是为了能够让整个集群能够正常运行而设计的角色,因此为了避免该角色存在单点故障,因此会配置高可用集群,其底层基于POSIX协议实现。
通常我们需要关注以下几点:
(1)Ceph Monitor(进程名称为"Ceph-mon")维护集群状态的映射,包括Monitor映射、manager映射、OSD映射,CRUSH映射和PG映射等;
(2)这些映射是Ceph守护进程相互协调所需的关键集群状态,例如哪些OSD是正常工作的状态,哪些PG不可用等等;
(3)监视器还负责管理守护程序和客户端之间的身份验证(基于Cephx协议实现);
(4)为了实现冗余和高可用性,通常至少需要三个监视器,这不仅仅提供了高可用性,还提供了负载均衡的能力,因为通常Monitors还扮演着"身份验证"的角色,如果配置多个监视器可以很好的进行负载均衡。
mgr:
全称为"manager",即管理者。它的作用就是用来维护查询类的操作,它将很多查询操作按照自己的方式先缓存下来,一旦有人做监控,它能做及时的响应。有点类似于zabbix agent的功能。
早期ceph的版本是没有mgr组件的,但由于mon组件每次读取数据都是实时查询的,这种代价很高昂,而监控集群又是必须的,因此在ceph的L版本引入了mgr组件。
通常我们需要关注以下几点:
(1)ceph管理器守护程序(进程名称为"ceph-mgr")负责跟踪运行时度量和ceph集群的当前状态,包括存储利用率、当前性能度量和系统负载;
(2)Ceph管理器守护进程还托管基于python的插件来管理和Rest API;
(3)高可用性通常至少需要两个管理器;
pool:
存储池,存储池的大小取决于底层的OSD的存储空间大小。一个ceph集群是可以由多个存储池构成的,而且每个存储池还可以被划分为多个不同的名称空间,而且每个名称空间可以划分成多个PG资源。
PG:
全称为"placement groups",即安置组。注意哈,Pool和PG都是抽象的概念,即实际上并不存在,它是一个虚拟的概念。我们暂时可以理解他是用来存储数据的安置组即可。
MDSs:(类似于HDFS的namenode,如果不用cephfs,该组件可以不安装)
全称为"MetaData Server",即对应cephfs文件系统的元数据服务器。如果你不需要使用cephfs可以不安装哟,如果要用的话,建议安装多个节点,以免出现单点故障的情况。
从严格意义上来讲,MDS只能算作构建于Rados存储集群之上的文件存取接口,它同RBD和RadowGW属于同一个级别,而非Ceph的基础组件。
但它却是ceph的第一个(最初也是除librados API之外的唯一一个)客户端数据存取组件。
通常我们需要关心以下几点:
(1)Ceph元数据服务器(MDS,进程名称为"ceph-mds")代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS);
(2)Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls、find等),而不会给Ceph存储集群带来巨大负担;
推荐阅读:
http://docs.ceph.org.cn/glossary/#term-56
http://docs.ceph.org.cn/architecture/#pg-id
http://docs.ceph.org.cn/architecture/#pg-osd
温馨提示:
(1)如果我们给定的存储路径是一块裸的物理磁盘(我们称之为"裸设备",也就是该设备没有被格式化指定的文件系统),则ceph是可以直接来进行管理的,只不过它使用的是bluestore存储引擎。
(2)通常情况下我们的ceph集群会有OSDs,Monitors,Managers和MDSs这几个基础组件,其中MDSs是可选的组件。
(3)RBD不需要通过运行守护进程来提供服务的,它基于librbd模块,它提供了相应的API来进行使用。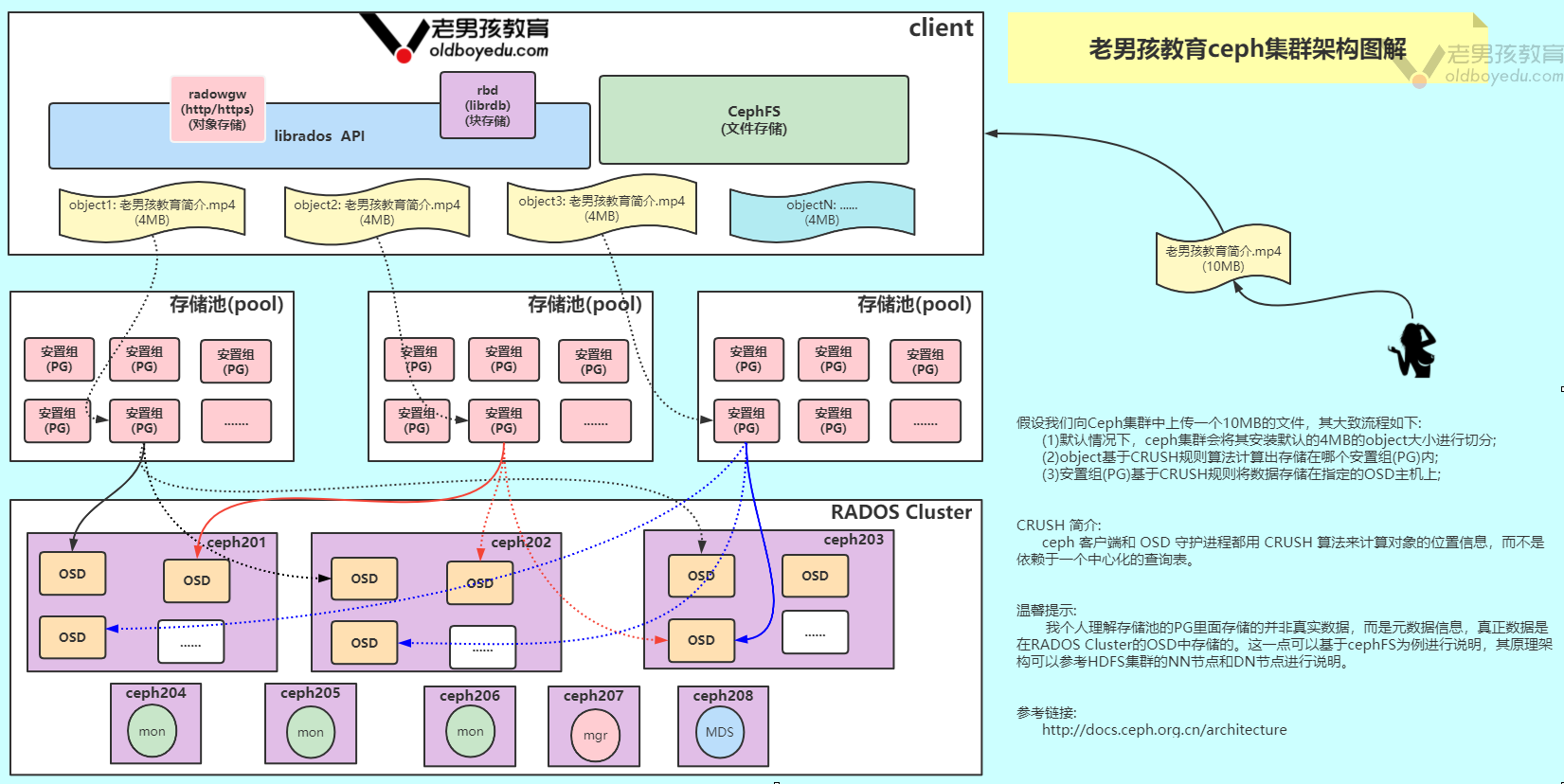
3.Ceph使用BlueStore替代了早期的FileStore
ceph是目前业内比较普遍使用的开源分布式存储系统,实现有多种类型的本地存储系统;在较早的版本当中,ceph默认使用FileStore作为后端存储,但是由于FileStore存在一些缺陷,重新设计开发了BlueStore,并在L版本之后作为默认的后端存储。
从Ceph Luminous v12.2.z 开始,默认采用了新型的BlueStore作为Ceph OSD后端,用于管理存储磁盘。
BlueStore的优势:
(1)对于大型写入操作,避免了原先FileStore的两次写入(注意,很多FileStore将journal日志存放到独立到SSD上,也能够获得类似的性能提升,不过分离journal的部署方式是绕开FileStore的短板);
(2)对于小型随机写入,BlueStore比 FileStore with journal性能还要好对于Key/value数据BlueStore性能明显提升;
(3)当集群数据接近爆满时,BlueStore避免了FileStore的性能陡降问题;
(4)在BlueStore上使用raw库的小型顺序读性能有降低,和BlueStore不采用预读(readahead)有关,但可以通过上层接口(如RBD和CephFS)来实现性能提升;
(5)BlueStore在RBD卷或CephFS文件中采用了copy-on-write提升了性能;
如下图所示,BlueStore是在底层裸块设备上建立的存储系统,内建了RocksDB key/value 数据库用于管理内部元数据。一个小型的内部接口组件称为BludFS实现了类似文件系统的接口,以便提供足够功能让RocksDB来存储它的”文件”并向BlueStroe共享相同的裸设备。
推荐阅读:
https://cloud-atlas.readthedocs.io/zh_CN/latest/ceph/bluestore.html
https://zhuanlan.zhihu.com/p/45084771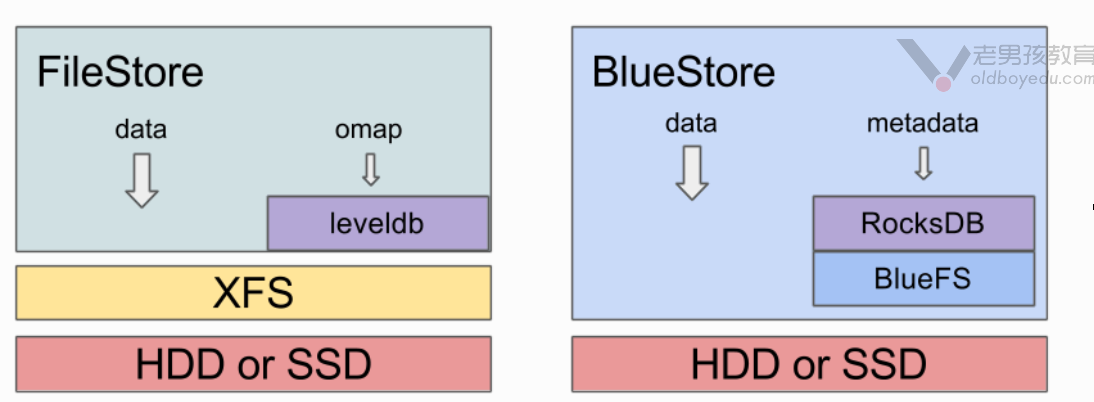
4.Ceph的管理节点(Admin Host)
Ceph的常用管理接口是一组命令行工具程序,例如rados,ceph,rbd等命令,管理员可以从某个特定的MON节点执行管理操作,但也有人更倾向于使用专用的管理节点。
事实上,专用的管理节点有助于在ceph相关的程序升级或硬件维护期间为管理员提供一个完整的,独立的并隔离于存储集群之外的操作系统,从而避免因重启或意外中断而导致维护操作异常中断。5.部署ceph集群的常用工具
ceph-deploy(ceph的原生部署工具):
(1)ceph-deploy是一种部署ceph的方法,它仅依赖于SSH访问服务器、而后借助sudo和一些Python模块就可以实现部署。
(2)它完全在工作站(管理主机)上运行,不需要任何服务、数据库或类似的东西。
(3)它不是一个通用的部署系统,它只是为Ceph设计的,并且是为那些希望在不需要安装Chef、Puppet或Juju的情况下使用合理的初始设置快速运行Ceph的用户而设计的。
(4)除了推送Ceph配置文件之外,它不会处理客户端配置,想要对安全设置、分区或目录位置进行精确控制的用户应该使用Chef或Puppet之类的工具。
ceph-ansible:
(1)我们可以使用ansible的playbook来部署Ceph;
(2)ceph的GitHub地址为: "https://github.com/ceph/ceph-ansible"
ceph-chef:
对应的GitHub地址: "https://github.com/ceph/ceph-chef"
puppet-ceph:
即使用puppet工具来部署ceph。三.Ceph部署实战案例
1.准备3台节点,所有节点都添加映射关系
[root@ceph201.oldboyedu.com ~]# grep oldboyedu /etc/hosts
10.0.0.0.201 ceph201.oldboyedu.com
10.0.0.0.202 ceph202.oldboyedu.com
10.0.0.0.203 ceph203.oldboyedu.com
[root@ceph201.oldboyedu.com ~]#
scp /etc/hosts ceph201.oldboyedu.com:/etc/hosts
scp /etc/hosts ceph202.oldboyedu.com:/etc/hosts
scp /etc/hosts ceph203.oldboyedu.com:/etc/hosts
温馨提示:
如果主机名写的是FQDN,则部署集群时可能会出错,请慎重!
因此我推荐大家直接使用"ceph201","ceph202","ceph203"这些主机列表即可。2.配置免密登录(后续ceph-deploy工具依赖免密登录)
(1)在"ceph201.oldboyedu.com"节点生成密钥
[root@ceph201.oldboyedu.com ~]# ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' -q
(2)拷贝密钥到其它节点
ssh-copy-id ceph201
ssh-copy-id ceph202
ssh-copy-id ceph203
(3)让所有节点公用同一套密钥
scp -rp ~/.ssh ceph202:~
scp -rp ~/.ssh ceph203:~
温馨提示:
如果按照上面的方式操作,意味着所有节点均可以免密访问到其它任意节点哟~3."ceph201.oldboyedu.com"节点安装"ceph-deploy"工具,用于后期部署ceph集群
(1)准备国内的软件源(含基础镜像软件源和epel源)
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
(2)配置ceph软件源
cat > /etc/yum.repos.d/oldboyedu-ceph.repo <<'EOF'
[oldboyedu-ceph]
name=oldboyedu ceph 2021
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/x86_64/
gpgcheck=0
enable=1
[oldboyedu-ceph-tools]
name=oldboyedu ceph tools
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/noarch/
gpgcheck=0
enable=1
EOF
(3)"ceph201.oldboyedu.com"节点安装"ceph-deploy"工具,用于后期部署ceph集群
sed -ri 's#(keepcache=)0#\11#' /etc/yum.conf
yum makecache
yum -y install ceph-deploy
(4)将rpm软件源推送到其它节点
scp /etc/yum.repos.d/*.repo ceph202.oldboyedu.com:/etc/yum.repos.d/
scp /etc/yum.repos.d/*.repo ceph203.oldboyedu.com:/etc/yum.repos.d/
4.ceph环境准备
(1)"ceph201.oldboyedu.com"节点安装ceph环境
yum -y install ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds ceph-osd
相关软件包功能说明如下:
ceph:
ceph通用模块软件包。
ceph-mon:
ceph数据的监控和分配数据存储,其中mon是monitor的简写。
ceph-mgr:
管理集群状态的组件。其中mgr是manager的简写。基于该组件我们可以让zabbix来监控ceph集群哟。
ceph-radosgw:
对象存储网关,多用于ceph对象存储相关模块软件包。
ceph-mds:
ceph的文件存储相关模块软件包,即"metadata server"
ceph-osd
ceph的块存储相关模块软件包。
(2)将软件打包到本地并推送到其它节点
mkdir ceph-rpm
find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t ceph-rpm/
tar zcf oldboyedu-ceph.tar.gz ceph-rpm
scp oldboyedu-ceph.tar.gz ceph202.oldboyedu.com:~
scp oldboyedu-ceph.tar.gz ceph203.oldboyedu.com:~
(3)其它节点安装ceph环境
tar xf oldboyedu-ceph.tar.gz && cd ~/ceph-rpm && yum -y localinstall *.rpm
温馨提示:
如下图所示,三个节点的ceph环境部署完毕啦~
5.初始化ceph的配置文件
(1)自定义创建ceph的配置文件目录~
mkdir -pv /oldboyedu/ceph/cluster && cd /oldboyedu/ceph/cluster/
(2)初始化ceph的配置文件,注意观察执行命令的所在目录文件变化哟~
ceph-deploy new --public-network 10.0.0.0/24 ceph201 ceph202 ceph203
温馨提示:
(1)如上图所示,我们可以使用"--cluster-network"参数创建集群内部的网络,其通常是集群内部通信的网段。而"--public-network"参数用于创建集群外部的网络,通常是客户端访问的网络,生产环境中建议分开配置。我这里就没有使用"--cluster-network"参数,若不是用则默认仅使用同一套网络哟。
(2)如下图所示,当我们执行伤处命令后,就会生成相应的ceph配置文件哟~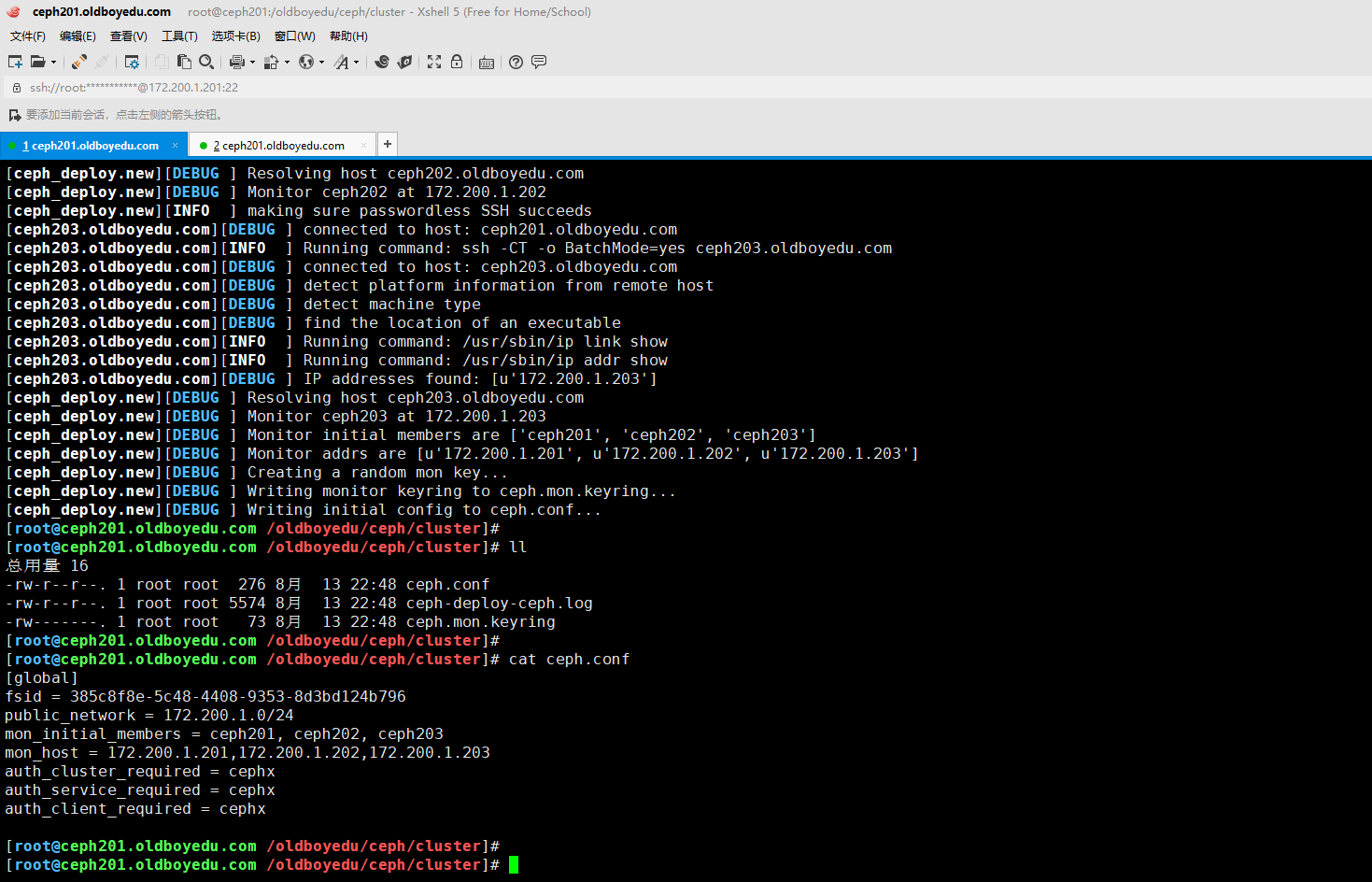
6.安装ceph-monitor并启动ceph-mon
cd /oldboyedu/ceph/cluster/ && ceph-deploy mon create-initial
温馨提示:
安装成功后记得查看一下进程信息哈。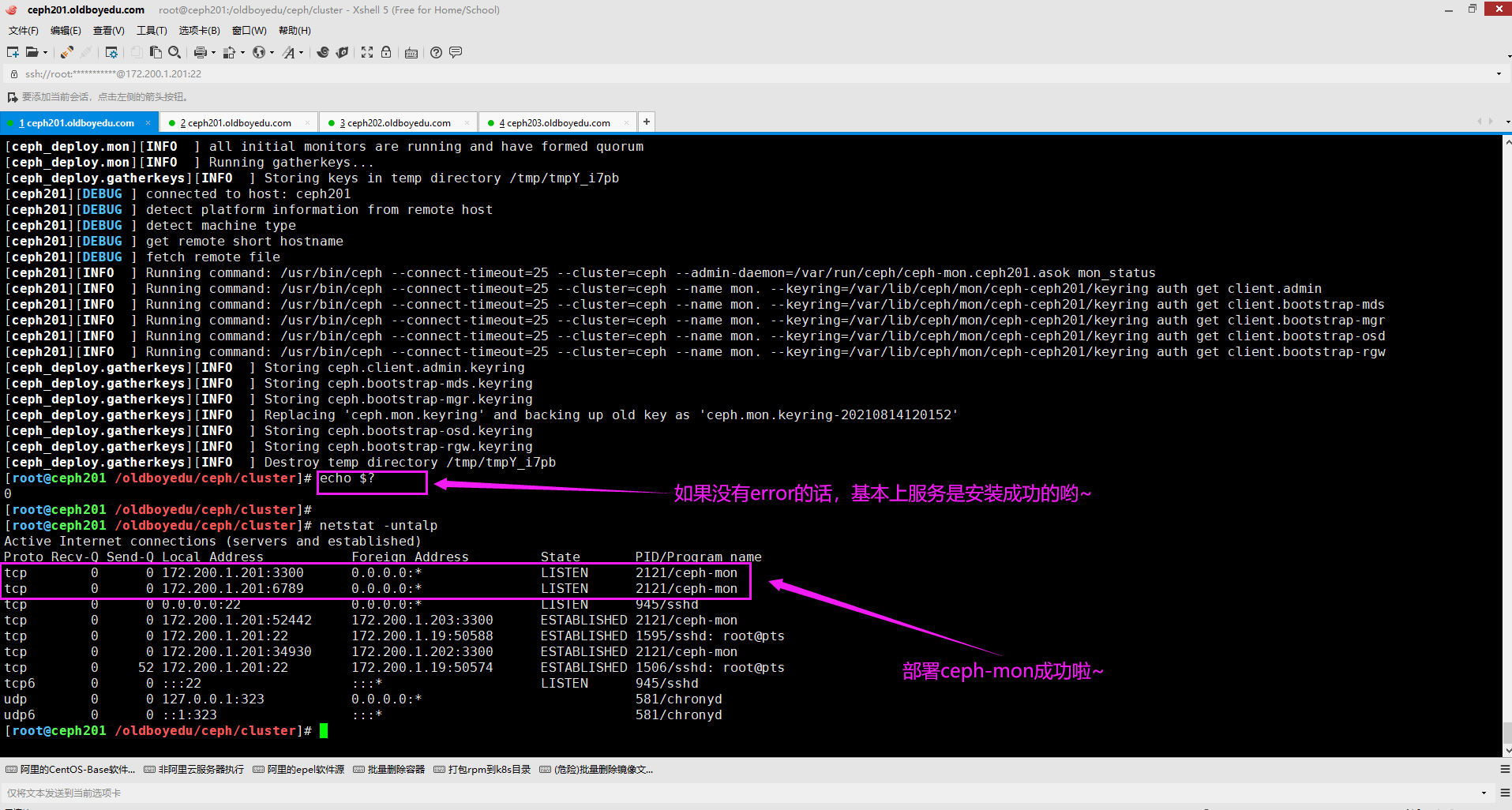
7.将配置和client.admin密钥推送到指定的远程主机以便于管理集群。
cd /oldboyedu/ceph/cluster/ && ceph-deploy admin ceph201 ceph202 ceph203
温馨提示:
(1)我们可以使用"ceph -s"指令查看集群的状态;
(2)关于上述命令的说明的用法及说明可自行参考"ceph-deploy admin -h"。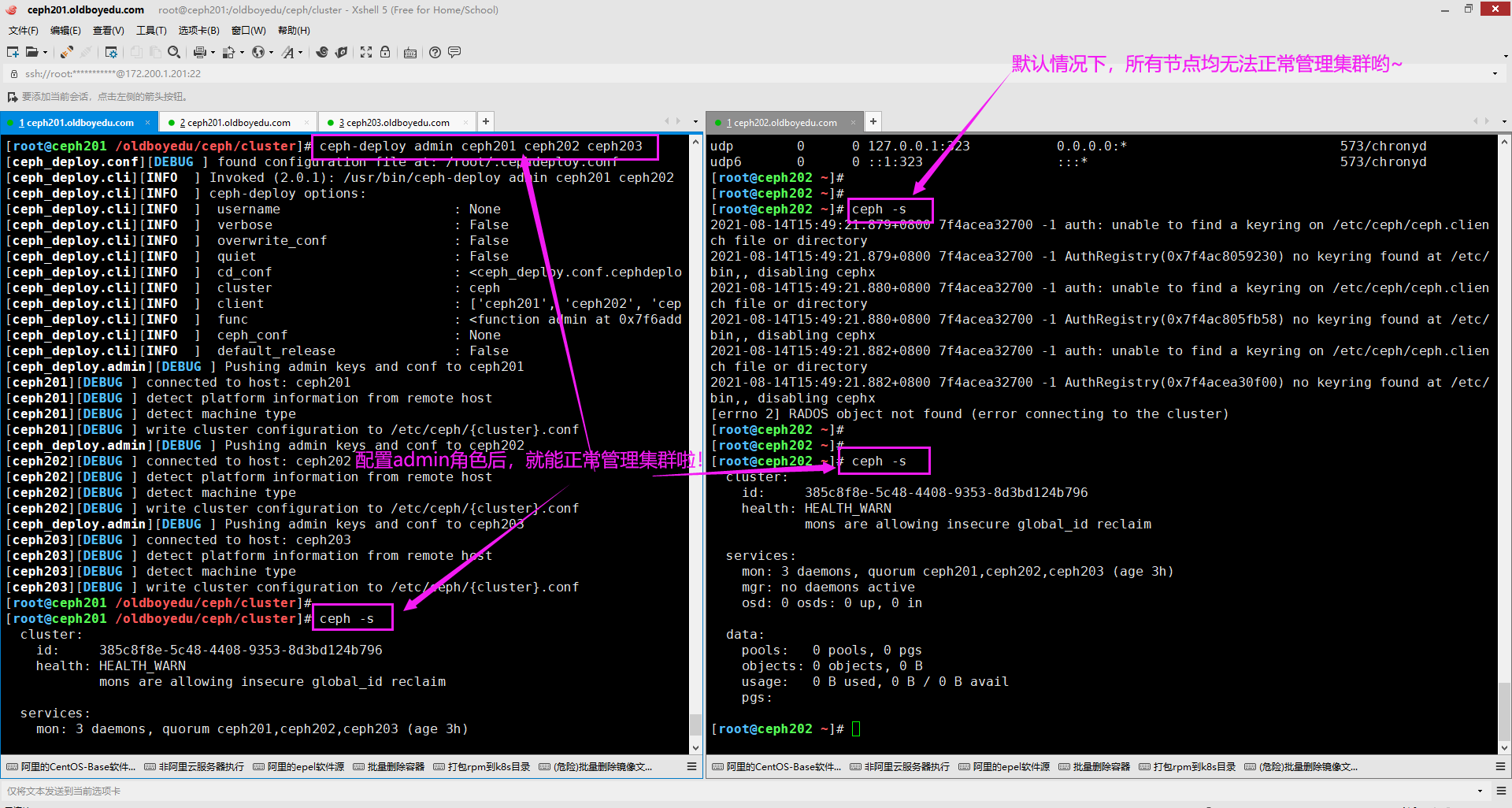
8.安装并启动ceph-mgr组件
cd /oldboyedu/ceph/cluster/ && ceph-deploy mgr create ceph201 ceph202 ceph203
温馨提示:
如下图所示,当我们安装mgr组件后,可以再次使用"ceph -s"查看集群状态哟。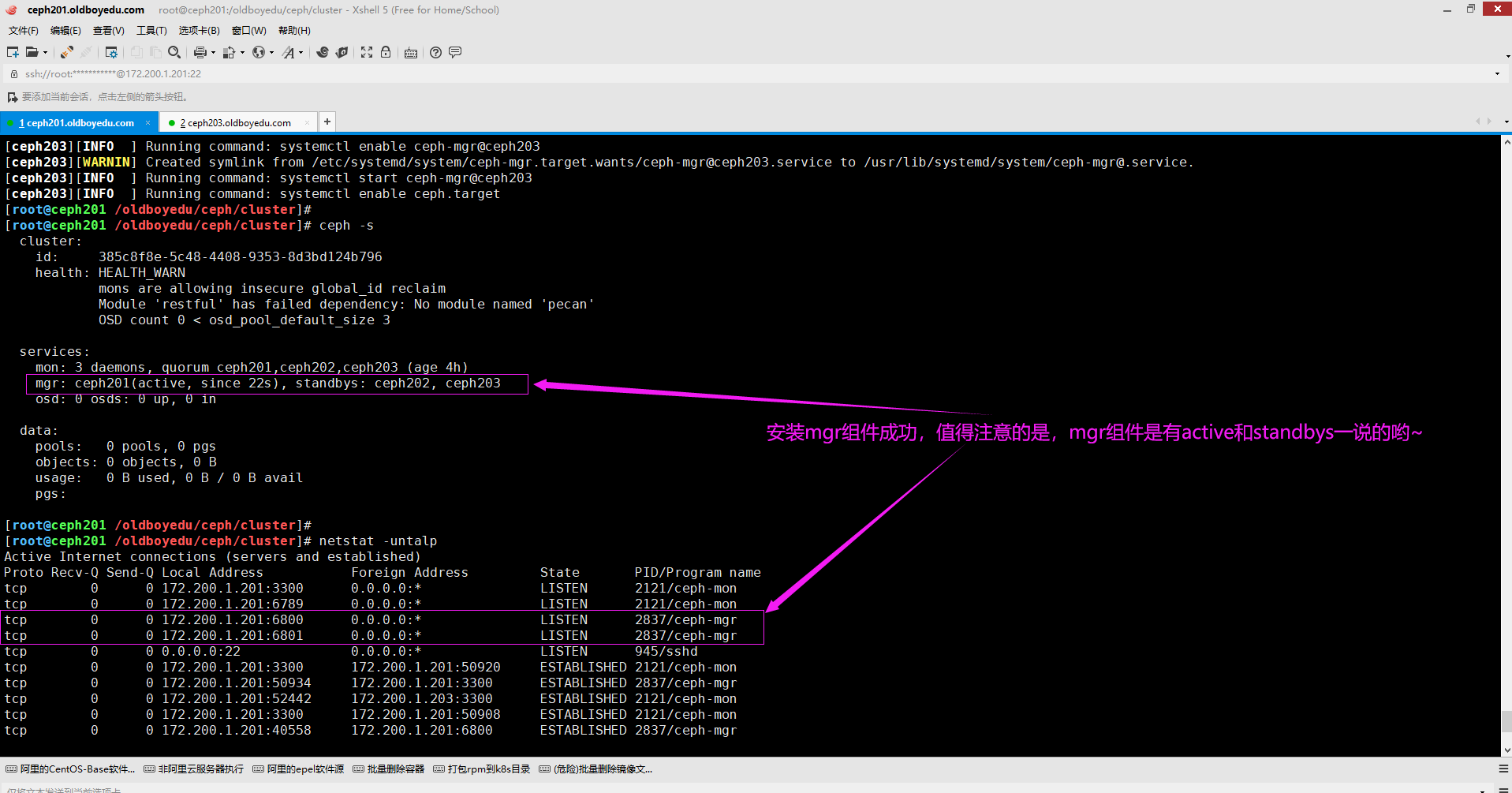
9.安装OSD设备
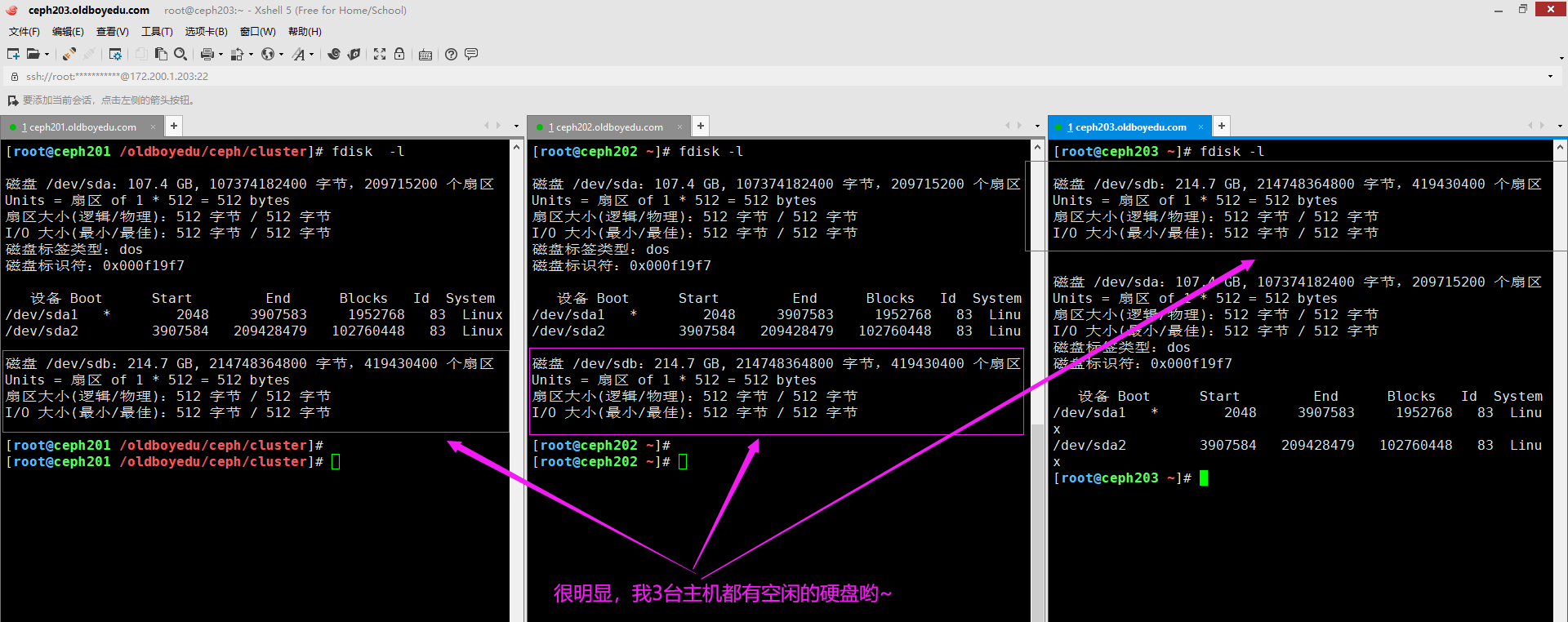
cd /oldboyedu/ceph/cluster
ceph-deploy osd create ceph201 --data /dev/sdb
ceph-deploy osd create ceph202 --data /dev/sdb
ceph-deploy osd create ceph203 --data /dev/sdb
创建OSD是要注意的相关参数说明:
--data DATA:
指定逻辑卷或者设备的绝对路径。
--journal JOURNAL:
指定逻辑卷或者GPT分区的分区路径。生产环境强烈指定该参数,并推荐使用SSD设备。
因为ceph需要先预写日志而后才会真实写入数据,从而达到防止数据丢失的目的。
若不指定该参数,则日志会写入"--data"指定的路径哟。从而降低性能。
对于一个4T的数据盘,其日志并不会占据特别多的空间,通常情况下分配50G足以,当然,LVM是支持动态扩容的。
温馨提示:
(1)如上图所示,指定的设备各个服务器必须存在哟;
(2)如下图所示,当我们创建OSD成功后,就可以通过"ceph -s"查看集群状态了哟;
(3)如下图所示,我们可以通过"ceph osd tree"查看集群各个osd的情况;
(4)如果一个ceph集群的某个主机上有多块磁盘都需要加入osd,只需重复执行上述步骤即可;
(5)如果添加硬盘未识别可执行以下语句:
for i in `seq 0 2`; do echo "- - -" > /sys/class/scsi_host/host${i}/scan;done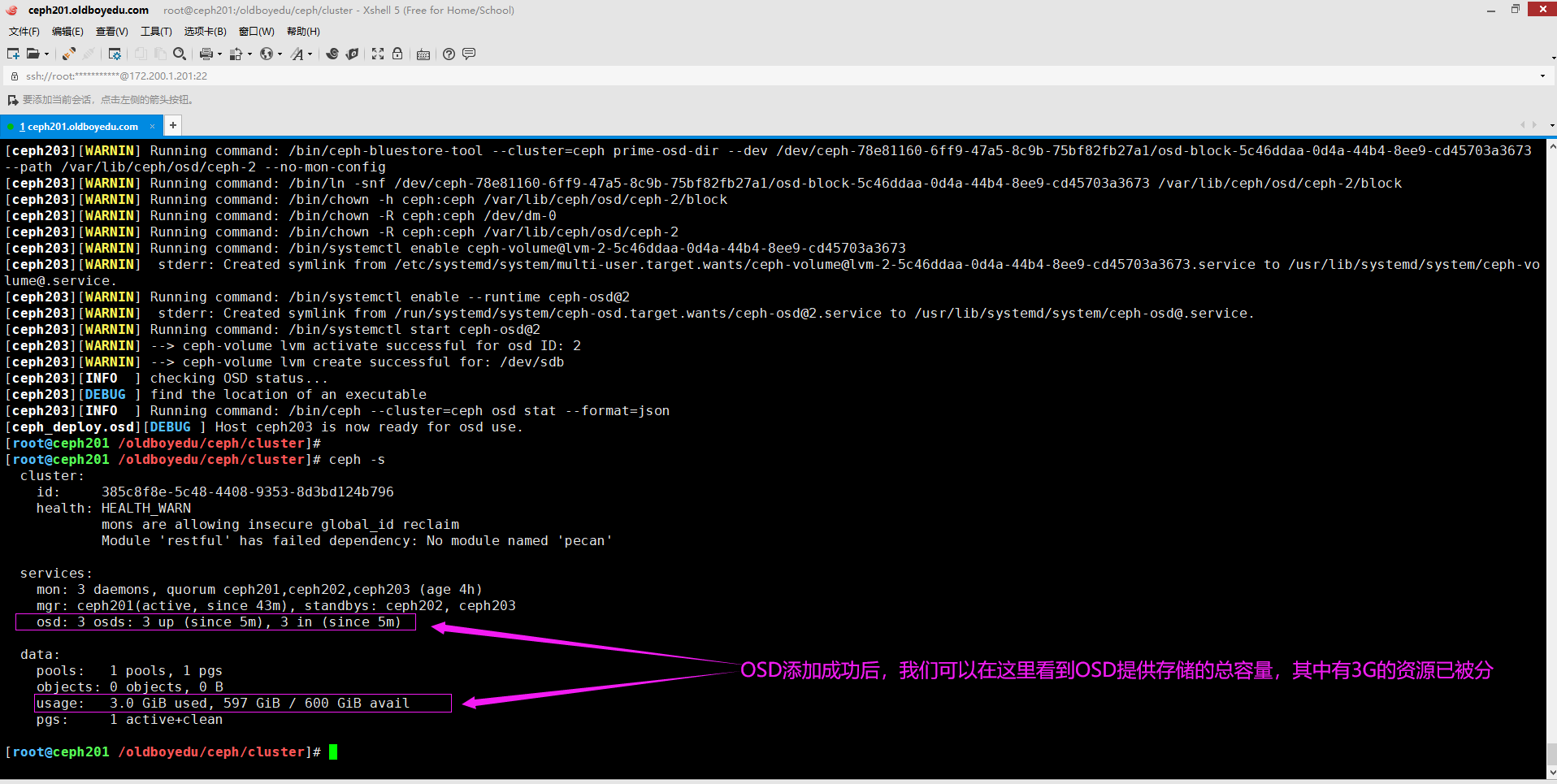
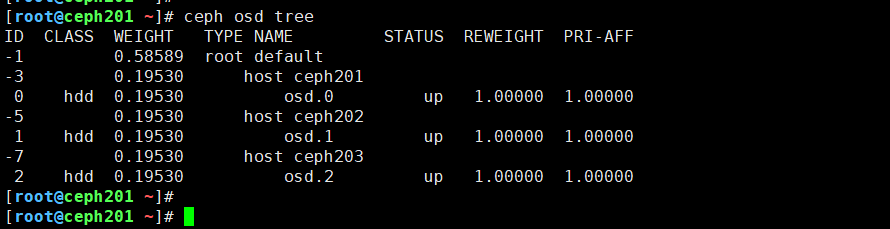
10.集群部署成功
如下图所示,集群处于健康状态哟。
温馨提示:
(1)如果集群处于不健康状态,我建议及时修复,直到修复为"health: HEALTH_OK"即可。
(2)对于集群不健康状态我在笔记后面有相关的排错笔记,希望对你有帮助哈~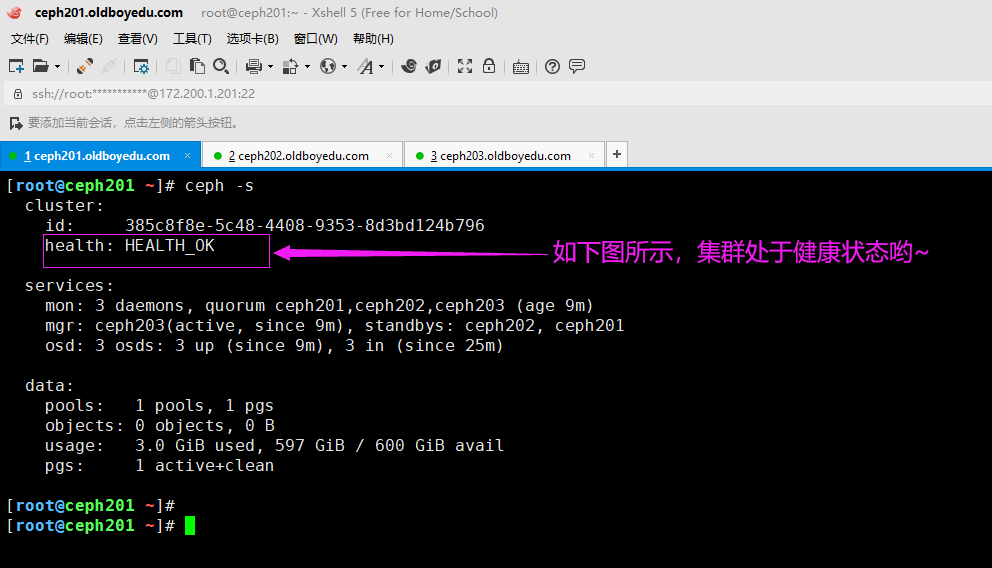
四.ceph块存储的使用
1.ceph的存储池基本管理
(1)查看现有的所有资源池
ceph osd pool ls
(2)创建资源池
ceph osd pool create oldboyedu-linux 128 128
(3)查看存储池的参数信息(这个值可能会不断的变化哟~尤其是在重命名后!)
ceph osd pool get oldboyedu-linux pg_num
(4)资源池的重命名
ceph osd pool rename oldboyedu-linux oldboyedu-linux-2021
(5)查看资源池的状态
ceph osd pool stats
(6)删除资源池(需要开启删除的功能,否则会报错哟~而且池的名字得写2次!)
ceph osd pool rm oldboyedu-linux-2021 oldboyedu-linux-2021 --yes-i-really-really-mean-it
其他使用方法:
"ceph osd pool --help"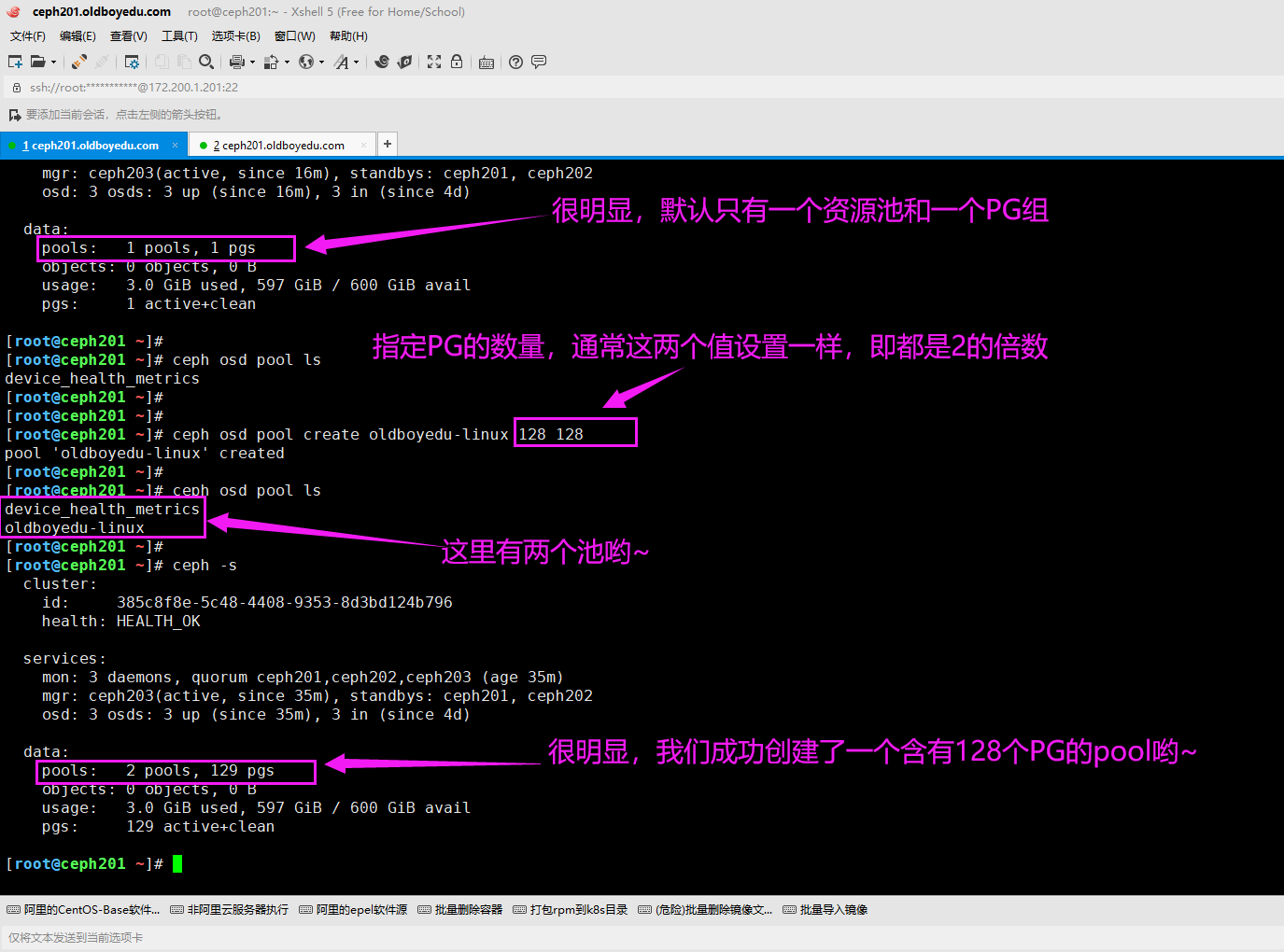
2.rbd的块设备(镜像,image)管理
(1)查看rbd的块(镜像,image)设备:
rbd list -p oldboyedu-linux
rbd ls -p oldboyedu-linux --long --format json --pretty-format # 可以指定输出的样式
(2)创建rbd的块设备:(下面两种写法等效哟)
rbd create --size 1024 --pool oldboyedu-linux linux76 # 不指定单位默认为M
rbd create --size 1024 oldboyedu-linux/linux76
rbd create -s 2G -p oldboyedu-linux oldboyedu-zhibo2021 # 也可以指定单位,比如G
(3)修改镜像设备的名称
rbd rename|mv -p oldboyedu-linux oldboyedu-zhibo oldboyedu-linux
(4)查看镜像的状态
rbd status -p oldboyedu-linux oldboyedu-zhibo2021
(5)移除镜像文件
rbd remove|mv -p oldboyedu-linux oldboyedu-zhibo2021
(6)查看rbd的详细信息:
rbd info -p oldboyedu-linux linux76 # 等效于rbd info oldboyedu-linux/linux76
rbd info -p oldboyedu-linux oldboyedu-zhibo2021 --format json --pretty-format
温馨提示:
(1)如果是ceph的客户端,想要操作rbd必须安装该工具,其安装包可参考"rpm -qf /usr/bin/rbd"哟;
(2)以上参数有任何不懂的,可以直接使用'rbd help <command>'来查看此命令的帮助信息哟;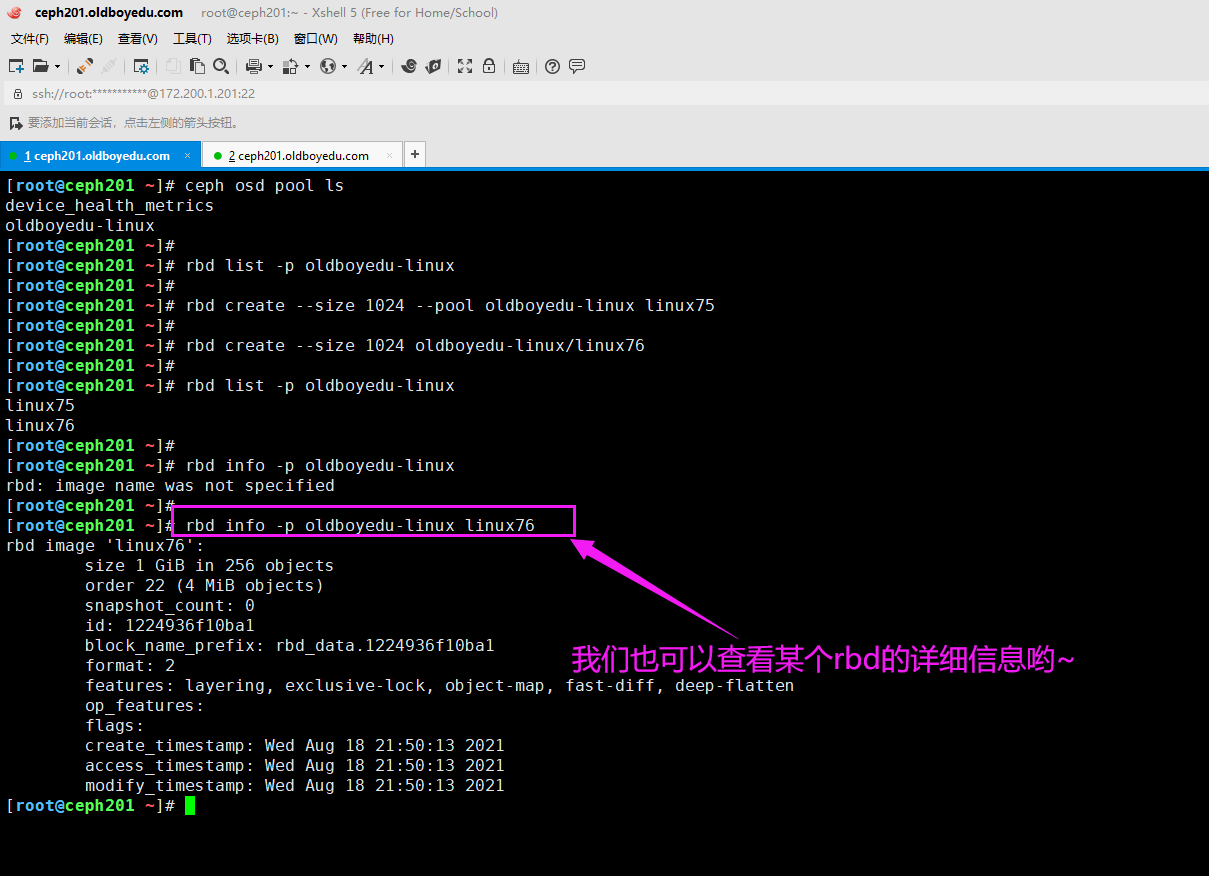
3.禁用Linux不支持的核心特性
rbd feature disable oldboyedu-linux/linux76 object-map fast-diff deep-flatten
温馨提示:
如下图所示,我们可以临时禁用以上3个特性,因为centos:7默认的内核是不支持这些特性的。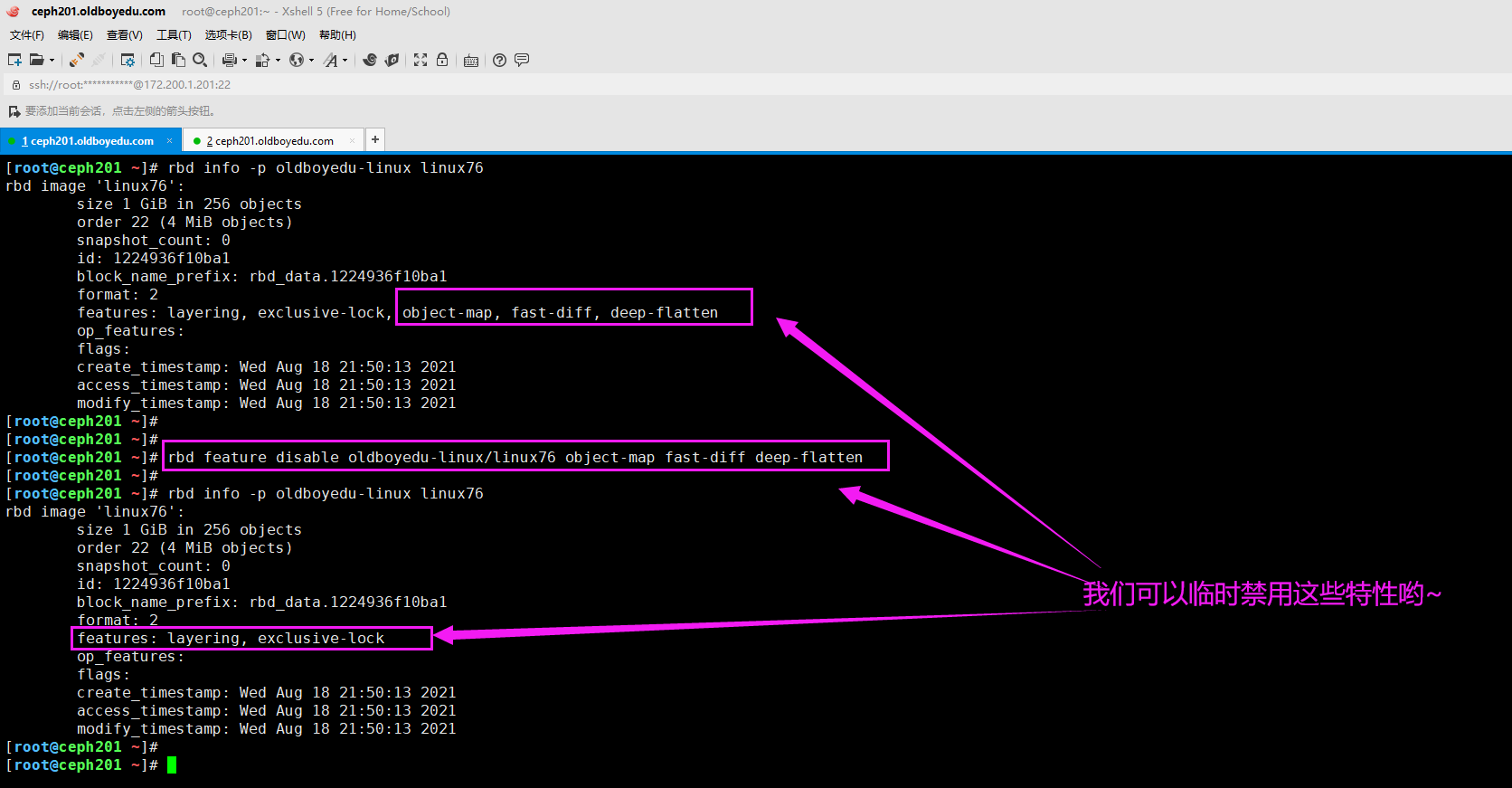
4.挂载rbd的块设备
添加映射关系:(添加设备)
rbd map oldboyedu-linux/linux76
删除映射关系:(删除设备)
rbd map oldboyedu-linux/linux76
格式化磁盘:
mkfs.xfs /dev/rbd0
挂载磁盘:
mount /dev/rbd0 /mnt/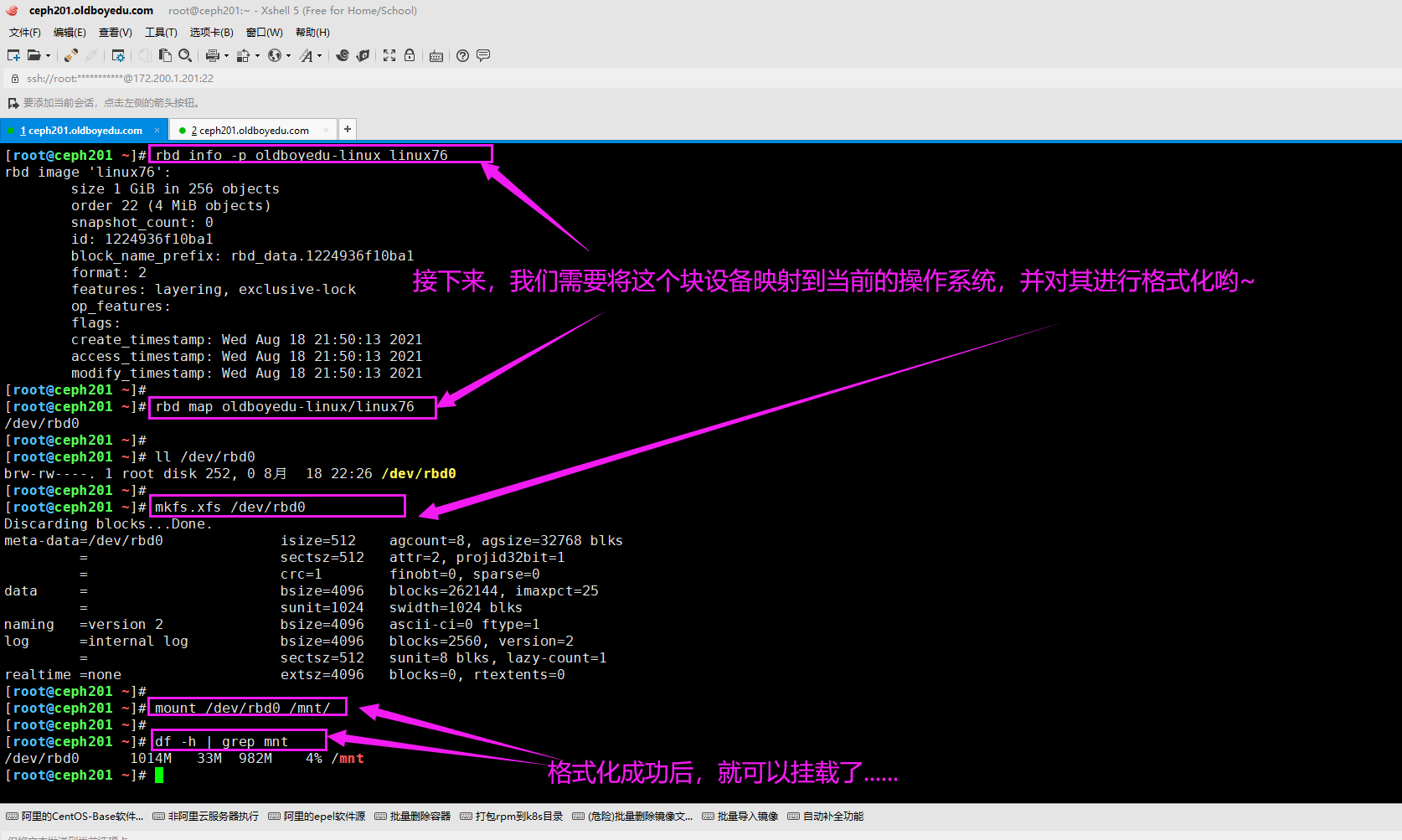
5.使用rbd块设备
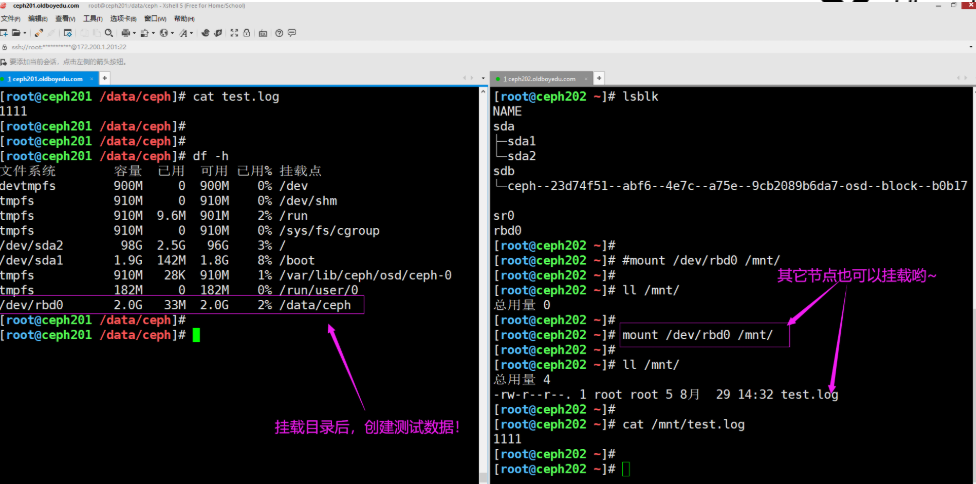
(1)查看块设备信息
rbd info -p oldboyedu-linux linux76 | grep block
(2)查看存储的object
rados ls -p oldboyedu-linux | grep "rbd_data.1224936f10ba1"
(3)创建测试文件
dd if=/dev/zero of=/mnt/bigfile.log bs=100M count=1
温馨提示:
(1)一个rbd集群的同一个image设备可以挂载到不同的节点上;
(2)但同一个image设备在不同的节点上很难实现的数据的同步哟,因此不建议这样做;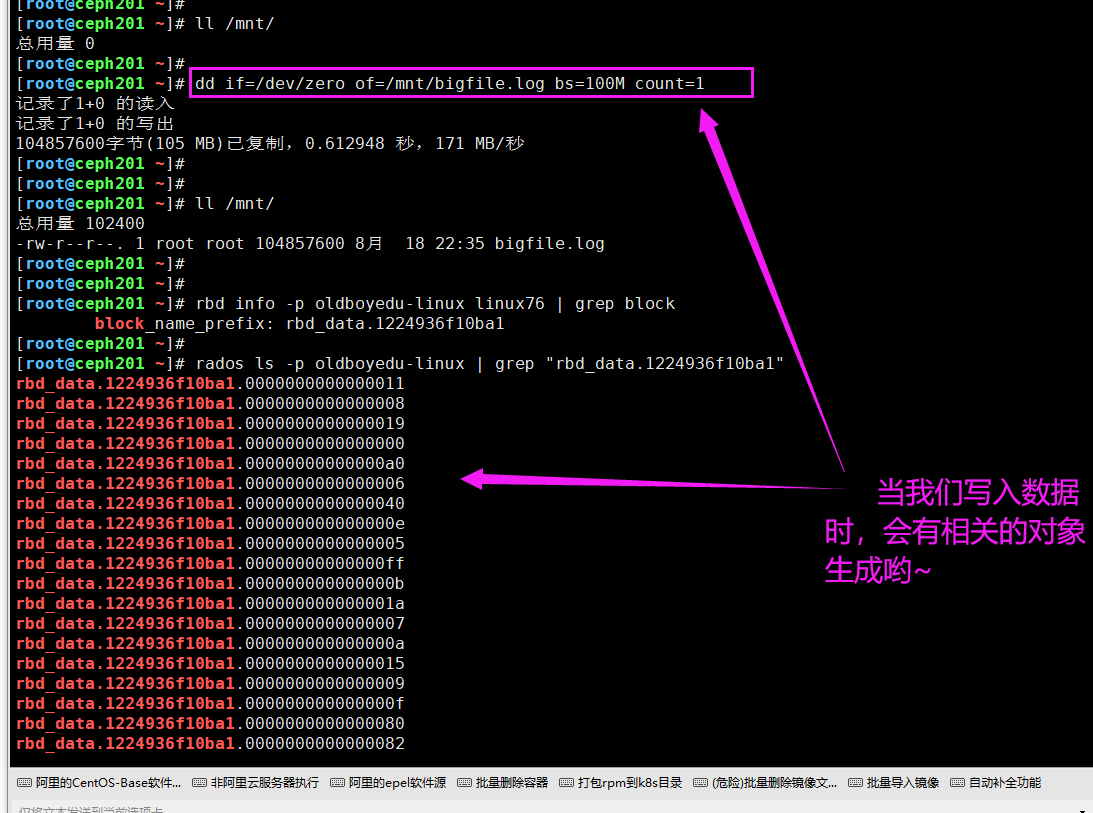
6.扩容rbd块设备
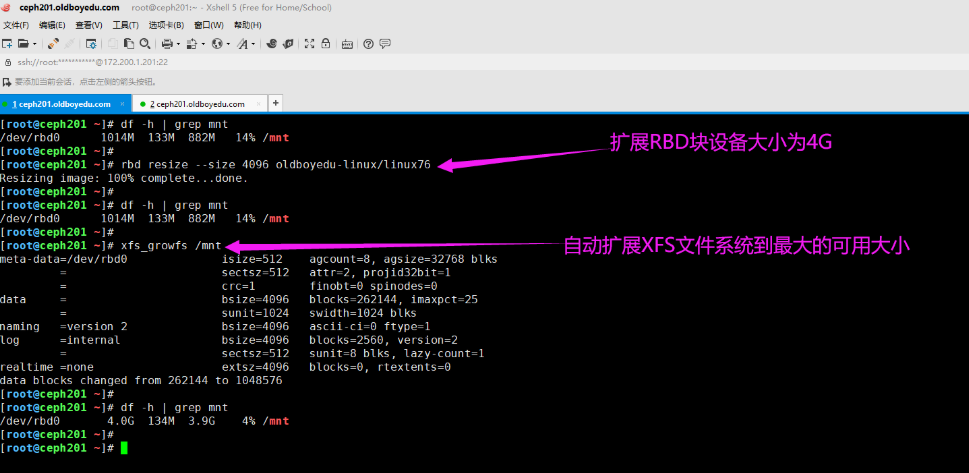
自动扩缩容磁盘大小:(扩容正常,缩容可能会导致设备不可用!需要进一步调研,生产环境要充分测试方能使用!)
rbd resize --size 4096 oldboyedu-linux/linux76
rbd resize -s 1G oldboyedu-linux/linux76 --allow-shrink # 慎用,可能会导致设备不可用!
自动扩展XFS文件系统到最大的可用大小:
xfs_growfs /mnt
温馨提示:
(1)如上图所示,我们可以对一个镜像设备进行扩容,是符合正常逻辑的;
(2)如下图所示,我们可以对一个镜像进行缩容,但可能会造成数据丢失,甚至挂载镜像失败的情况哟;
五.ceph集群扩容osd节点
1.添加osd的准备条件
为什么要添加OSD?
因为随着我们对ceph集群的使用,资源可能会被消耗殆尽,这个时候就得想法扩容集群资源,对于ceph存储资源的扩容,我们只需要添加相应的OSD节点即可。
添加OSD的准备条件:
如下图所示,我们需要单独添加一个新的节点并为其多添加一块磁盘。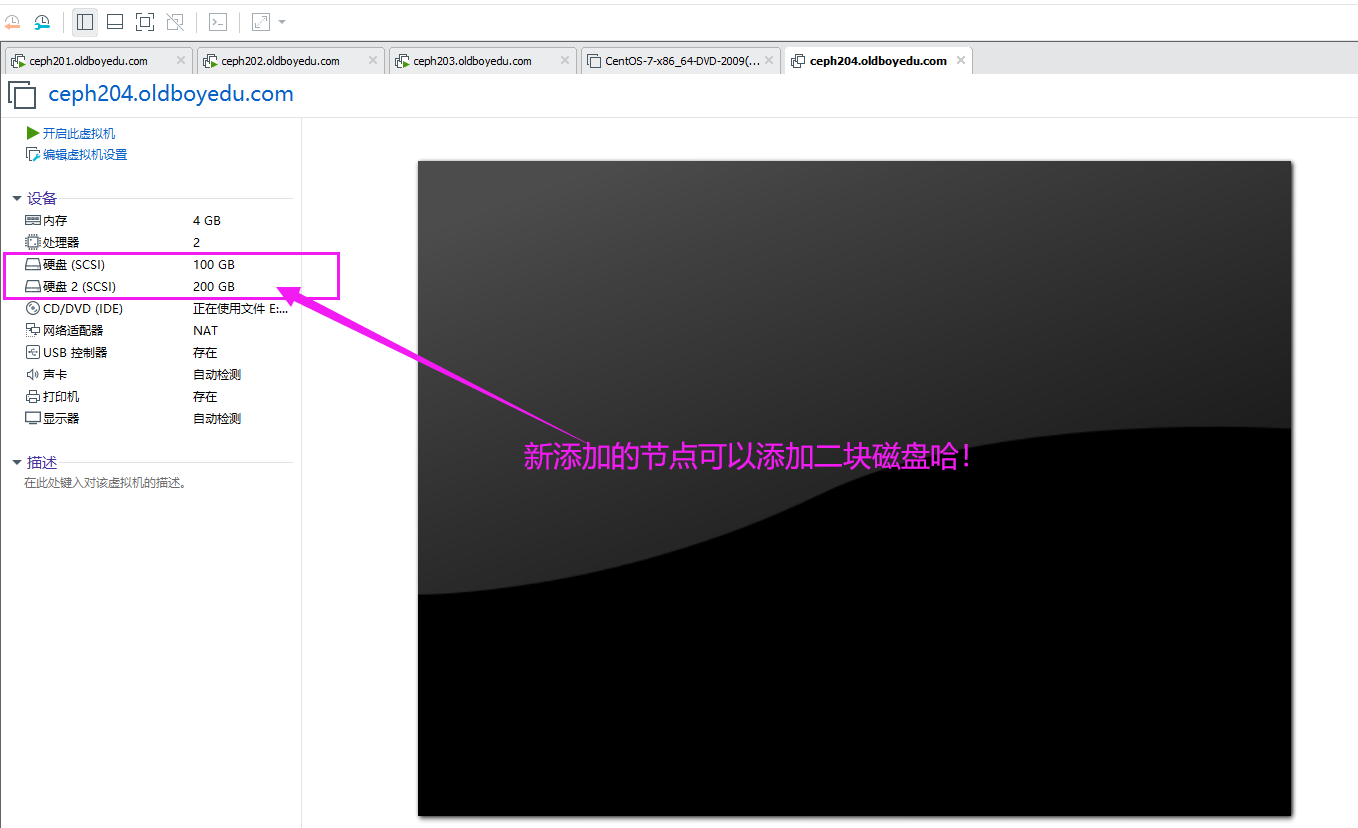
2.新增节点配置解析记录
如下图所示,将hosts文件的解析同步到新增的节点,并配置免密登录哟~
3.新增节点部署ceph软件包
(1)配置案例的软件源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
(2)将ceph101的yum仓库配置文件拷贝到ceph204
scp /etc/yum.repos.d/oldboyedu-ceph.repo ceph204:/etc/yum.repos.d/
(3)ceph204节点只需安装osd相关的组件即可,因为它并不作为管理节点,而是作为存储节点哟。
yum -y install ceph-osd
systemctl stop firewalld && systemctl disable firewalld # 禁用防火墙功能。
温馨提示:
如下图所示,请及时在ceph节点安装以下的软件包哟,否则你会发现始终无法添加节点呢。
python36-PyYAML-3.13-1.el7.x86_64.rpm
python36-six-1.14.0-3.el7.noarch.rpm
libyaml-0.1.4-11.el7_0.x86_64.rpm
# python-six-1.9.0-2.el7.noarch.rpm # 该模块可以不选择安装哈!
4.在ceph201管理节点添加新增节点的OSD
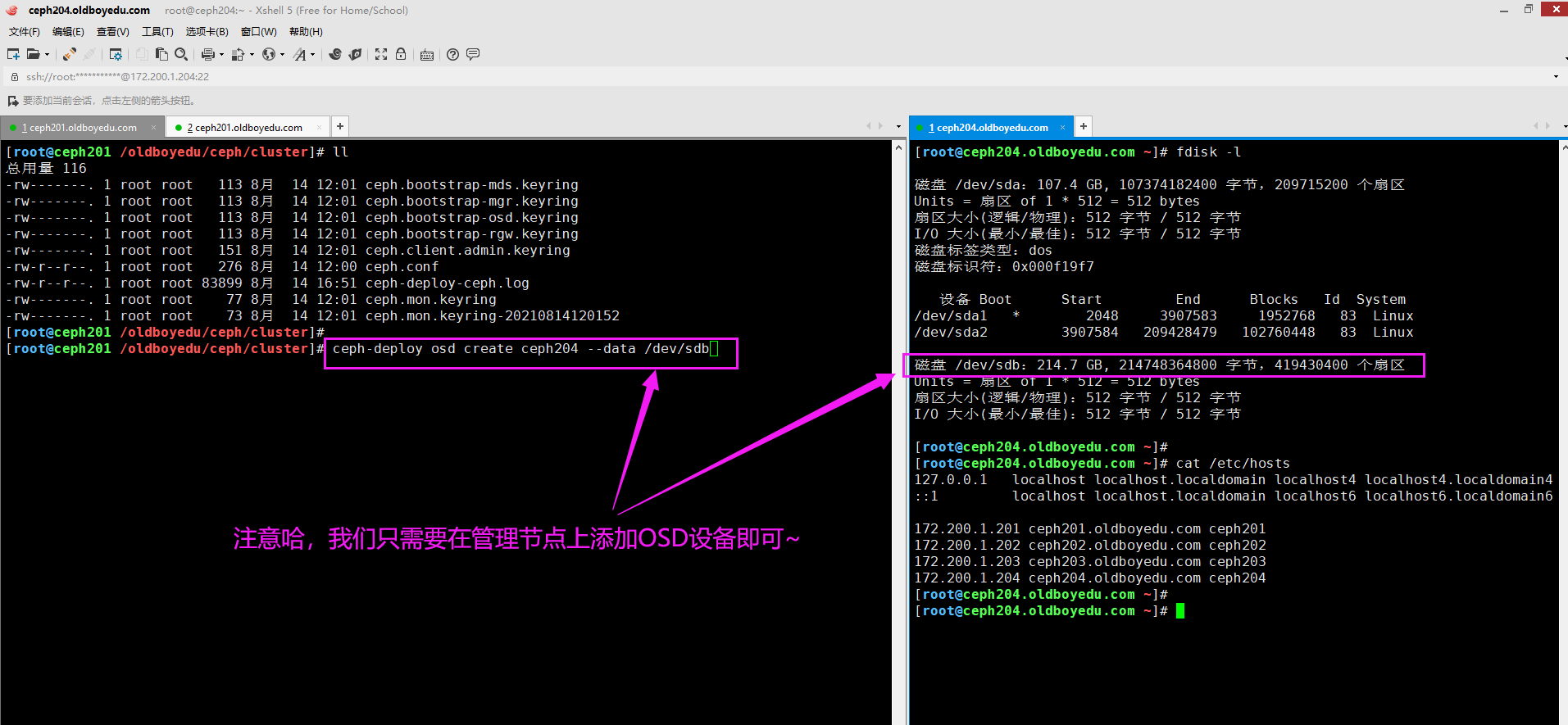
cd /oldboyedu/ceph/cluster
ceph-deploy osd create ceph204 --data /dev/sdb
温馨提示:
如果开启了防火墙功能,则尽管目标节点是正常运行了相关ceph-osd进程,但依旧显式down状态,解决方案就是关闭防火墙并重启ceph-osd进程。(systemctl start ceph-osd@3)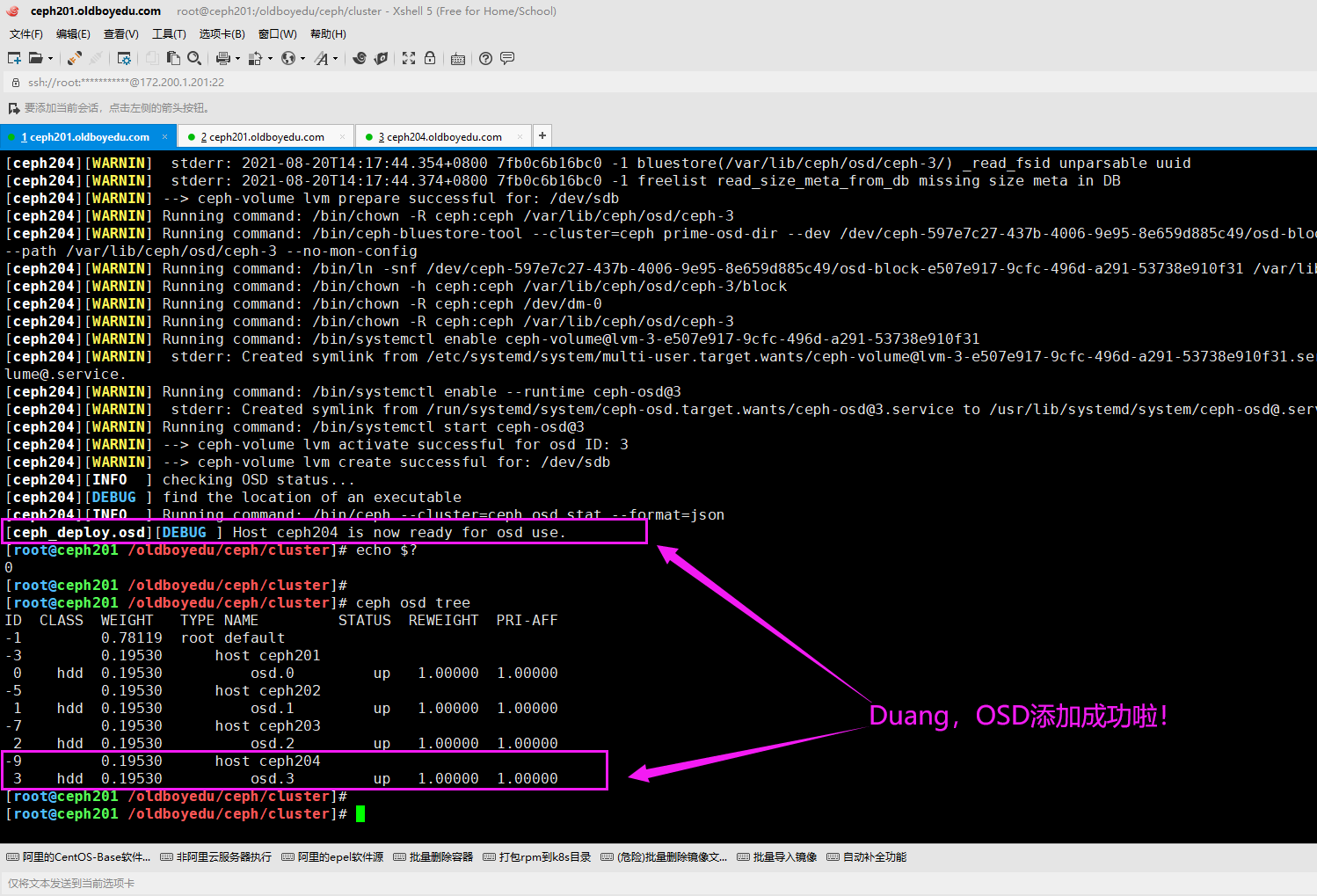
5.添加OSD注意事项
当我们添加OSD时会自动进行数据的负载均衡哟,因此建议大家如果真需要扩容时可以考虑在业务的低谷期进行哟。六.ceph集群缩容osd节点
1.手动模拟故障
如下图所示,我主动将ceph204节点关机了,其OSD的状态为"down"。
温馨提示:
我们可以使用"ceph osd tree"找到不可用的osd在哪个节点。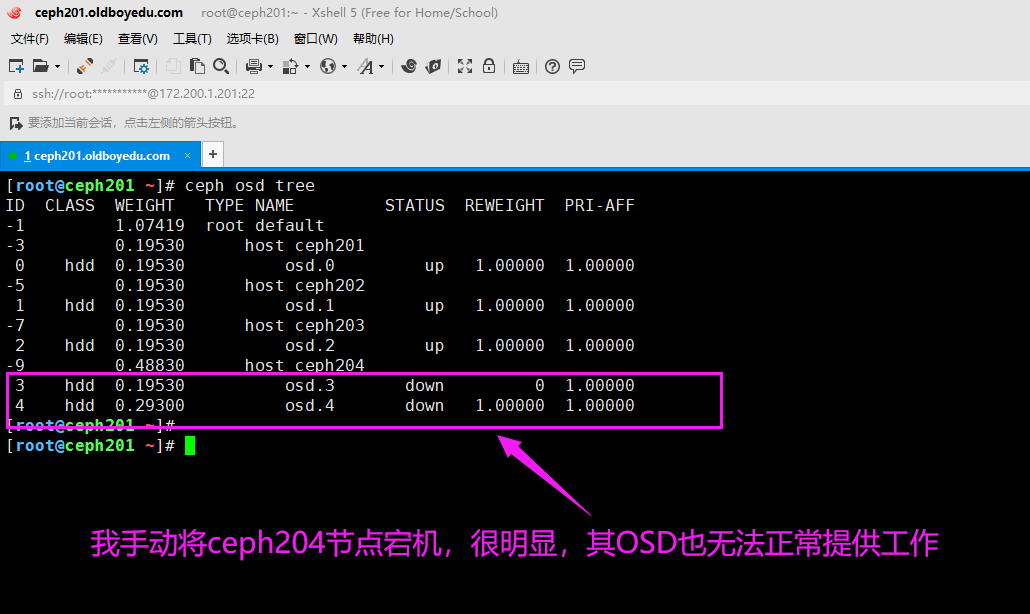
2.找出osd对应的一串编码
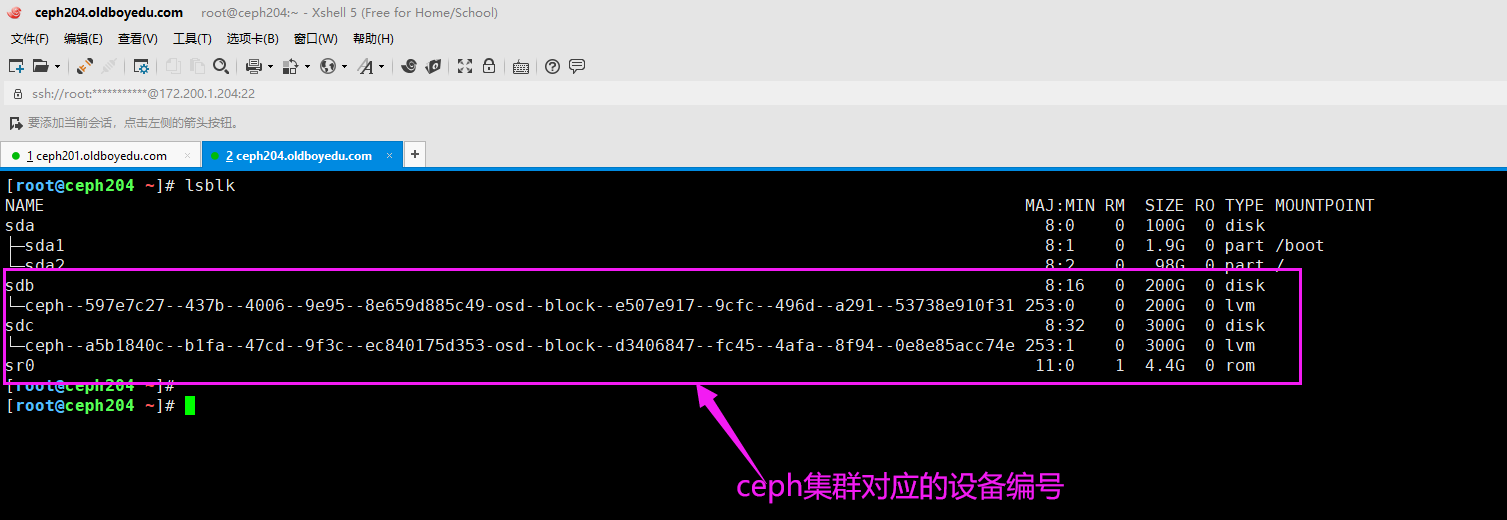
如下图所示,我们可以将"ceph osd dump"的设备对应的编号找出来哟。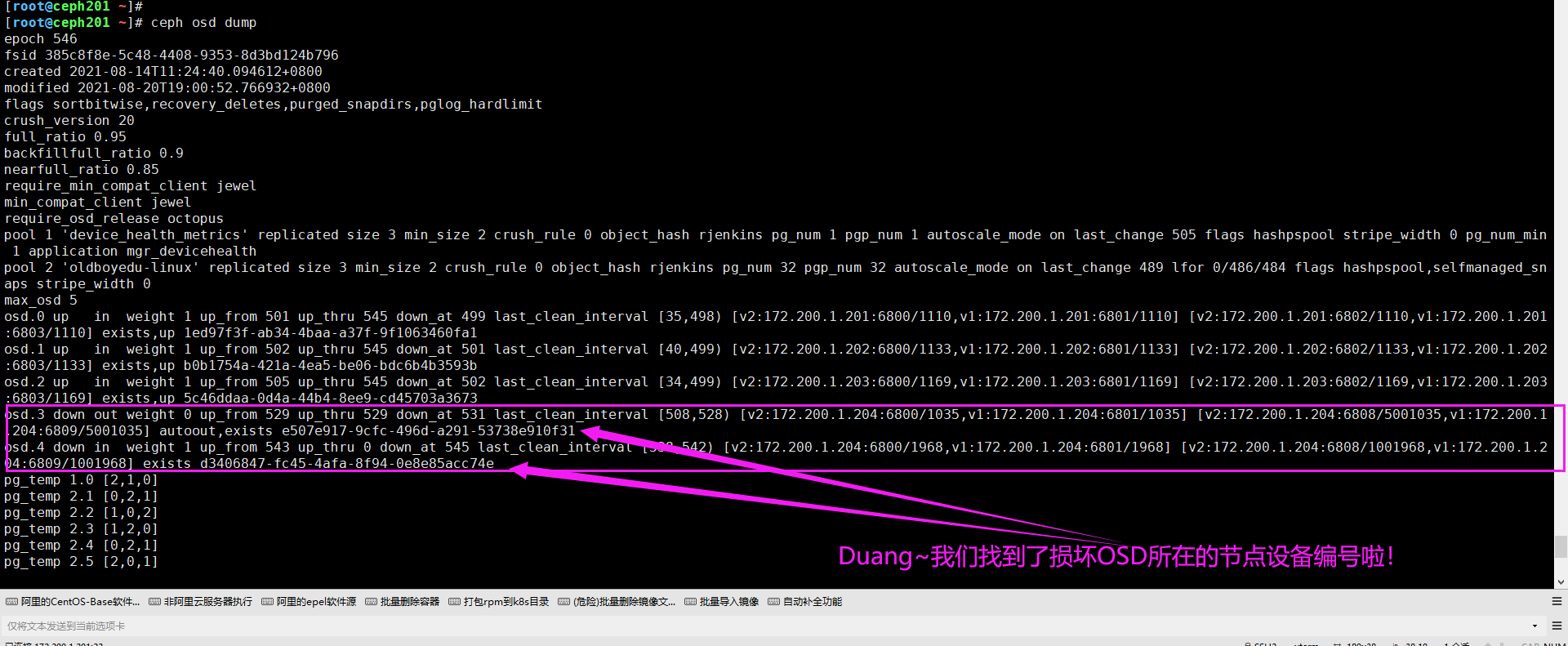
3.把OSD剔除集群
[root@ceph201 ~]# ceph osd out osd.3
marked out osd.3.
[root@ceph201 ~]#
[root@ceph201 ~]# ceph osd out osd.4
marked out osd.4.
[root@ceph201 ~]#
[root@ceph201 ~]# ceph -w # 可以查看ceph的数据迁移情况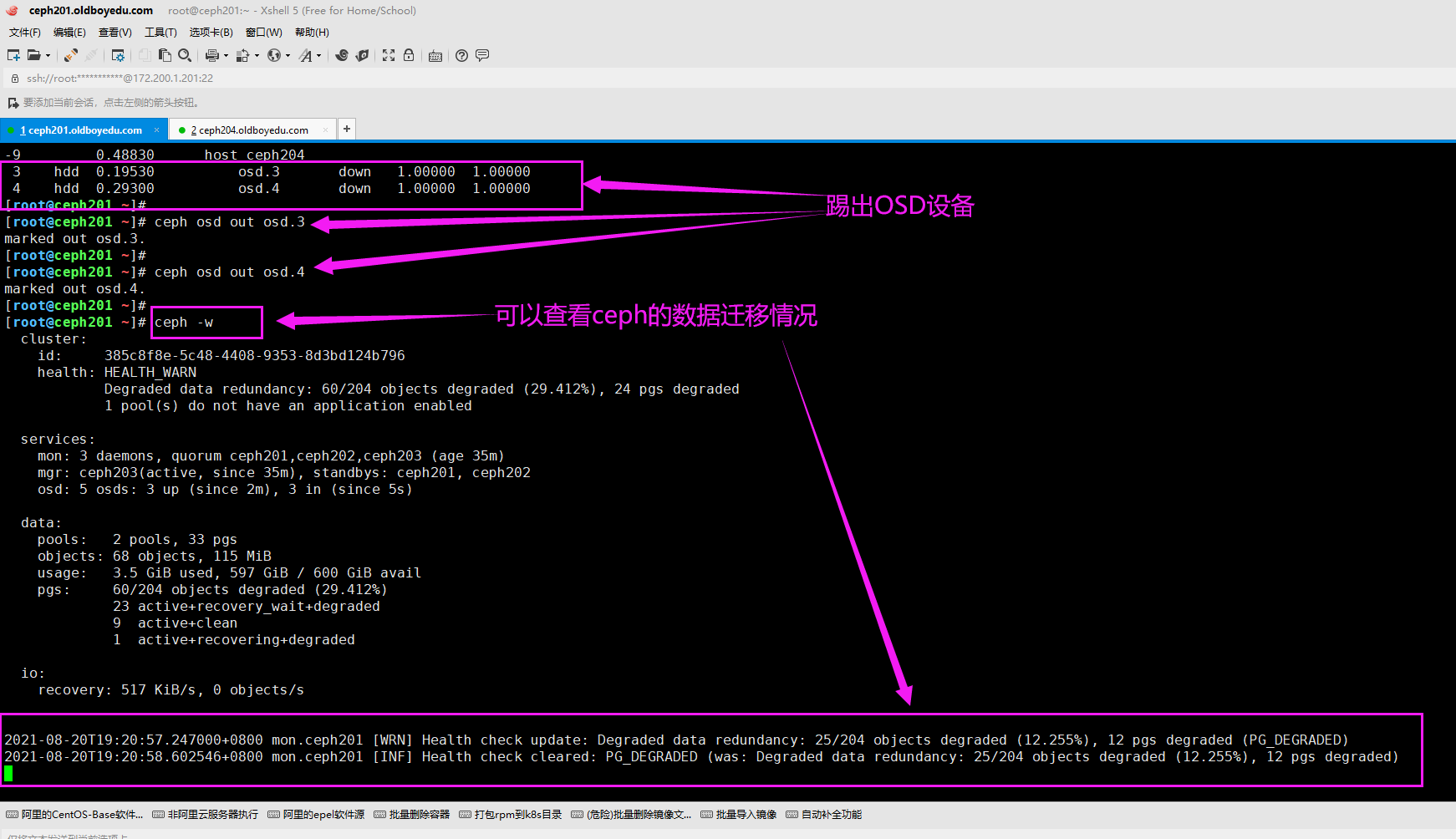
4.在osd宿主机停止osd
[root@ceph204 ~]# systemctl stop ceph-osd@3
[root@ceph204 ~]#
[root@ceph204 ~]# systemctl disable ceph-osd@3
[root@ceph204 ~]#
[root@ceph204 ~]# systemctl disable ceph-osd@4
[root@ceph204 ~]#
[root@ceph204 ~]# systemctl stop ceph-osd@4 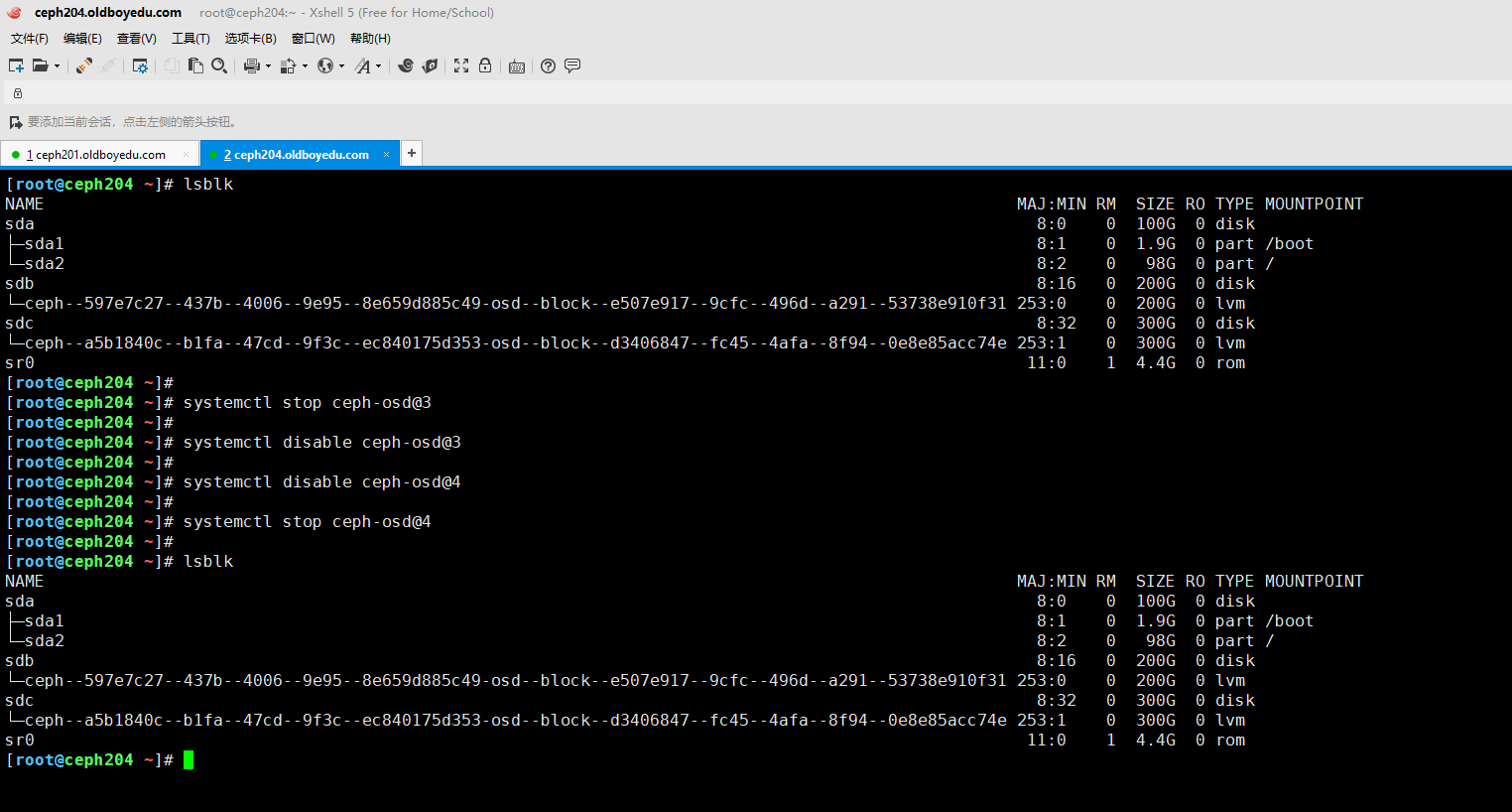
5.在管理节点删除osd
[root@ceph201 ~]# ceph auth del osd.3 # 删除osd认证密钥
updated
[root@ceph201 ~]#
[root@ceph201 ~]# ceph osd rm 3 # 删除 osd
removed osd.3
[root@ceph201 ~]#
[root@ceph201 ~]# ceph auth del osd.4 # 删除osd认证密钥
updated
[root@ceph201 ~]#
[root@ceph201 ~]# ceph osd rm 4 # 删除 osd
removed osd.4
[root@ceph201 ~]# 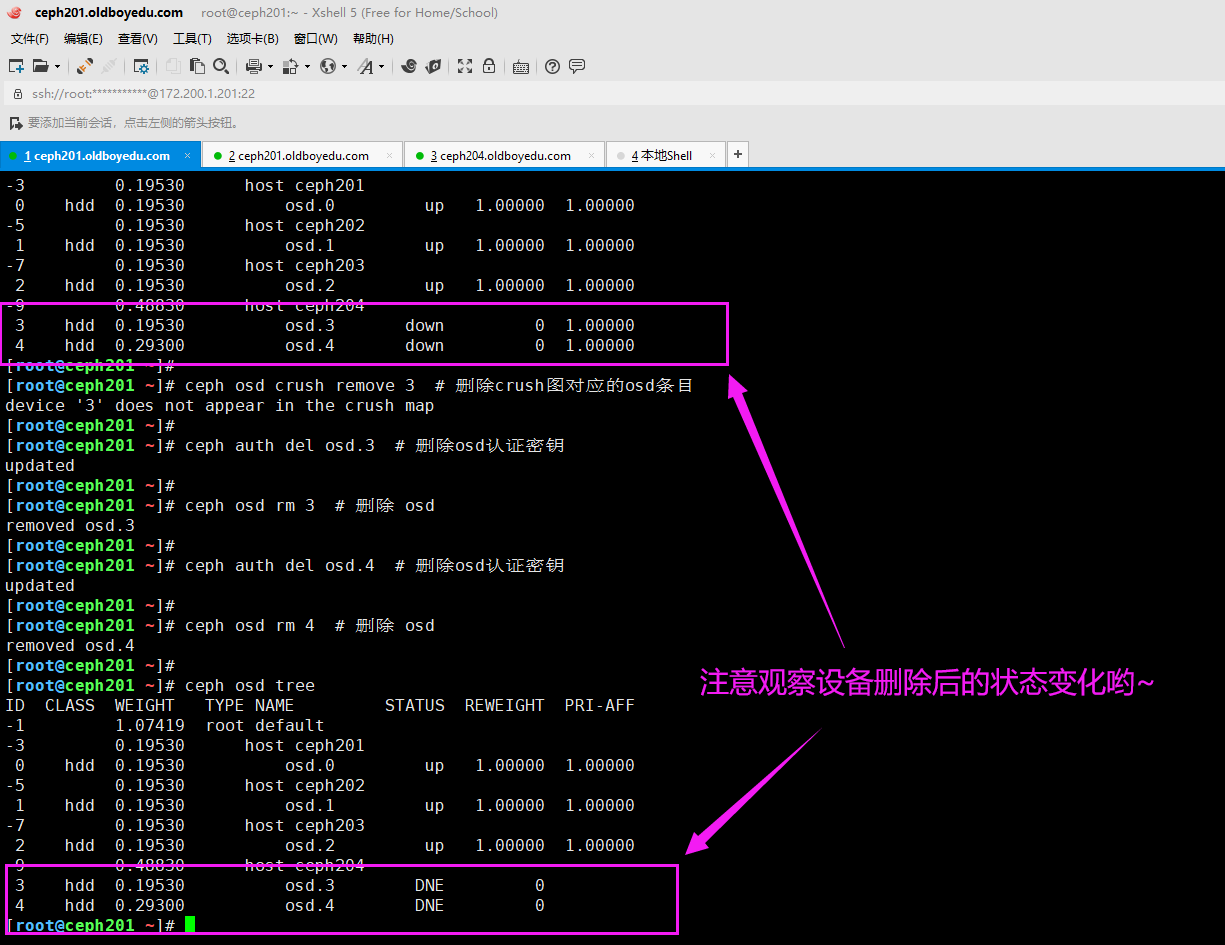
6.解除ceph对磁盘的占用
[root@ceph204 ~]# fuser -k /var/lib/ceph/osd/ceph-3
[root@ceph204 ~]#
[root@ceph204 ~]# fuser -k /var/lib/ceph/osd/ceph-4
[root@ceph204 ~]#
[root@ceph204 ~]# dmsetup status
ceph--a5b1840c--b1fa--47cd--9f3c--ec840175d353-osd--block--d3406847--fc45--4afa--8f94--0e8e85acc74e: 0 629137408 linear
ceph--597e7c27--437b--4006--9e95--8e659d885c49-osd--block--e507e917--9cfc--496d--a291--53738e910f31: 0 419422208 linear
[root@ceph204 ~]#
[root@ceph204 ~]# dmsetup remove ceph--a5b1840c--b1fa--47cd--9f3c--ec840175d353-osd--block--d3406847--fc45--4afa--8f94--0e8e85acc74e
[root@ceph204 ~]#
[root@ceph204 ~]# dmsetup remove ceph--597e7c27--437b--4006--9e95--8e659d885c49-osd--block--e507e917--9cfc--496d--a291--53738e910f31
[root@ceph204 ~]#
温馨提示:
从结果上来看,是否执行"wipefs -a /dev/sdb"和"wipefs -a /dev/sdc"貌似没啥区别哟~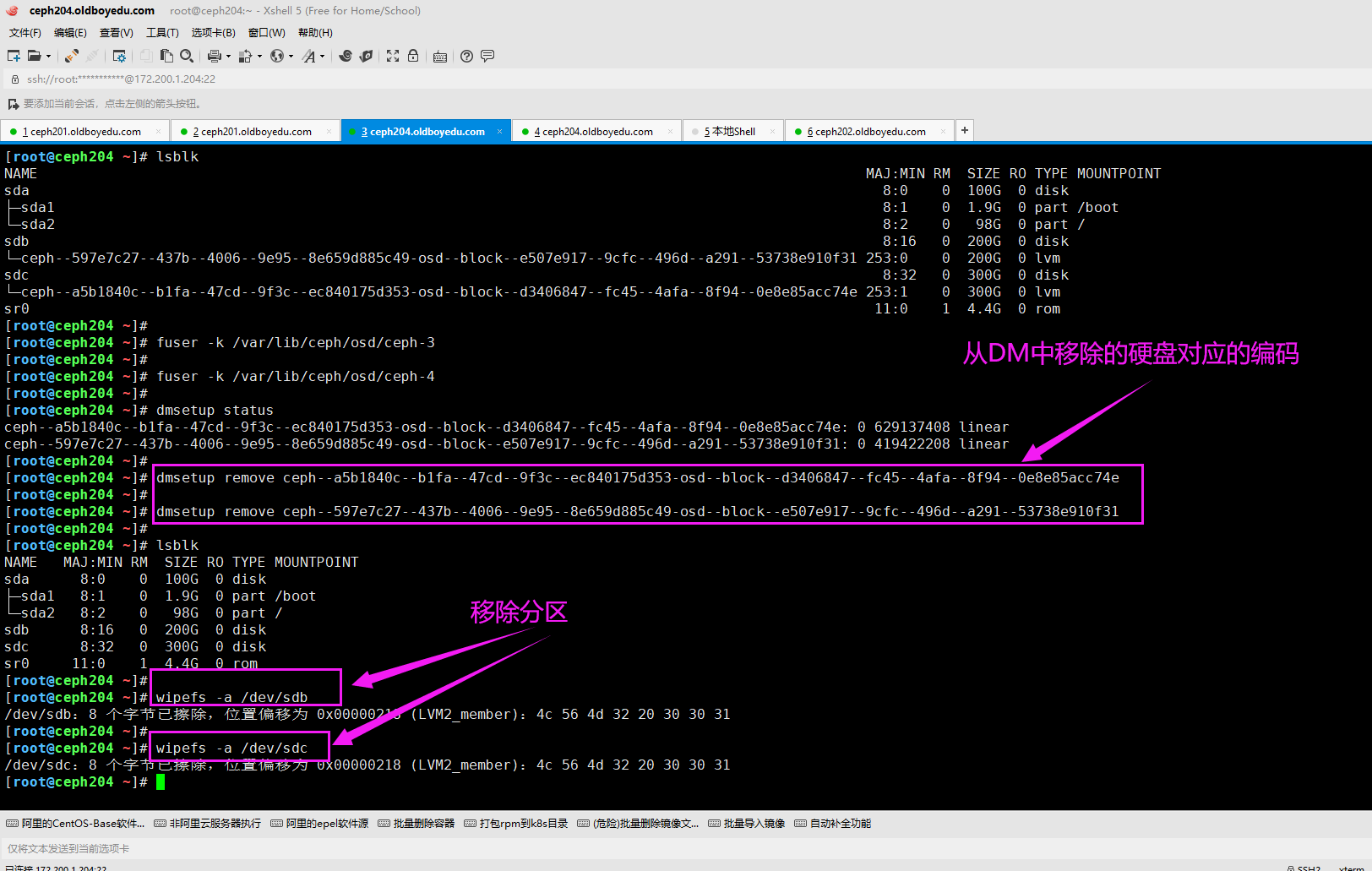
7.清除osd的DNE状态
[root@ceph201 ~]# ceph osd crush remove osd.3
removed item id 3 name 'osd.3' from crush map
[root@ceph201 ~]#
[root@ceph201 ~]# ceph osd crush remove osd.4
removed item id 4 name 'osd.4' from crush map
[root@ceph201 ~]#
温馨提示:
删除osd的时候,如果没有在crush中删除,osd可能会出现DNE的状态,具体解决方法如下图所示。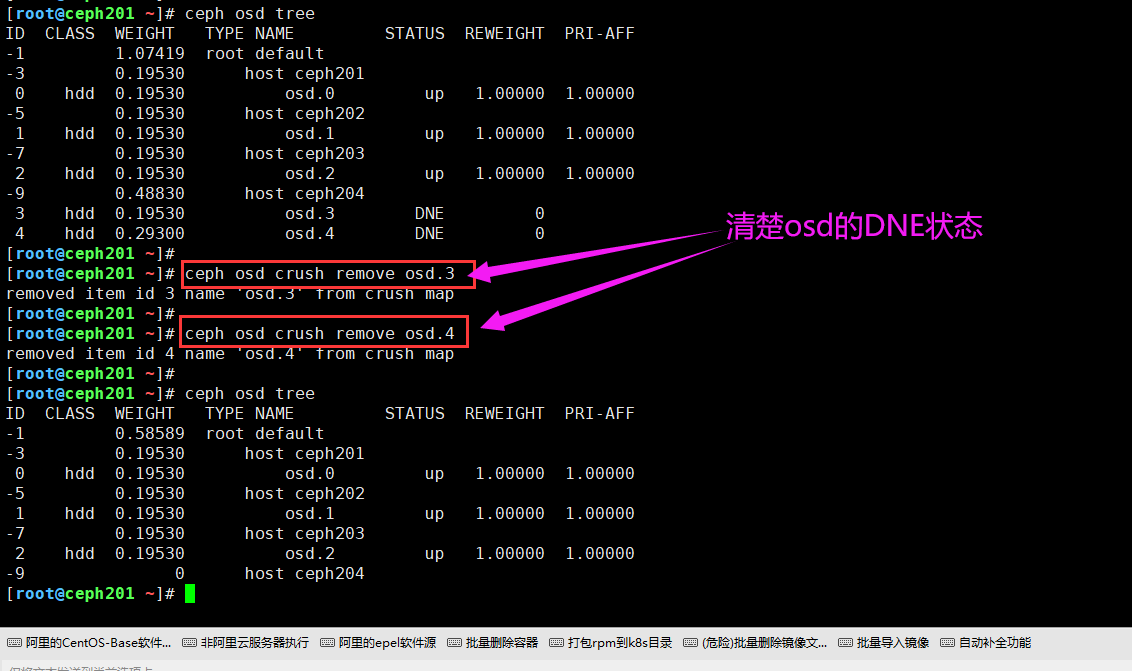
8.清除主机
[root@ceph201 ~]# ceph osd crush remove ceph204
removed item id -9 name 'ceph204' from crush map
[root@ceph201 ~]# 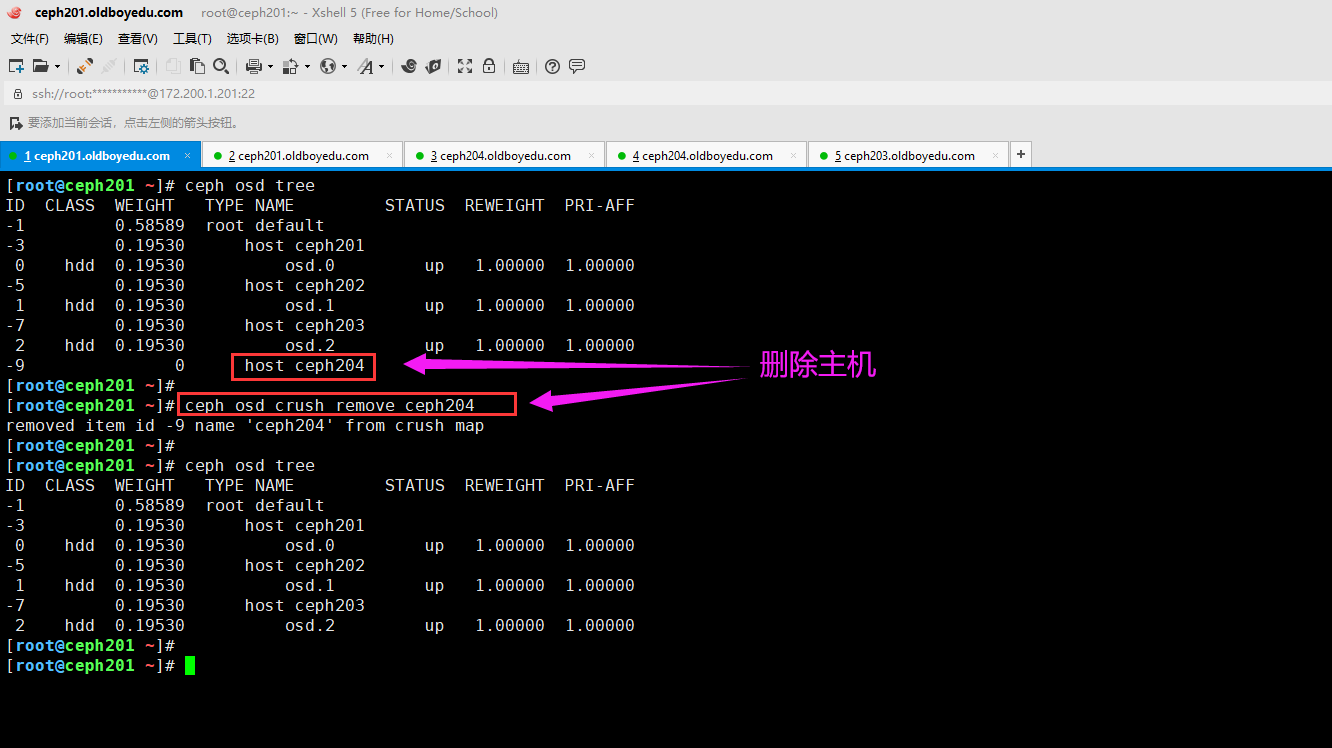
七.使用ceph对接kubernetes
1.在K8S集群中安装ceph的基础包环境
(1)将ceph软件源,epel的软件源拷贝到k8s的master节点
[root@ceph201 /etc/yum.repos.d]# scp oldboyedu-ceph.repo epel.repo 10.0.0.101:`pwd`
(2)master节点开启rpm软件包缓存
[root@k8s101.oldboyedu.com ~]# grep keepcache /etc/yum.conf
keepcache=1
[root@k8s101.oldboyedu.com ~]#
(3)安装ceph的基础包
yum -y install ceph-common
(4)将ceph软件包打包并下发到其它k8s node节点
[root@k8s101.oldboyedu.com ~]# mkdir ceph-common
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t ceph-common/
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# ll ceph-common/ | wc -l
31
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# tar zcf oldboyedu-ceph-common.tar.gz ceph-common
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# scp oldboyedu-ceph-common.tar.gz k8s102.oldboyedu.com:~
(5)其它所有node节点安装ceph软件包
tar xf oldboyedu-ceph.tar.gz && cd ceph-common/ && yum -y localinstall *.rpm
(6)将ceph集群的配置文件推送到k8s所有节点
[root@ceph201 ~]# scp /etc/ceph/ceph.conf 10.0.0.101:/etc/ceph/
[root@ceph201 ~]# scp /etc/ceph/ceph.conf 10.0.0.102:/etc/ceph/
[root@ceph201 ~]# scp /etc/ceph/ceph.conf 10.0.0.103:/etc/ceph/
参考连接:
https://kubernetes.io/docs/concepts/storage/volumes/#rbd
https://github.com/kubernetes/examples/tree/master/volumes/rbd
2.使用Ceph身份验证密钥
(1)如果提供了Ceph身份验证密钥,则该密钥应首先进行base64编码,然后将编码后的字符串放入密钥yaml中。
[root@ceph201 ~]# grep key /etc/ceph/ceph.client.admin.keyring |awk '{printf "%s", $NF}'|base64
QVFCNE54ZGhiZzZvQlJBQTZkS1VJeStheVJVV2FFUHBPMHZVNnc9PQ==
[root@ceph201 ~]#
(2)创建Secret资源,注意替换key的值,要和ceph集群的key保持一致哟,上一步我已经取出来了。
cat > oldboyedu-ceph-secret.yaml <<'EOF'
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
namespace: oldboyedu-tomcat
type: "kubernetes.io/rbd"
data:
key: QVFCNE54ZGhiZzZvQlJBQTZkS1VJeStheVJVV2FFUHBPMHZVNnc9PQ==
EOF
(3)在K8S集群中创建Secret资源,以便于后期Pod使用该资源。
[root@k8s101.oldboyedu.com ~]# vim oldboyedu-ceph-secret.yaml
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# cat oldboyedu-ceph-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
namespace: oldboyedu-tomcat
type: "kubernetes.io/rbd"
data:
key: QVFCNE54ZGhiZzZvQlJBQTZkS1VJeStheVJVV2FFUHBPMHZVNnc9PQ==
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# kubectl apply -f oldboyedu-ceph-secret.yaml
secret "ceph-secret" created
[root@k8s101.oldboyedu.com ~]#
[root@k8s101.oldboyedu.com ~]# kubectl get secret -n oldboyedu-tomcat
NAME TYPE DATA AGE
ceph-secret kubernetes.io/rbd 1 17s
default-token-78x77 kubernetes.io/service-account-token 2 10d
[root@k8s101.oldboyedu.com ~]#
参考连接:
https://github.com/kubernetes/examples/blob/master/volumes/rbd/secret/ceph-secret.yaml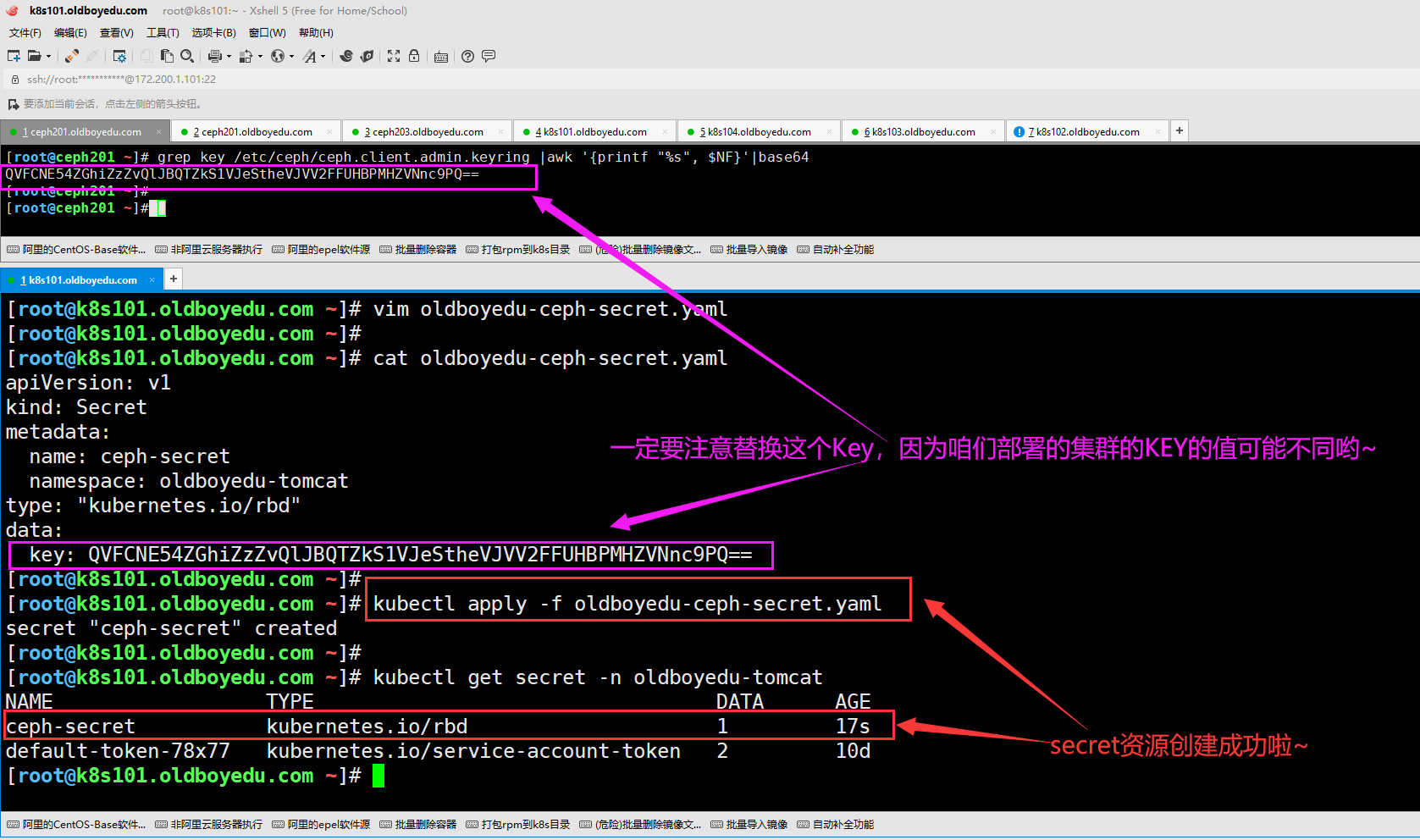
3.创建k8s专用的存储池
[root@ceph201 ~]# ceph osd pool create k8s 128 128
pool 'k8s' created
[root@ceph201 ~]# 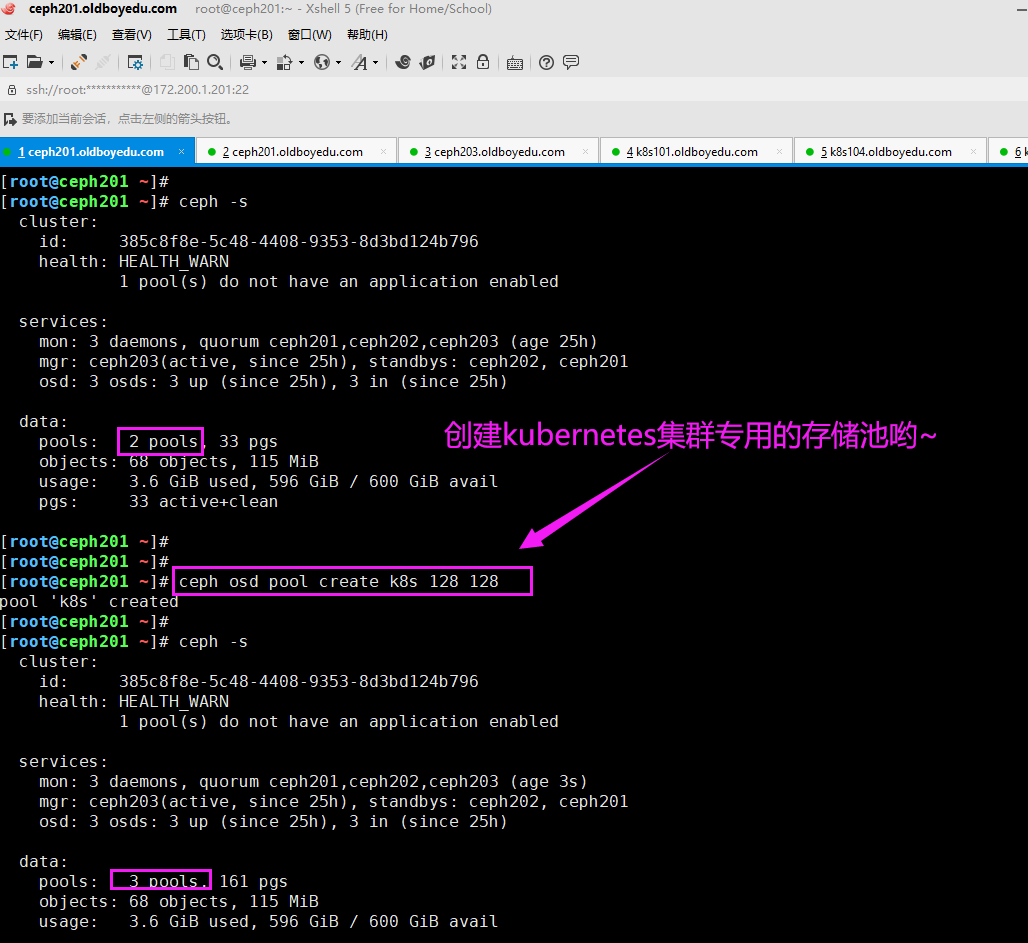
4.创建资源池
(1)创建kubernetes集群常用的资源池
[root@ceph201 ~]# ceph osd pool create k8s 128 128
pool 'k8s' created
[root@ceph201 ~]#
(2)在k8s资源池创建块设备,值得注意的是,我们可以指定该镜像的特性,否则由于内核版本过低而无法挂载哟
[root@ceph201 ~]# rbd create -p k8s --size 1024 --image-feature layering oldboyedu-linux
(3)创建K8S的资源,将MySQL的Pod持久化到ceph集群
[root@k8s101.oldboyedu.com /oldboyedu/k8s-ceph]# cat 02-mysql-deploy.yml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mysql
namespace: oldboyedu-tomcat
spec:
replicas: 1
template:
metadata:
labels:
app: oldboyedu-mysql
spec:
nodeName: k8s104.oldboyedu.com
volumes:
- name: mysql-data
rbd:
# 指定ceph集群的mon节点
monitors:
- '172.200.1.201:6789'
- '172.200.1.202:6789'
- '172.200.1.203:6789'
# 指定存储池
pool: k8s
# 指定rbd镜像名称
image: oldboyedu-linux
# 指定文件系统类型,其会自动帮咱们进行格式化哟~
fsType: xfs
# 是否可读,如果设置为true表示只读权限哟~
readOnly: false
# 指定访问ceph集群的用户
user: admin
# 指定访问集群的密钥资源,这个就是我们自己创建的secret局部资源,请一定要确保Pod和secret在同一个namespace,否则无法访问哟。
secretRef:
name: ceph-secret
# 指定镜像格式,老版本不支持该字段,因此我这里也就先注释了
# imageformat: "2"
# 指定镜像特性,老版本不支持该字段,因此我这里就先注释了
# imagefeatures: "layering"
- name: log
emptyDir: {}
containers:
- name: mysql
# image: k8s101.oldboyedu.com:5000/mysql:5.7
image: oldboyedu-mysql:5.7
# args: ["sh","-x","/start-mysql.sh"]
command: ["sh","-x","/start-mysql.sh"]
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
- name: log
mountPath: /var/log
env:
- name: MYSQL_ROOT_PASSWORD
value: '123456'
[root@k8s101.oldboyedu.com /oldboyedu/k8s-ceph]#
参考连接:
https://github.com/kubernetes/examples/blob/master/volumes/rbd/rbd-with-secret.yaml
温馨提示:
(1)使用"ceph auth ls"指令可以查看身份验证状态的列表。
(2)创建的资源如下图所示,到时候可以直接参考"/oldboyedu/k8s-ceph"目录的yaml。
(3)这个软件包会出现一大堆错误,需要我们手动逐个去排查,对学员说是一次不错的历练。上课要演示完整的排查流程。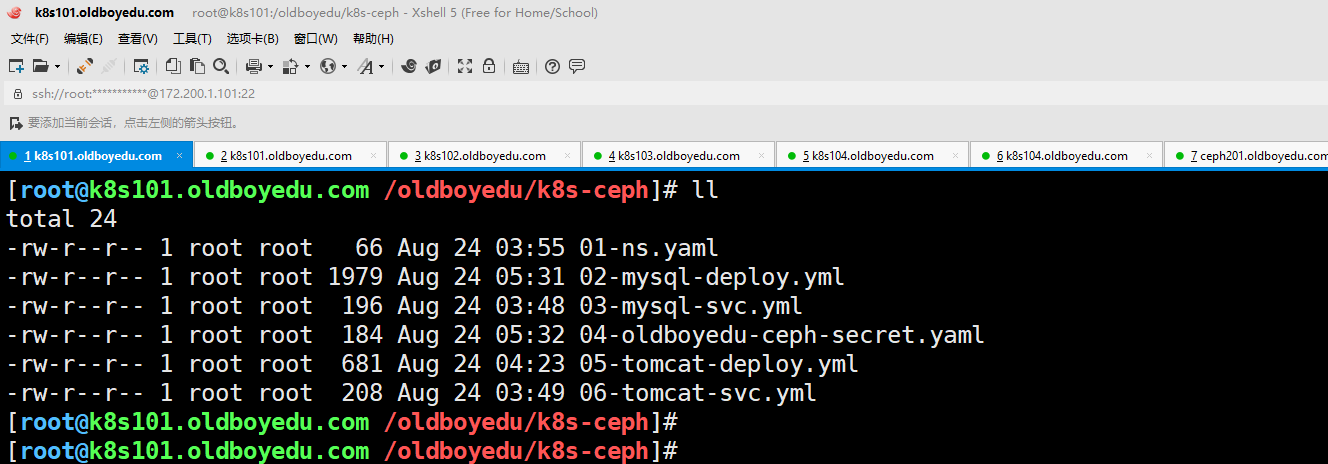
5.数据写入成功
如下图所示,我们成功将数据写入啦。
温馨提示:
(1)在此过程中,我们可能需要各种排错哈! 遇到错误不要慌,我们静下心来解决问题即可。
(2)当删除Pod时,会发现ceph集群的rbd块设备数据也随之被删除了,需要调研一下如何能让数据持久化;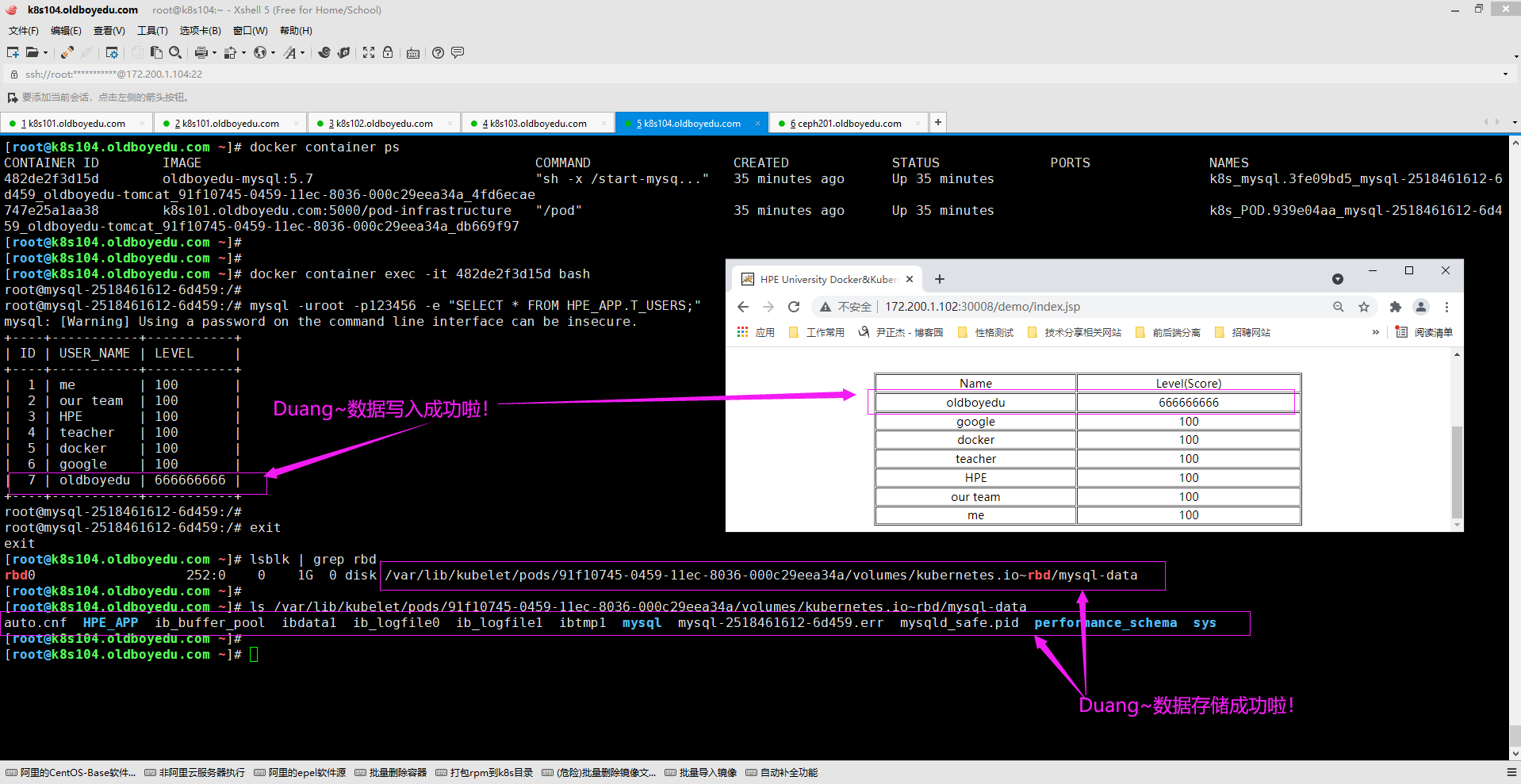
八.扩展案例-tomcat使用ceph集群案例
1.创建PV和PVC
(1)创建PV
cat > 01-ceph-pv.yaml <<'EOF'
apiVersion: v1
kind: PersistentVolume
metadata:
name: oldboyedu-ceph-pv-001
labels:
apps: ceph
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
rbd:
fsType: xfs
image: oldboyedu-linux77
pool: oldboyedu-k8s
secretRef:
name: ceph-secret
user: admin
readOnly: false
monitors:
- 10.0.0.111:6789
- 10.0.0.112:6789
- 10.0.0.113:6789
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: oldboyedu-ceph-pv-002
labels:
apps: ceph
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
rbd:
fsType: xfs
image: oldboyedu-linux78
pool: oldboyedu-k8s
secretRef:
name: ceph-secret
user: admin
readOnly: false
monitors:
- 10.0.0.111:6789
- 10.0.0.112:6789
- 10.0.0.113:6789
EOF
(5)创建PVC
cat > 02-ceph-pvc.yaml <<'EOF'
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: oldboyedu-ceph-pvc-001
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 25Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: oldboyedu-ceph-pvc-002
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 35Gi
2.tomcat应用PVC
(1)创建MySQL服务
cat >03-deploy-mysql.yaml <<'EOF'
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: oldboyedu-mysql
spec:
replicas: 1
template:
metadata:
labels:
app: oldboyedu-tomcat-mysql
spec:
volumes:
- name: oldboyedu-pvc
persistentVolumeClaim:
claimName: oldboyedu-ceph-pvc-002
readOnly: false
containers:
- name: mysql
image: k8s101.oldboyedu.com:5000/mysql:5.7
volumeMounts:
- name: oldboyedu-pvc
mountPath: /var/lib/mysql
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
livenessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 10
periodSeconds: 3
EOF
(2)创建MySQL的SVC
cat > 04-deploy-mysql-svc.yaml <<'EOF'
kind: Service
apiVersion: v1
metadata:
name: oldboyedu-mysql-svc
spec:
type: ClusterIP
clusterIP: 10.254.100.136
ports:
- port: 13306
protocol: TCP
targetPort: 3306
selector:
app: oldboyedu-tomcat-mysql
EOF
(4)部署tomcat
cat > 05-deploy-tomcat.yaml <<'EOF'
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: oldboyedu-tomcat
spec:
replicas: 1
template:
metadata:
labels:
app: oldboyedu-tomcat-app
spec:
volumes:
- name: oldboyedu-pvc
persistentVolumeClaim:
claimName: oldboyedu-ceph-pvc-001
readOnly: false
containers:
- name: myweb
image: k8s101.oldboyedu.com:5000/tomcat-app:v1
volumeMounts:
- name: oldboyedu-pvc
mountPath: /usr/local/tomcat
# mountPath: /oldboyedu-tomcat-2021
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: oldboyedu-mysql-svc
- name: MYSQL_SERVICE_PORT
value: '13306'
livenessProbe: # 健康检查,如果有问题就会重启容器!
httpGet:
path: /
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
#readinessProbe: # 可用性检查,如果有问题,就会从SVC的EP列表中移除.
# httpGet:
# path: /oldboyedu.html
# port: 8080
# initialDelaySeconds: 3
# periodSeconds: 3
EOF
(6)创建tomcat的SVC
cat > 04-deploy-tomcat-svc.yaml <<EOF
kind: Service
apiVersion: v1
metadata:
name: oldboyedu-tomcat-svc
spec:
type: NodePort
ports:
- port: 7777
protocol: TCP
targetPort: 8080
nodePort: 30001
selector:
app: oldboyedu-tomcat-app
EOF
3.防坑小技巧
温馨提示:
在启动容器时,tomcat可能无法正常启动哟,原因是被挂载点没有tomcat的数据目录,因此需要手动将原始数据拷贝过去哟..九.小彩蛋
1.优化PS1变量
vi /etc/profile.d/ps1.sh
i_set_prompt () {
#see: http://misc.flogisoft.com/bash/tip_colors_and_formatting
#Reset \e[0m
## Formatting:
#Bold \e[1m
#Dim \e[2m
#Underlined \e[4m
## 8/16 Colors: 9X 4X 10X
#Default fg \e[39m Default bg
#Black \e[30m Dark gray bg Black bg Dark gray
#Red \e[31m Light bg bg Light
#Green \e[32m Light bg bg Light
#Yellow \e[33m Light bg bg Light
#Blue \e[34m Light bg bg Light
#Magenta \e[35m Light bg bg Light
#Cyan \e[36m Light bg bg Light
#Light gray \e[37m White bg bg White
_last_exit_code=$? # Must come first!
C_EC='\[\e[1;37m\]'$(printf '%3s' ${_last_exit_code})'\[\e[0m\]'
#todo: set encoding to UTF-8 !
FancyX='\342\234\227' # ✗ ✘
Checkmark='\342\234\223' # ✓
C_Fail='\[\e[1;31m\]'${FancyX}'\[\e[0m\]'
C_Ok='\[\e[32m\]'${Checkmark}'\[\e[0m\]'
C_Time='\[\e[2;37m\]''\t''\[\e[0m\]'
C_NormalUser='\[\e[2;33m\]''\u''\[\e[0m\]'
C_RootUser='\[\e[1;35m\]''\u''\[\e[0m\]'
if [ $(uname -s) == "Darwin" ]; then
_ip_addr=$(ipconfig getifaddr $(netstat -nr | awk '{ if ($1 ~/default/) { print $6} }'))
elif [ $(uname -s) == "Linux" ]; then
# may print $(NF-2)
#_ip_addr=$(ip route | awk '/ src / {print $NF}' | head -1 )
_ip_addr=$(ip route | grep -oP '(?<=src )[0-9.]+' | tail -1 )
fi
C_Host='\[\e[1;33m\]'$(hostname -A | awk '{print $1}')'\[\e[0m\]','\[\e[4;32m\]'${_ip_addr:-\h}'\[\e[0m\]'
C_Pwd='\[\e[36m\]''\w''\[\e[0m\]'
C_Marker='\[\e[1;37m\]''\$''\[\e[0m\]'
git diff --exit-code --quiet HEAD >/dev/null 2>&1
_git_diff_exit_code=$?
if [ ${_git_diff_exit_code} -eq 1 ]; then
C_Marker='\[\e[101m\]'*'\[\e[0m\]'" ${C_Marker}"
elif [ ${_git_diff_exit_code} -eq 0 ]; then
C_Marker='\[\e[102m\]'='\[\e[0m\]'" ${C_Marker}"
fi
# Add a bright white exit status for the last command
PS1="$C_EC "
# If it was successful, print a green check mark.
# Otherwise, print a red X.
if [[ ${_last_exit_code} -eq 0 ]]; then
PS1+="$C_Ok "
else
PS1+="$C_Fail "
fi
# print HH:ii:ss
PS1+="$C_Time "
# If root, just print the host in red. Otherwise,
# print the current user and host in green.
if [[ $EUID -eq 0 ]]; then
PS1+="${C_RootUser}@${C_Host}:"
else
PS1+="${C_NormalUser}@${C_Host}:"
fi
# Print the working directory and prompt marker
PS1+="$C_Pwd $C_Marker "
}
PROMPT_COMMAND='_set_prompt'
2.登陆提示案例1
rm -f /etc/motd
vi /etc/motd
i
_oo0oo_
088888880
88" . "88
(| -_- |)
0\ = /0
___/'---'\___
.' \\| |// '.
/ \\||| : |||// \
/_ ||||| -:- |||||- \
| | \\\ - /// | |
| \_| ''\---/'' |_/ |
\ .-\__ '-' __/-. /
___'. .' /--.--\ '. .'___
."" '< '.___\_<|>_/___.' >' "".
| | : '- \'.;'\ _ /';.'/ - ' : | |
\ \ '_. \_ __\ /__ _/ .-' / /
====='-.____'.___ \_____/___.-'____.-'=====
'=---='
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
佛祖保佑 oldboyedu-linux76 永不死机
3.登陆提示案例2
rm -f /etc/motd
vi /etc/motd
i .=""=.
/ _ _ \
| d b |
\ /\ /
,/'-=\/=-'\,
/ / \ \
| / \ |
\/ \ / \/
'. .'
_|`~~`|_
/|\ /|\
4.登陆提示案例3
rm -f /etc/motd
vi /etc/motd
i
┌───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┬───┐ ┌───┬───┬───┐ ┌───────────────┐
│Esc│ │ F1│ F2│ F3│ F4│ │ F5│ F6│ F7│ F8│ │ F9│F10│F11│F12│ │P/S│S L│P/B│ │Oldboyedu Linux│
└───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┴───┘ └───┴───┴───┘ └───────────────┘
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───────┐ ┌───┬───┬───┐ ┌───┬───┬───┬───┐
│~ `│! 1│@ 2│# 3│$ 4│% 5│^ 6│& 7│* 8│( 9│) 0│_ -│+ =│ BacSp │ │Ins│Hom│PUp│ │N L│ / │ * │ - │
├───┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─────┤ ├───┼───┼───┤ ├───┼───┼───┼───┤
│ Tab │ Q │ W │ E │ R │ T │ Y │ U │ I │ O │ P │{ [│} ]│ | \ │ │Del│End│PDn│ │ 7 │ 8 │ 9 │ │
├─────┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴┬──┴─────┤ └───┴───┴───┘ ├───┼───┼───┤ + │
│ Caps │ A │ S │ D │ F │ G │ H │ J │ K │ L │: ;│" '│ Enter │ │ 4 │ 5 │ 6 │ │
├──────┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴─┬─┴────────┤ ┌───┐ ├───┼───┼───┼───┤
│ Shift │ Z │ X │ C │ V │ B │ N │ M │< ,│> .│? /│ Shift │ │ ↑ │ │ 1 │ 2 │ 3 │ │
├─────┬──┴─┬─┴──┬┴───┴───┴───┴───┴───┴──┬┴───┼───┴┬────┬────┤ ┌───┼───┼───┐ ├───┴───┼───┤ E││
│ Ctrl│ │Alt │ Space │ Alt│ │ │Ctrl│ │ ← │ ↓ │ → │ │ 0 │ . │←─┘│
└─────┴────┴────┴───────────────────────┴────┴────┴────┴────┘ └───┴───┴───┘ └───────┴───┴───┘
5.登陆提示案例4
rm -f /etc/motd
vi /etc/motd
i
oldboyedu~linux76~biubui~
へ /|
/\7 ∠_/
/ │ / /
│ Z _,< / /`ヽ
│ ヽ / 〉
Y ` / /
● ● 〈 /
() へ | \〈
> _ ィ │ //
/ へ / <| \\
ヽ_ (_/ │//
7 |/
>―r ̄ ̄`―_
6.虚拟机添加硬盘不重启识别
for i in `seq 0 2`; do echo "- - -" > /sys/class/scsi_host/host${i}/scan;done十.可能会遇到的错误
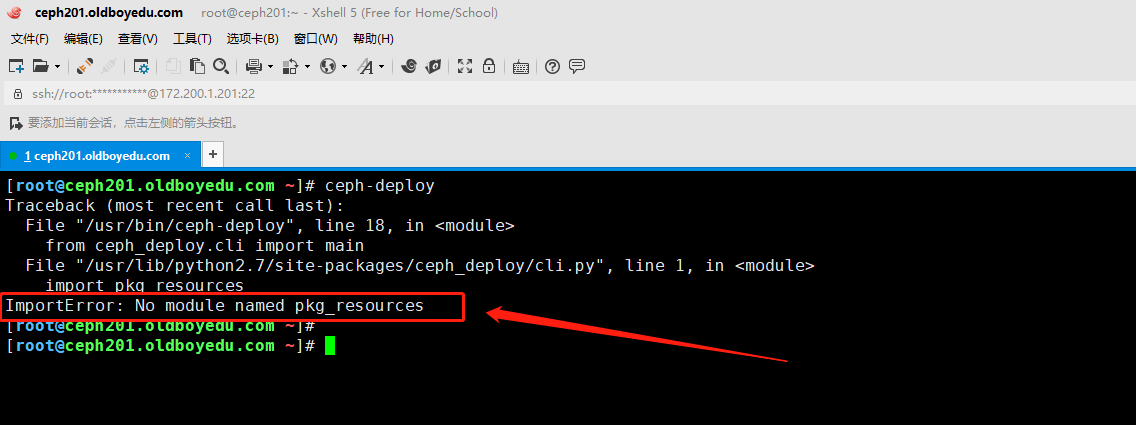
1.ImportError: No module named pkg_resources
问题原因:
缺少"pkg_resources"模块,实际上测试安装"distribute"软件包即可。
解决方案:
yum -y install gcc python-setuptools python-devel
wget https://pypi.python.org/packages/source/d/distribute/distribute-0.7.3.zip --no-check-certificate
unzip distribute-0.7.3.zip
cd distribute-0.7.3
python setup.py install
2.[ceph_deploy.mon][ERROR ] connecting to host: ceph203 resulted in errors: HostNotFound ceph203
报错原因:
如下图所示,是主机未发现报错的异常哟。
解决方案:
配置相应主机的名称解析即可。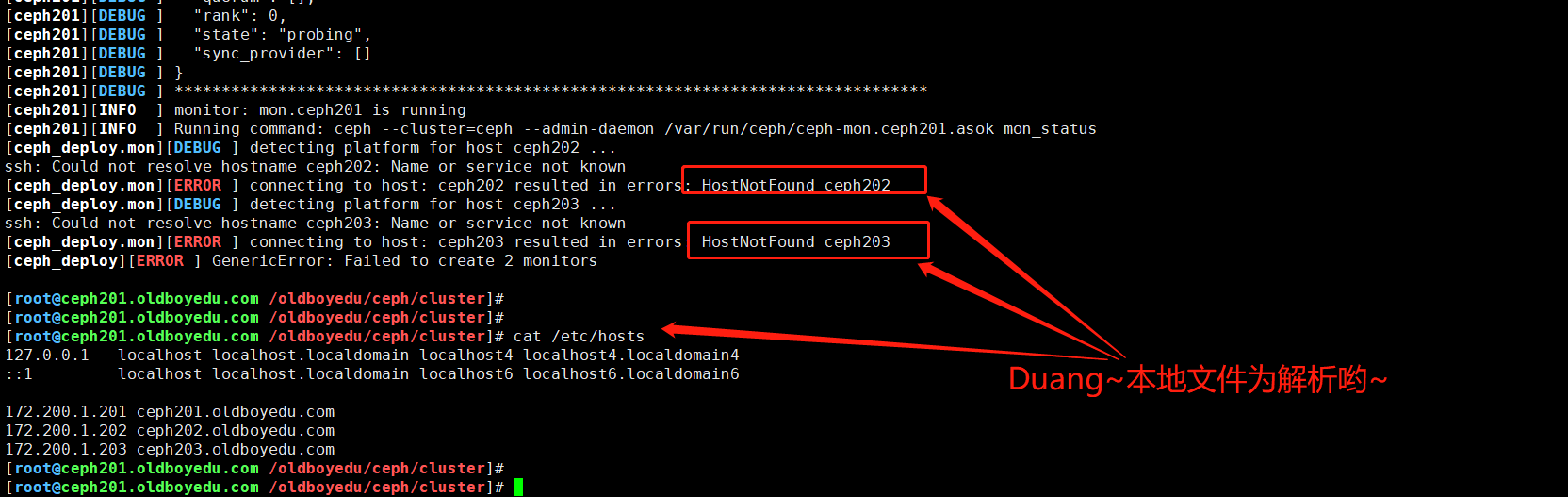
3.[ceph_deploy.mon][ERROR ] RuntimeError: config file /etc/ceph/ceph.conf exists with different content; use --overwrite-conf to overwrite
报错原因:
"/etc/ceph/ceph.conf"这个配置文件已存在啦。
解决方案:
删除所有的节点的配置文件。
温馨提示:
这个报错是由于你重复安装mon组件导致的哟~如果你明确知道你要重复安装mon组件,否则请访问上述解决方案。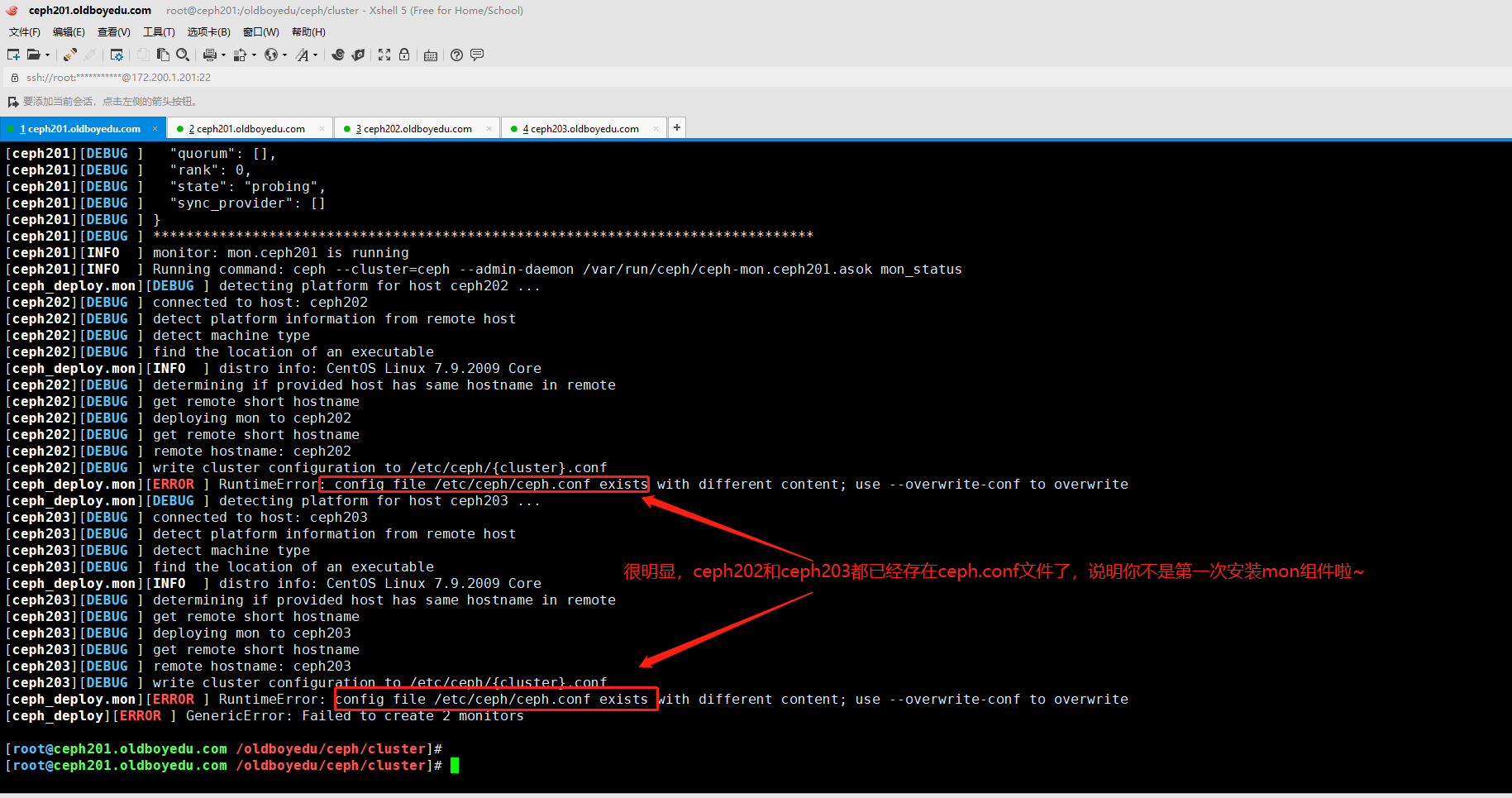
4.[ceph_deploy.mon][WARNIN] waiting 5 seconds before retrying
报错原因:
连接其他主机的mon组件时失败。
解决方案:
(1)请检查主机名是否和mon节点名称一致,请不要使用FQDN(例如"ceph201.oldboyedu.com"),请设置为主机名("ceph201");
(2)检查各个主机的"ceph-mon"进程是否存活;
(3)关闭并禁用防火墙
systemctl stop firewalld && systemctl disable firewalld
(4)各个mon节点删除相关文件并重新安装ceph-mon组件
pkill ceph-mon || rm -f /etc/ceph/ceph.conf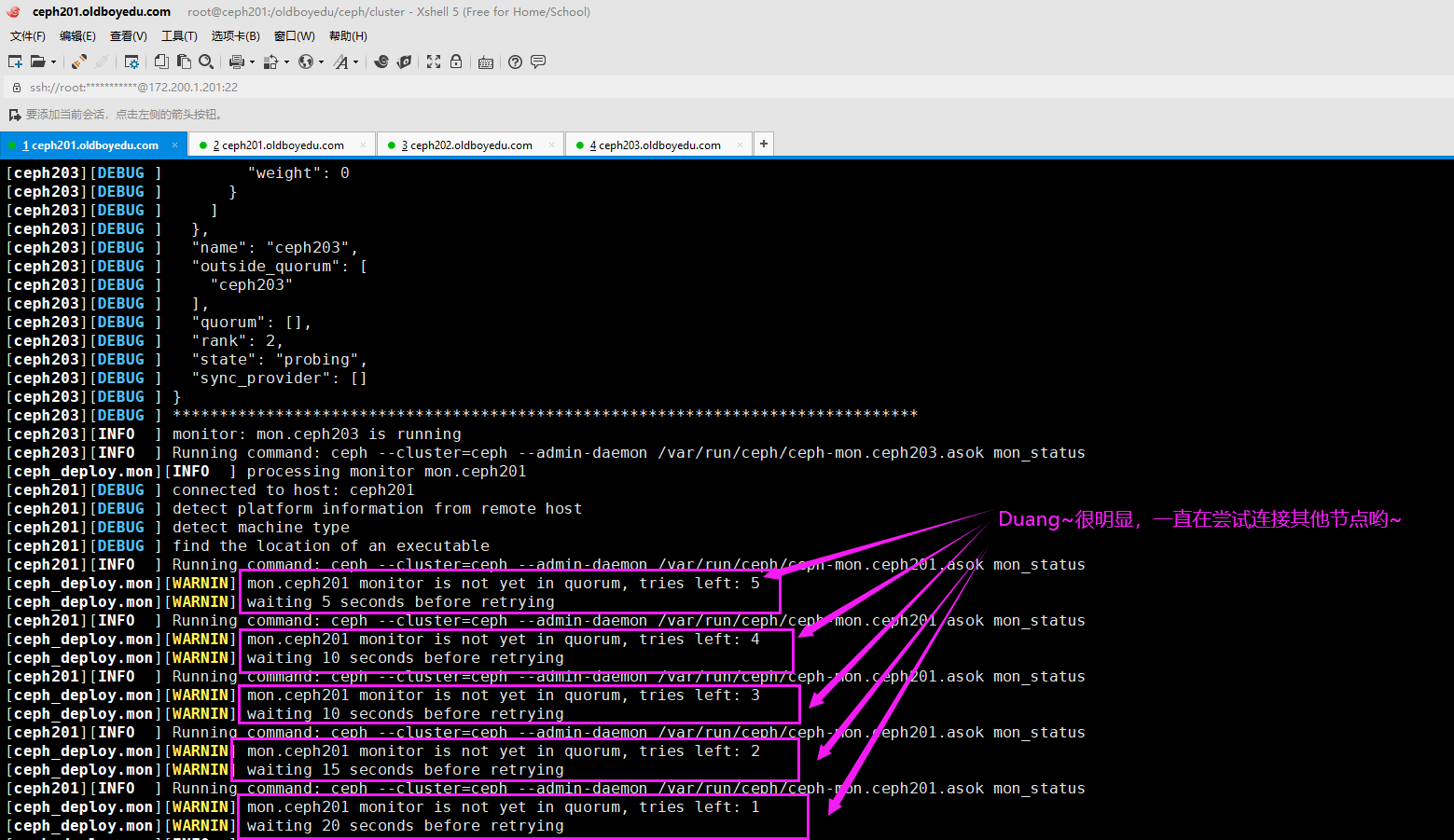
5.[ceph_deploy.mon][ERROR ] OSError: [Errno 2] No such file or directory: '/etc/ceph/tmpN0ndWN'
报错原因:
报错说是指定文件'/etc/ceph/tmpN0ndWN'不存在,但该文件是会自动创建的,我们需要验证其父级目录是否存在。
解决方案:
我们需要手动创建父级路径即可,比如"mkdir /etc/ceph"。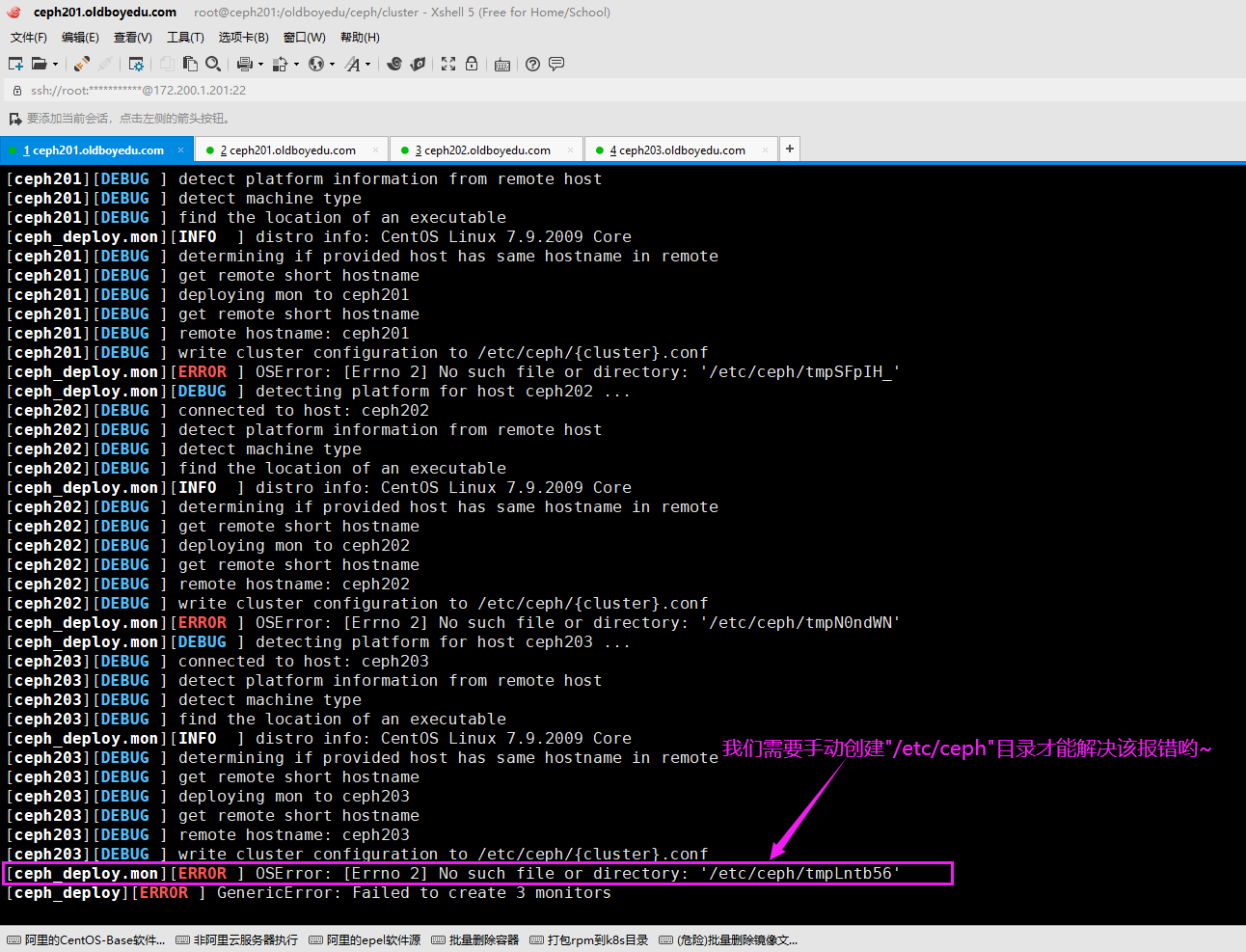
6.[errno 2] RADOS object not found (error connecting to the cluster)
错误原因:
如下图所示,说明当前节点没有被授权管理集群状态。
解决方案:
请参考"ceph-deploy admin -h"的帮助信息即可添加当前节点成为管理集群的节点哟。
例如:"ceph-deploy admin ceph201 ceph202 ceph203",这些主机需要在本地hosts文件做相应的解析即可。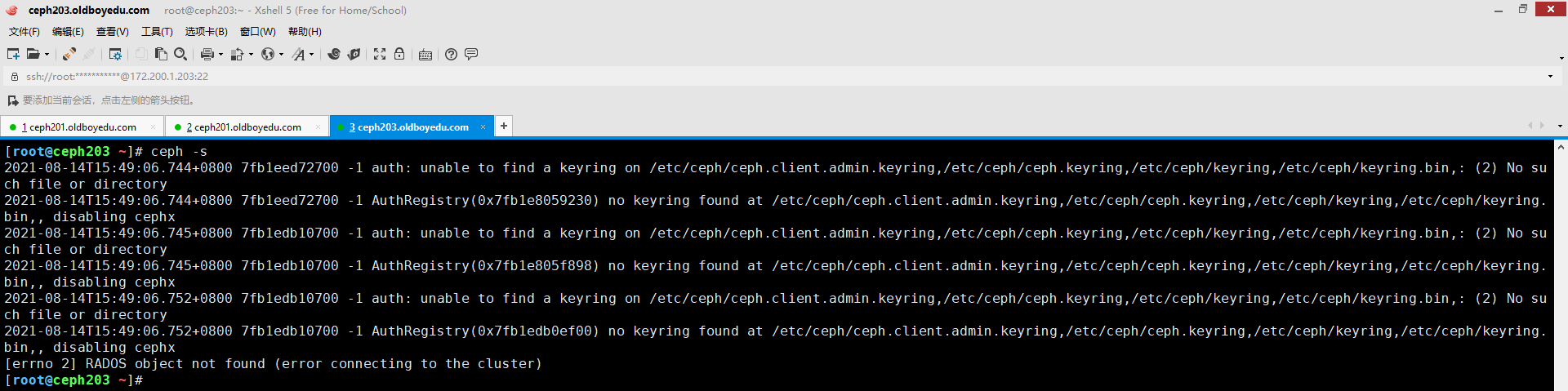
7.Module 'restful' has failed dependency: No module named 'pecan'
报错原因:
如下图所示,缺少"pecan"模块,因此我们手动安装即可。
解决方案:(需要在集群的所有节点操作哟~)
pip3 install pecan werkzeug
reboot # 需要重启才能生效哟,放心大胆的重启,因为使用ceph-deploy部署的服务默认就是开机自启动的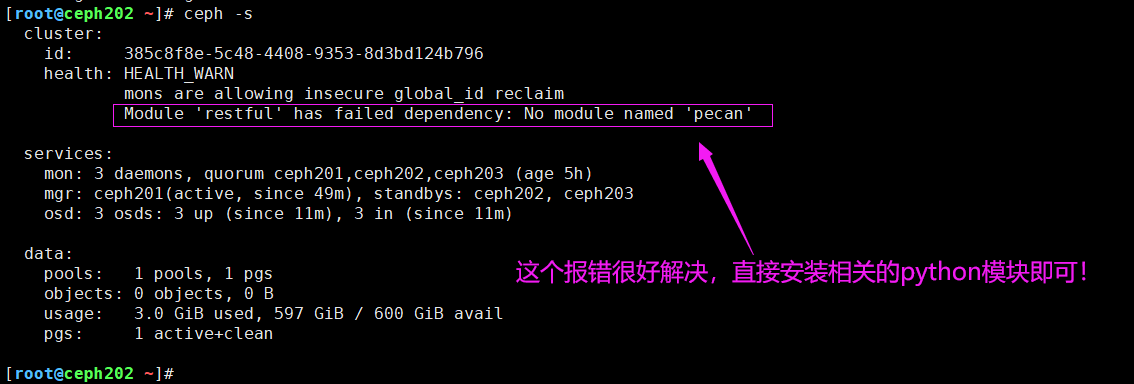
8.mons are allowing insecure global_id reclaim
报错原因:
如下图所示,在较新的版本,默认是开启了不安全模式,我们可以禁用不安全模式,从而解决该告警。
解决方案:(需要在集群的所有节点操作哟~)
ceph config set mon auth_allow_insecure_global_id_reclaim false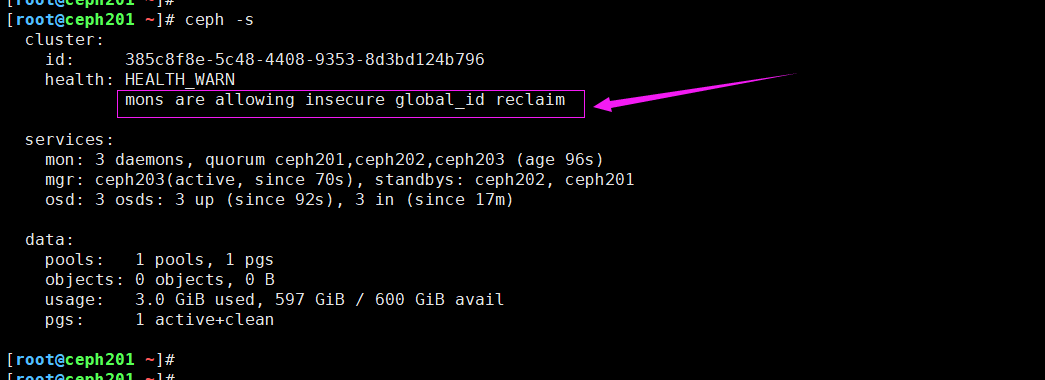
9.RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable oldboyedu-linux/linux76 object-map fast-diff deep-flatten"
报错原因:
Linux内核的版本过低,无法支持"object-map","fast-diff","deep-flatten"这些特性哟。
解决方案:
参考1:
升级Linux内核版本。
参考2:
更换Linux内核较新的系统,例如ubuntu。
参考3:
禁用"object-map","fast-diff","deep-flatten"这些特性。
执行"rbd feature disable oldboyedu-linux/linux76 object-map fast-diff deep-flatten"命令即可禁用哟~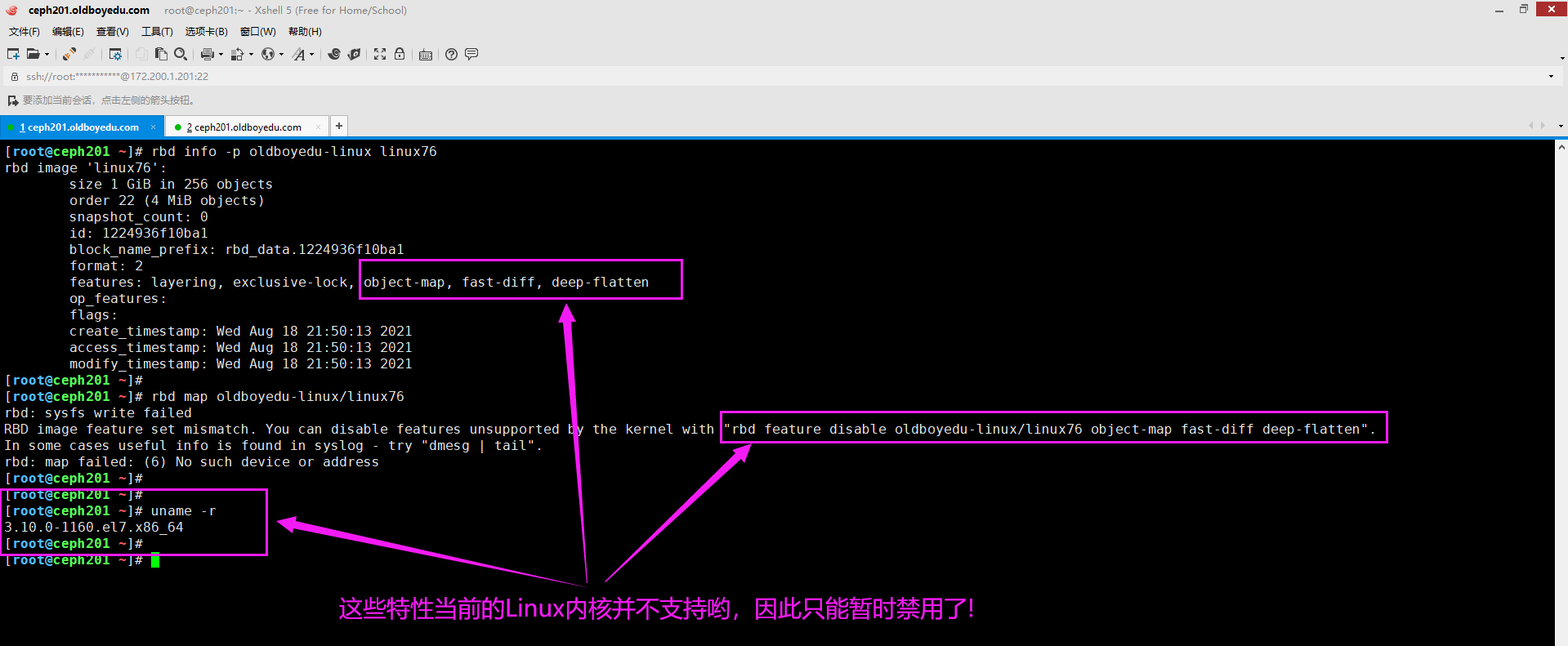
10.pkg_resources.DistributionNotFound: The 'six' distribution was not found and is required by ceph
报错原因:
缺少"python36-six"依赖包.
解决方案:
[root@ceph201 ~/ceph-rpm]# scp python36-six-1.14.0-3.el7.noarch.rpm python-six-1.9.0-2.el7.noarch.rpm ceph204:~
温馨提示:
将ceph201节点上安装的软件包拷贝过去安装即可。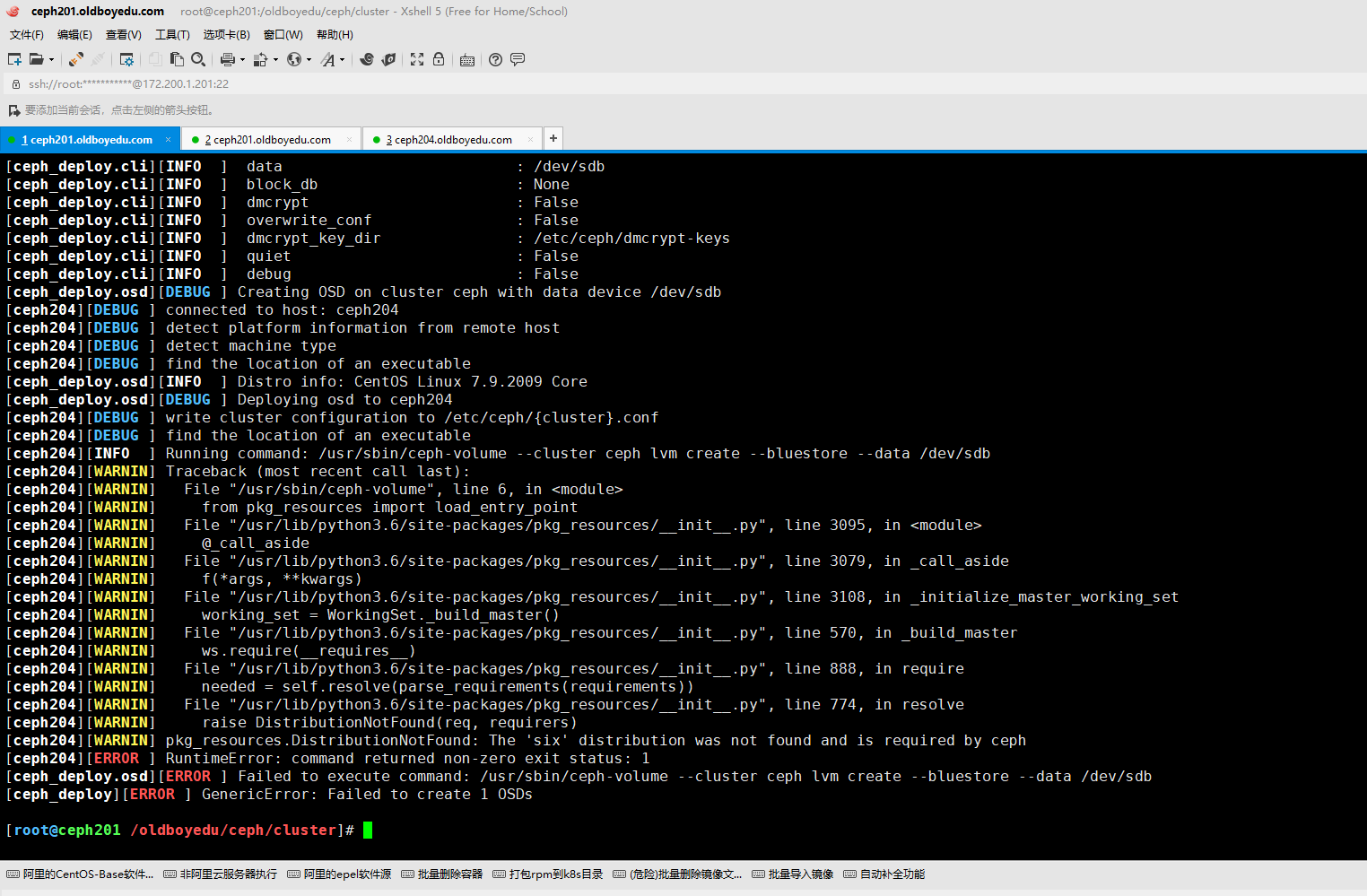
11.pkg_resources.DistributionNotFound: The 'pyyaml' distribution was not found and is required by ceph
报错原因:
缺少"python36-PyYAML"依赖包.
解决方案:
scp python36-PyYAML-3.13-1.el7.x86_64.rpm ceph204:~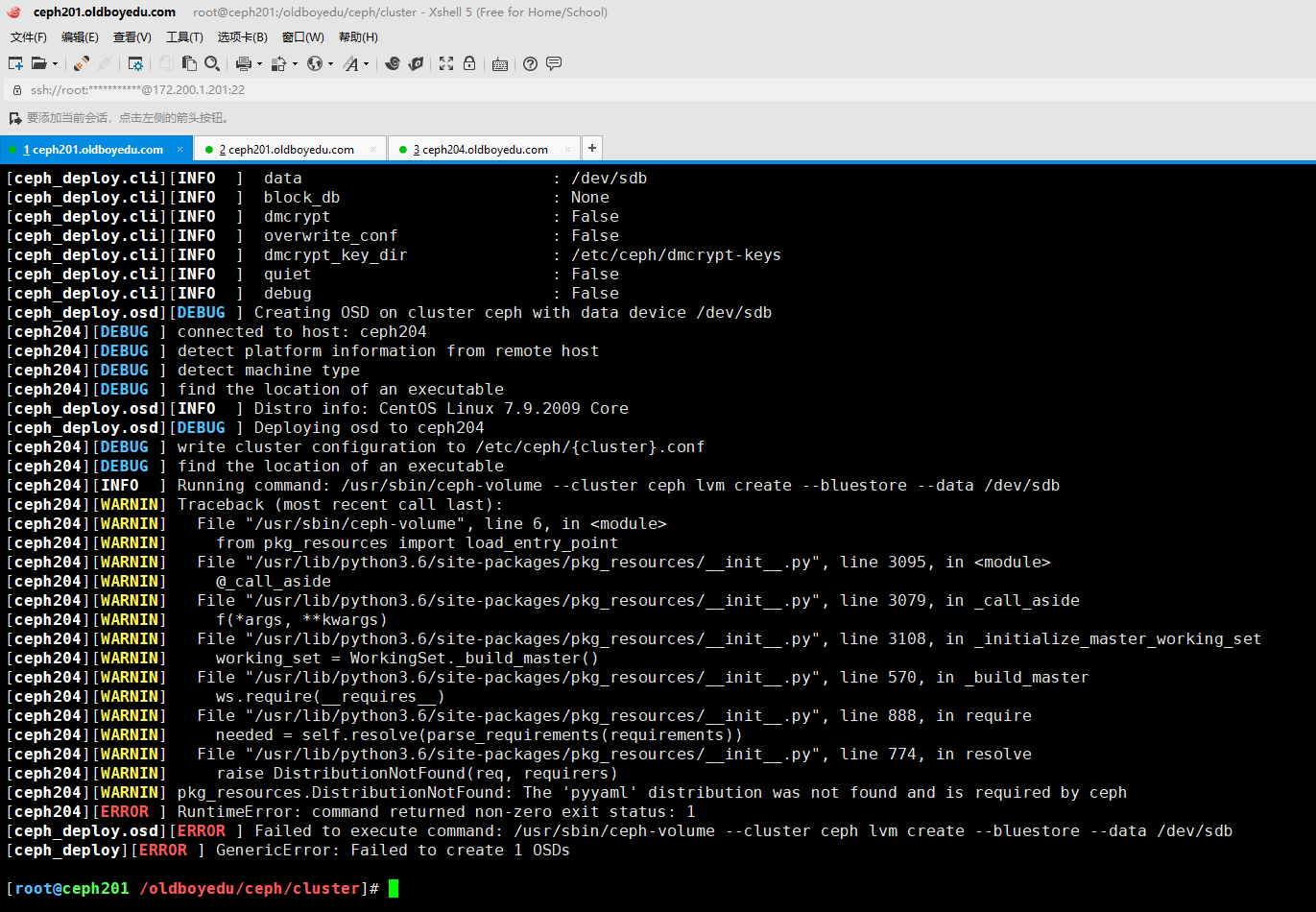
12.[ceph_deploy][ERROR ] ConfigError: Cannot load config: [Errno 2] No such file or directory: 'ceph.conf'; has ceph-deploy new been run in this directory?
报错原因:
如下图所示,当前目录缺少ceph集群的配置文件,即 'ceph.conf'。
解决方案:
进入到之前管理ceph集群的目录即可,"cd /oldboyedu/ceph/cluster"。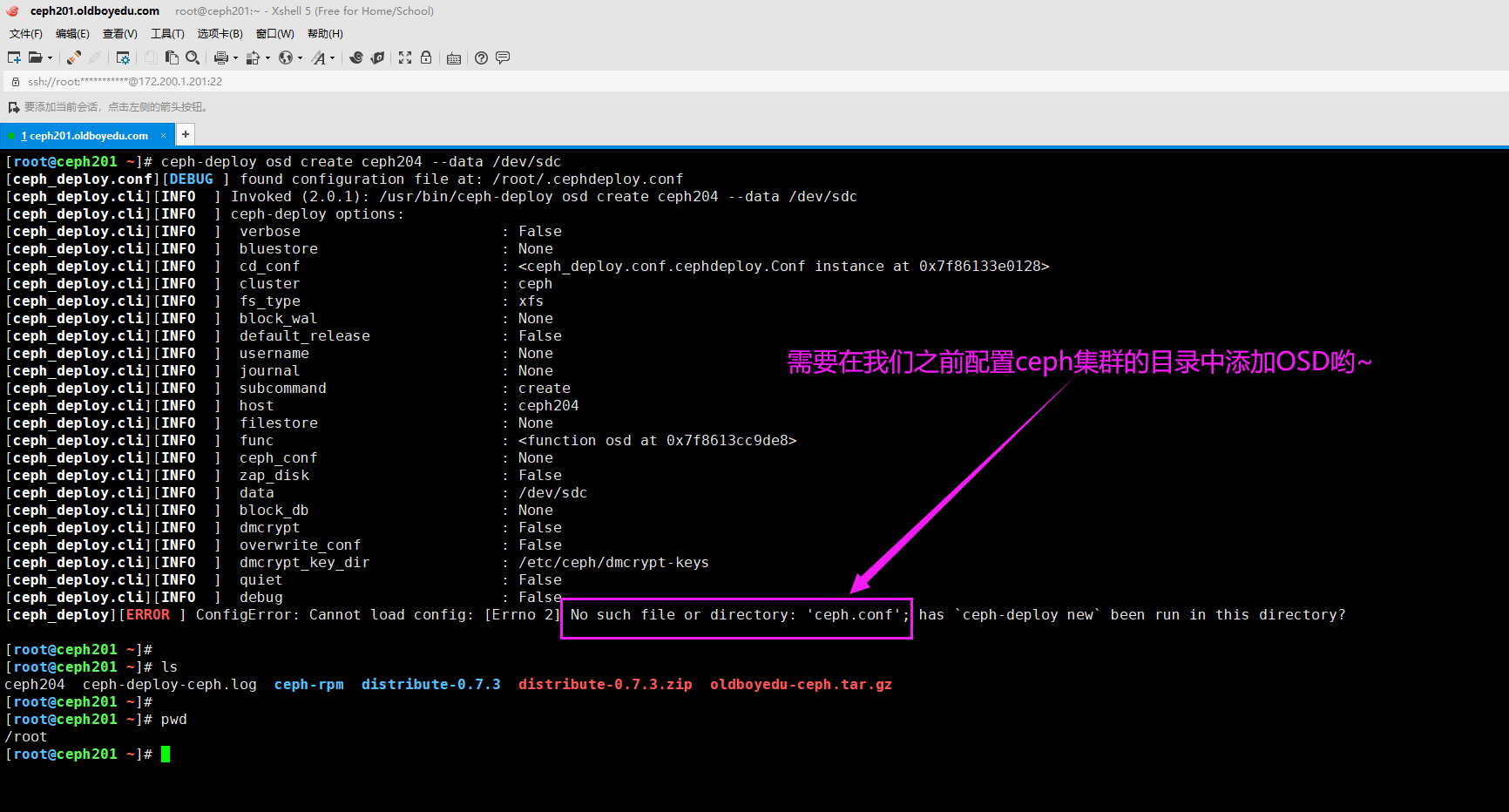
13.OSD DNE状态处理
问题原因:
删除osd的时候,如果没有在crush中删除,osd可能会出现DNE的状态。
osd DNE状态清楚方法:
ceph osd crush remove osd.id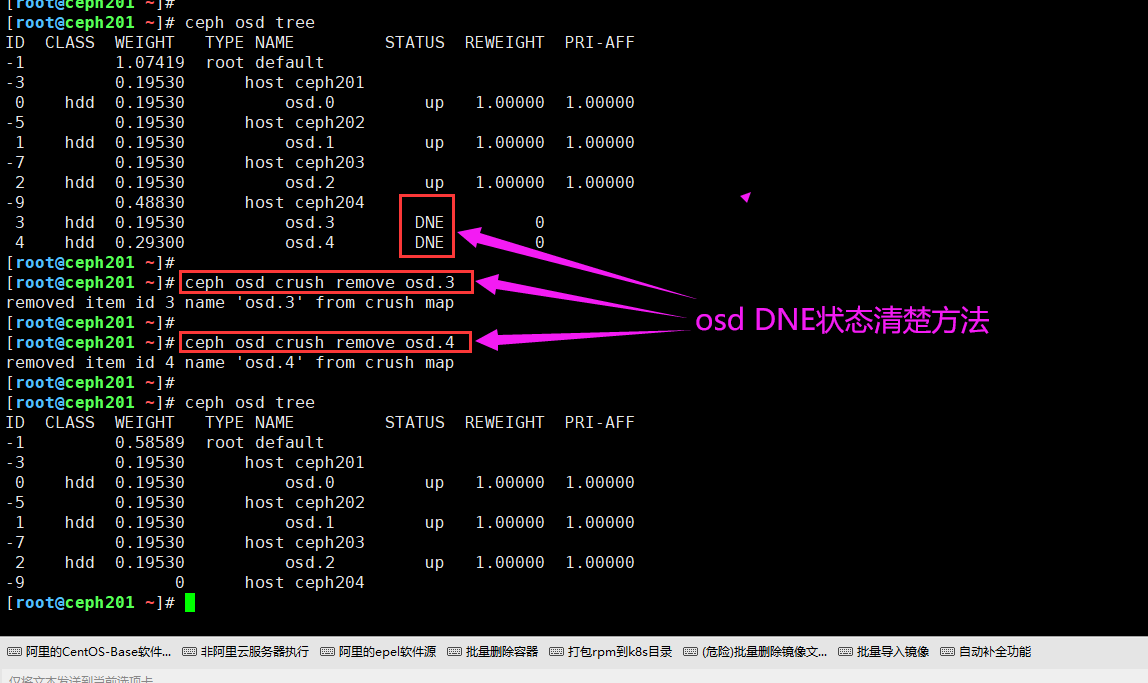
14.Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock'
报错原因:
MySQL服务没有启动。
解决方案:
/etc/init.d/mysql start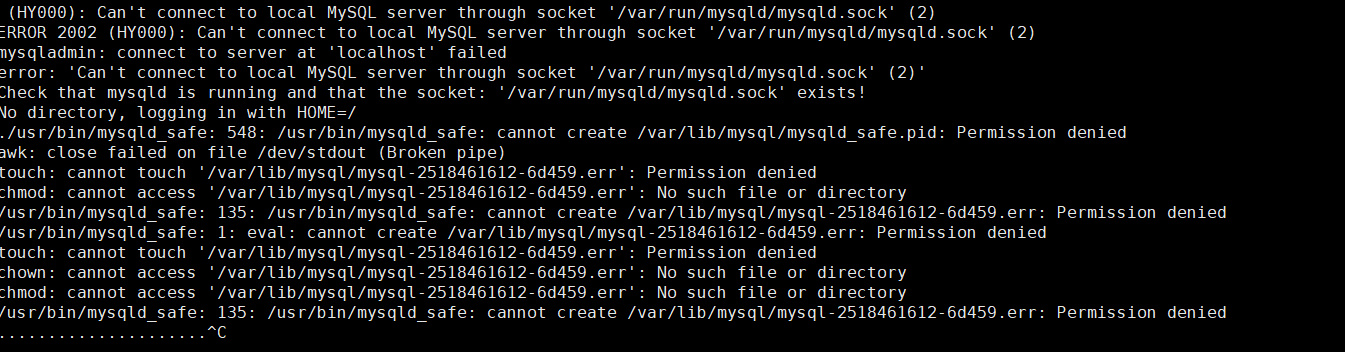
15.Can't create/write to file '/var/lib/mysql/is_writable' (Errcode: 13 - Permission denied)
报错原因:
如下图所示,无法在该目录创建写入权限。
解决方案:
我们可以直接将“/var/lib/mysql”目录权限改为777观察是否可以正常写入。
温馨提示:
我这里之所以报错,是因为我将ceph的存储卷"po.spec.volumes.rbd.readOnly"的值设置为true。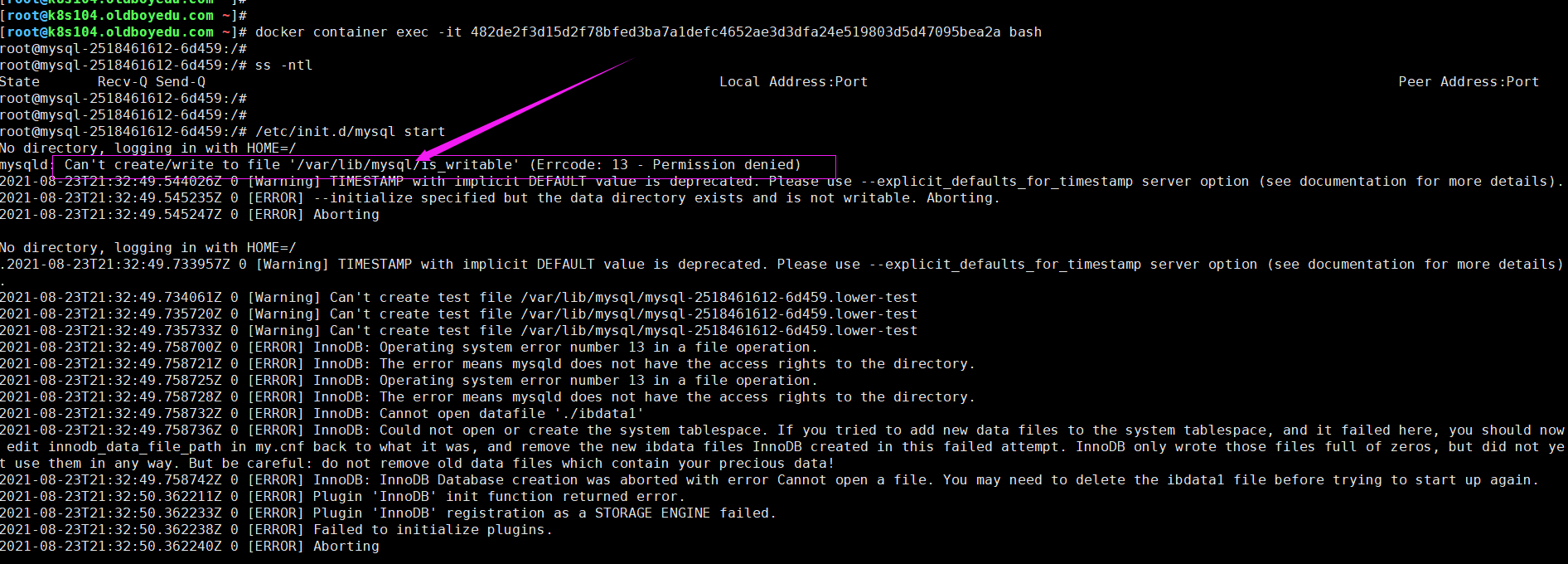
16.Error:java.sql.SQLException: null, message from server: "Host '172.18.36.0' is not allowed to connect to this MySQL server"
问题原因:
无权限访问数据库。
解决方案:
CREATE USER root IDENTIFIED BY '123456';
GRANT ALL ON *.* TO 'root';
17.OSD count 2 < osd_pool_default_size 3
问题原因:
OSD数量不足3块。
解决方案:
扩容OSD的数量大于等于3块设备即可。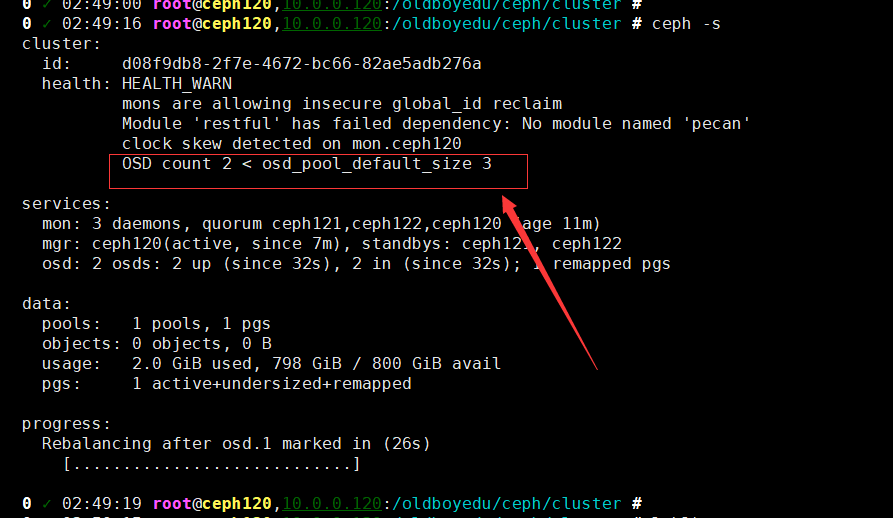
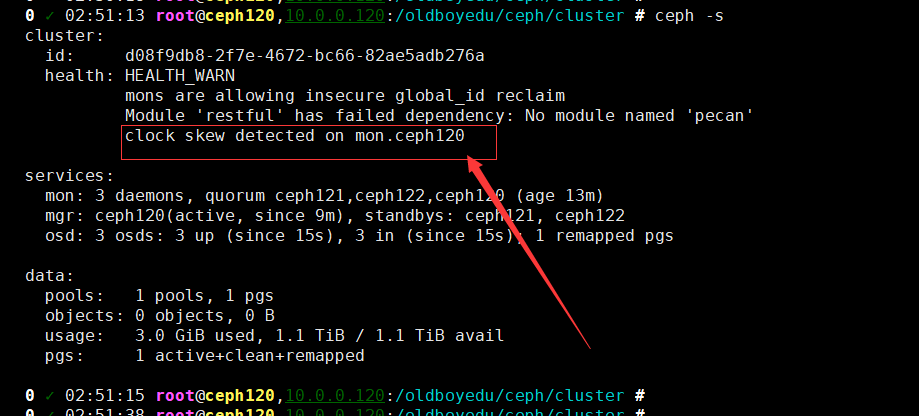
18.clock skew detected on mon.ceph120
问题原因:
集群时间不正常。
解决方案:
(1)安装chrony服务
yum -y install chrony
(2)备份默认配置文件
mv /etc/chrony.conf /etc/chrony.conf-bak
(3)创建配置文件
vi /etc/chrony.conf
iserver ceph120 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 10.0.0.0/8
local stratum 10
logdir /var/log/chrony
(4)客户端配置
mv /etc/chrony.conf /etc/chrony.conf-bak
vi /etc/chrony.conf
iserver ceph120 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
logdir /var/log/chrony
(5)将chrony服务设置为开启自启动
systemctl start chronyd && systemctl enable chronyd
19. pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
错误原因:
池删除功能已禁用,需要将"mon_allow_pool_delete"这个参数开启
解决方案:
ceph config set mon mon_allow_pool_delete true20.rbd: error opening default pool 'rbd'
错误原因:
不存在"rdb"这个池的名称
解决方案:
查看镜像时,需要我们手动指定池名称,例如""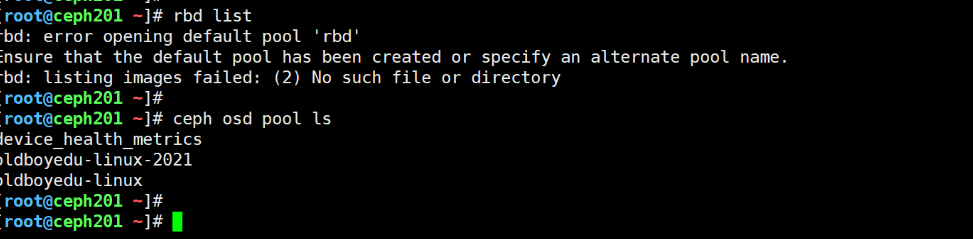
21.admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
问题原因:
获取命令说明时出现异常。
解决方案:
(1)所有节点执行:"rm -f /etc/ceph/ceph.conf && pkill ceph"
(2)在重新执行"ceph-deploy new --public-network 10.0.0.0/24 ceph120 ceph121 ceph122 "
(3)ceph-deploy config push ceph121 ceph122
......(继续后续的操作即可)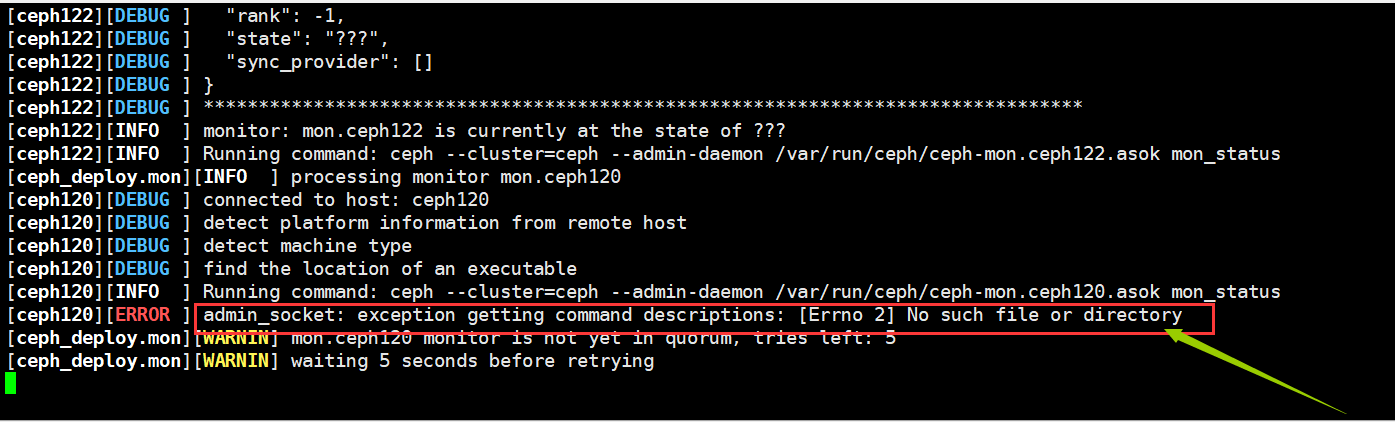
22.Some monitors have still not reached quorum:
问题原因:
mon节点无法互联,但ceph-mon进程是正常存在的。
解决方案:
暂时无解,网友说主机名异常或者防火墙异常并非我这里的情况!只能恢复快照从新来一遍,也可以直接使用我提供的软件包!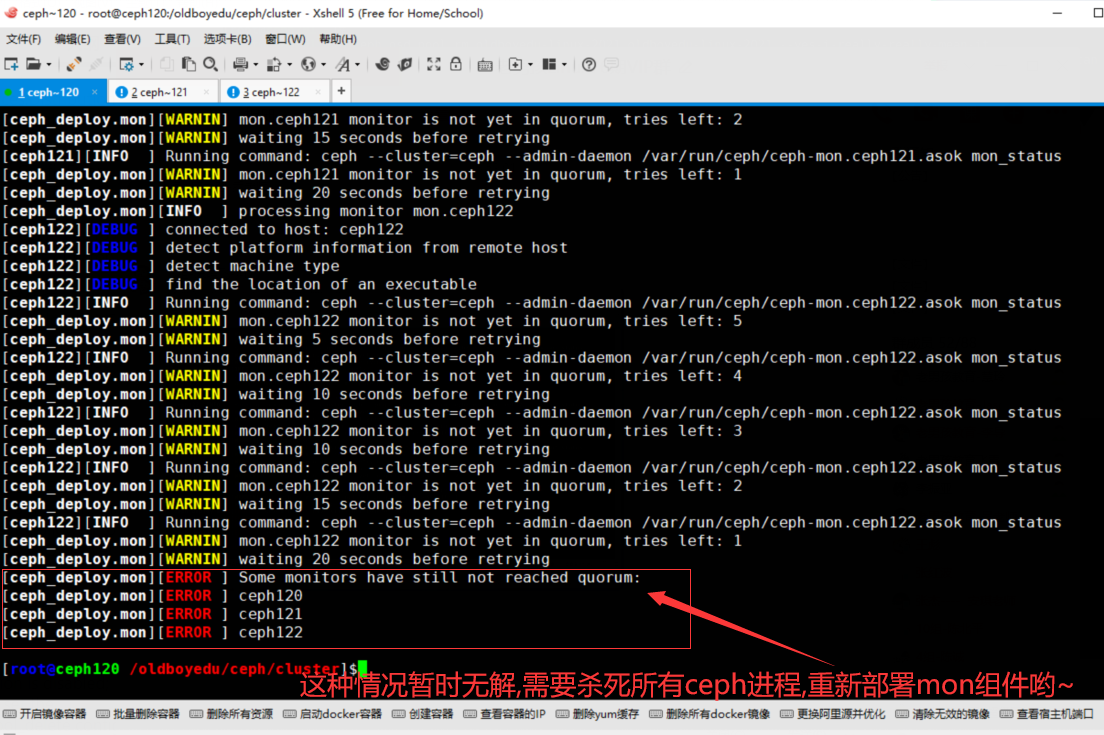
23.Error EPERM: WARNING: this will PERMANENTLY DESTROY all data stored in pool oldboyedu-linux76-2021. If you are ABSOLUTELY CERTAIN that is what you want, pass the pool name twice, followed by --yes-i-really-really-mean-it.
问题原因:
这是官方警告咱们,删除存储池,意味着该池的数据将全部被删除,如果确定要这样做,要求咱们将存储池传递两次.
解决方案:
将存储池传递两次,并添加"--yes-i-really-really-mean-it"这个选项.
24.Error ERANGE: pg_num 500 size 3 would mean 1503 total pgs, which exceeds max 1250 (mon_max_pg_per_osd 250 * num_in_osds 5)
问题原因:
超出了CEPH集群存储PGS的最大上限.
一个集群的PG数量上限并不固定,他取决于所有的存储池的PG副本总数,这个总数不能超过PGS上限!
解决方案:
创建存储池时,指定的pg数量要符合集群的pg最大承受力度.
温馨提示:
(1)集群存储池的pg数量上限取决于"mon_max_pg_per_osd" * "num_in_osds";
(2)默认情况下,每个OSD设备的最大pg数量为250,变量为"mon_max_pg_per_osd";
(3)集群的osd数量变量为"num_in_osds";
25.rbd: error opening default pool 'rbd' Ensure that the default pool has been created or specify an alternate pool name.
问题原因:
如果不指定存储池,创建镜像时默认使用的存储池为"rbd",但ceph并没有rbd存储池.
解决方案:
方案1: 创建rbd存储池
方案2: 指定其他的存储池,使用"-p/--pool"选项指定存储池即可.
26.No space left on device
问题原因:
目标设备上没有足够的空间.
解决方案:
扩容镜像大小即可,参考笔记即可.